An Analysis of the Automatic Bug Fixing Performance of ChatGPT(ChatGPT在Bug自动修复的性能分析)
摘要
- evaluate ChatGPT on the standard bug fixing benchmark set, QuixBugs, and compare the performance with the results of several other approaches reported in the literature.
在标准bug修复基准集Quixbug上评估ChatGPT,并将其性能与文献中报道的其他几种方法的结果进行比较。 - ChatGPT’s bug fixing performance is competitive to the common deep learning approaches CoCoNut and Codex and notably better than the results reported for the standard program repair approaches.
ChatGPT的bug修复性能与常见的深度学习方法CoCoNut和Codex相比具有竞争力,并且明显优于标准程序修复方法报告的结果。 - ChatGPT offers a dialogue system through which further information, e.g., the expected output for a certain input or an observed error message, can be entered. By providing such hints to ChatGPT, its success rate can be further increased
ChatGPT提供了一个对话系统,通过该系统可以输入进一步的信息,例如,某个输入的预期输出或观察到的错误信息。通过向ChatGPT提供这些提示,可以进一步提高其成功率。
动机
- The bug fixing performance of ChatGPT is so far unclear.
方法
- first ask ChatGPT for bug fixes for the selected benchmarks and manually check whether the suggested solution is correct or not.
首先询问ChatGPT对所选基准测试的bug修复,并手动检查建议的解决方案是否正确。 - study and categorize ChatGPT’s answers to gain a deeper understanding of its behavior.
研究和分类ChatGPT的答案,以获得更深入地了解它的行为。 - provide a small hint to the model (e.g., a failing test input with an error it produces) to see if it improves ChatGPT’s fix rate.
为模型提供了一个小提示(例如,一个失败的测试输入并产生一个错误),看看它是否提高了ChatGPT的修复率。
对于QuixBugs中的40个基准测试问题中的每一个,使用错误的Python代码,删除所有包含的注释,并询问ChatGPT代码是否包含bug以及如何修复它。对于每个基准测试问题,向ChatGPT发出几个独立的请求,并手动检查给定的答案是否正确。通过对每个查询使用相同的格式来标准化我们的过程。

expect from ChatGPT an answer that addresses the bug in line 7, where n ˆ= n - 1 should be replaced with n &= n - 1, either with a response containing the complete code snippet with the fixed bug (correctly addressed) or by
giving an exact and correct description how to change the affected code lines.
结果
对比结果
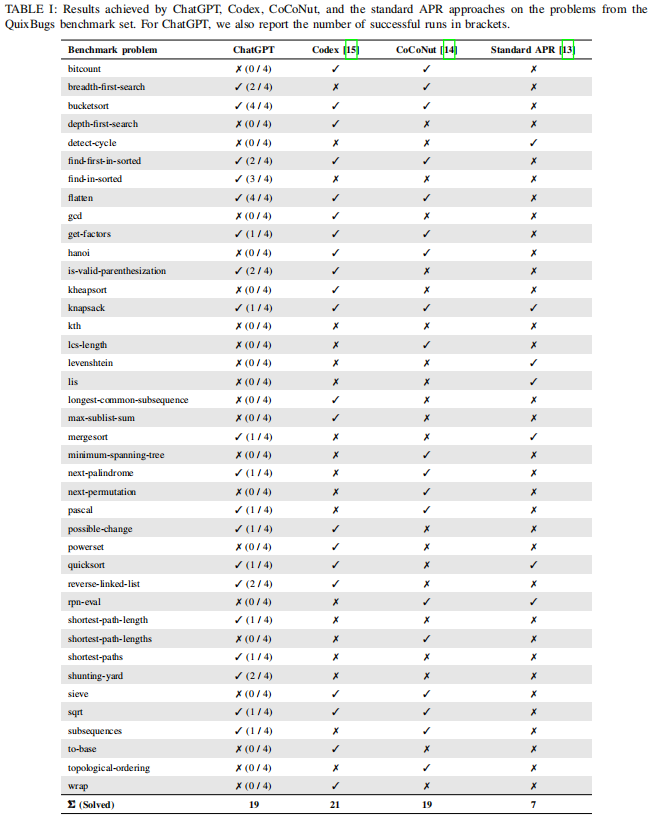
a checkmark (✓) indicates that a correct answer was given in at least one of the four runs for a benchmark problem. A cross (✗) indicates that no correct answer was given in any of the runs.
- for some problems, ChatGPT suggests a complete re-implementation which is then bug-free.
- these are probably no real bug fixes, since the introduced bug is not localized. We assume that ChatGPT simply reproduced what it has learned here.
- Furthermore, we do not count a bug as fixed if additional changes suggested by ChatGPT introduce new errors that prevent the program from running properly.
对回答分类
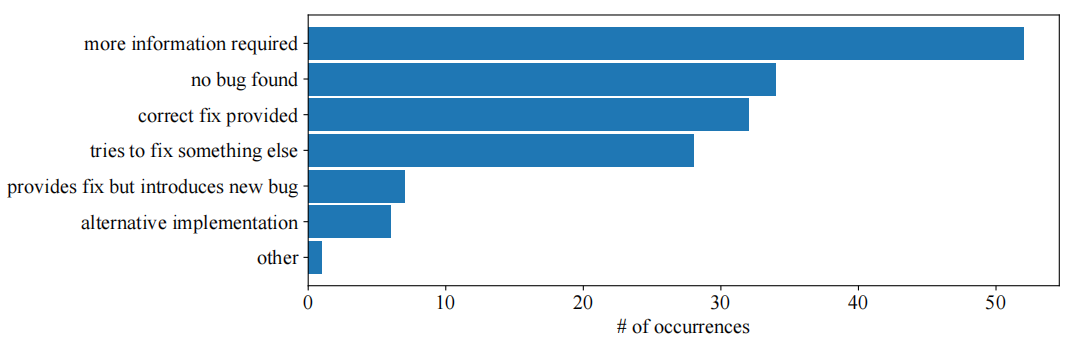

与其对话
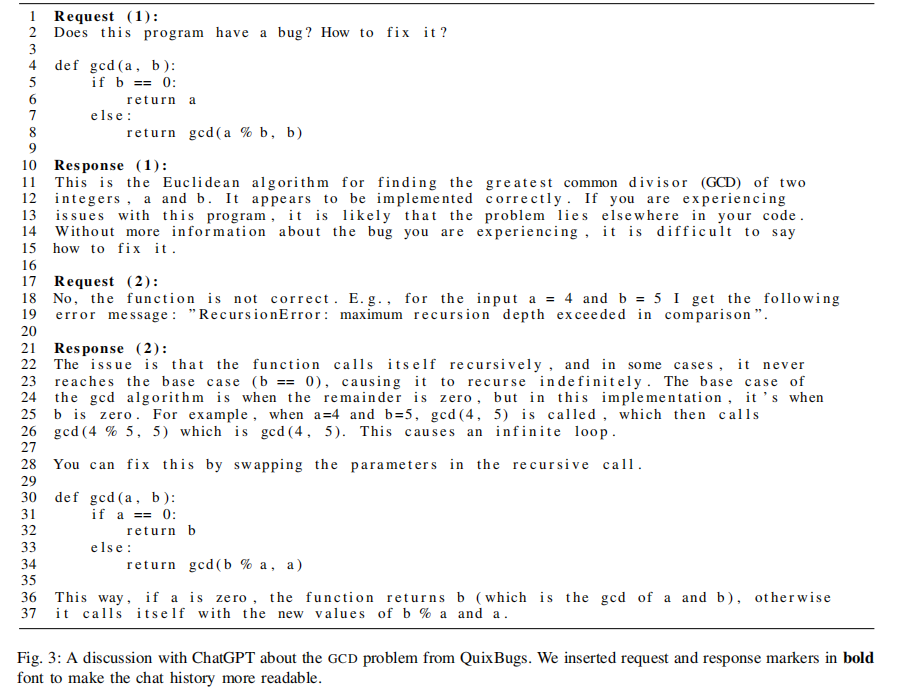
give ChatGPT an exact input example and the resulting error message from Python (lines 17–19)
- human input can be of much help to an automated APR system, with ChatGPT providing means to do so.
启发
- 将chatGPT在某一基准数据集下的推荐性能与其他模型进行比较,分析推荐任务方面的性能
- 突出其对话的特性,使其在后续follow-up中性能有所提高,如本文与其他模型相比而言平平无奇,但加入和系统对话,为chatgpt提供更多信息或提示后,优越性立马体现出来。
Original link: http://example.com/2023/02/21/An-Analysis-of-the-Automatic-Bug-Fixing-Performance-of-ChatGPT/
Copyright Notice: 转载请注明出处.