flask+vue+mysql前后分离项目每日记录
Day1
创建项目
- conda创建虚拟环境:flask-vue 安装第三方库:requirement.txt
- 前端用的vue-admin-template-master,在此基础上改造开发
- 新建mysql数据库movies
flask配置数据库
创建config.py 文件,配置数据库
SQLALCHEMY_DATABASE_URI = "mysql://root:123456@localhost:3306/movies"
SQLALCHEMY_COMMIT_ON_TEARDOWN = True
SQLALCHEMY_TRACK_MODIFICATIONS = False
设计user表和movie表(以user表为例)
class Users(db.Model):
__tablename__ = 'user'
userid = db.Column(db.Integer, primary_key=True, autoincrement=True)
name = db.Column(
db.String(255),
nullable=False,
)
...
created_on = db.Column(
db.DateTime,
nullable=False,
)
enable = db.Column(
db.Boolean,
default=True,
nullable=False,
)
def set_password(self, password: str):
self.password = generate_password_hash(password, method='sha512')
def check_password(self, password: str):
return check_password_hash(self.password, password)
def __repr__(self):
return '<User {}>'.format(self.name)
@classmethod
def add(cls, user):
db.session.add(user)
db.session.commit()
命令行一次性创建所有表
python run.py create_db //注意切换到项目的conda环境
movie数据
- MovieLens Latest Datasets
- ml-latest-small.zip
- Small: 100,000 ratings and 3,600 tag applications applied to 9,000 movies by 600 users. Last updated 9/2018.
通过爬虫从IMBD网站中获取电影的详细信息和封面图片。参考链接 这里直接使用其爬好的最终csv文件,info.csv
mysql中导入csv,注意字段的长度!longtext > text > varchar(255)
Day2
用户登录
def post(self):
parser = reqparse.RequestParser()
parser.add_argument('username',
required=True,
nullable=False,
type=str,
location='json',
help="username is required")
parser.add_argument('password',
required=True,
nullable=False,
type=str,
location='json',
help="password is required")
args = parser.parse_args()
username = args.get('username')
password = args.get('password')
user = Users.query.filter_by(name=username).first()
if user is None:
error = 'User not exists'
elif user.check_password(password=password):
access_token = create_access_token(
identity=user.userid, expires_delta=datetime.timedelta(days=1))
return jsonify({'access_token': access_token})
else:
error = 'user and password not match'
return error, 401
username与password匹配则返回jwt_token;前端发送请求需携带jwt_token,例如获取用户信息显示在页面头部位置。
@jwt_required()
def get(self):
userid = get_jwt_identity()
user = Users.query.filter_by(userid=userid).first()
return jsonify({
'username':
user.name,
'email':
user.email
})
postman测试
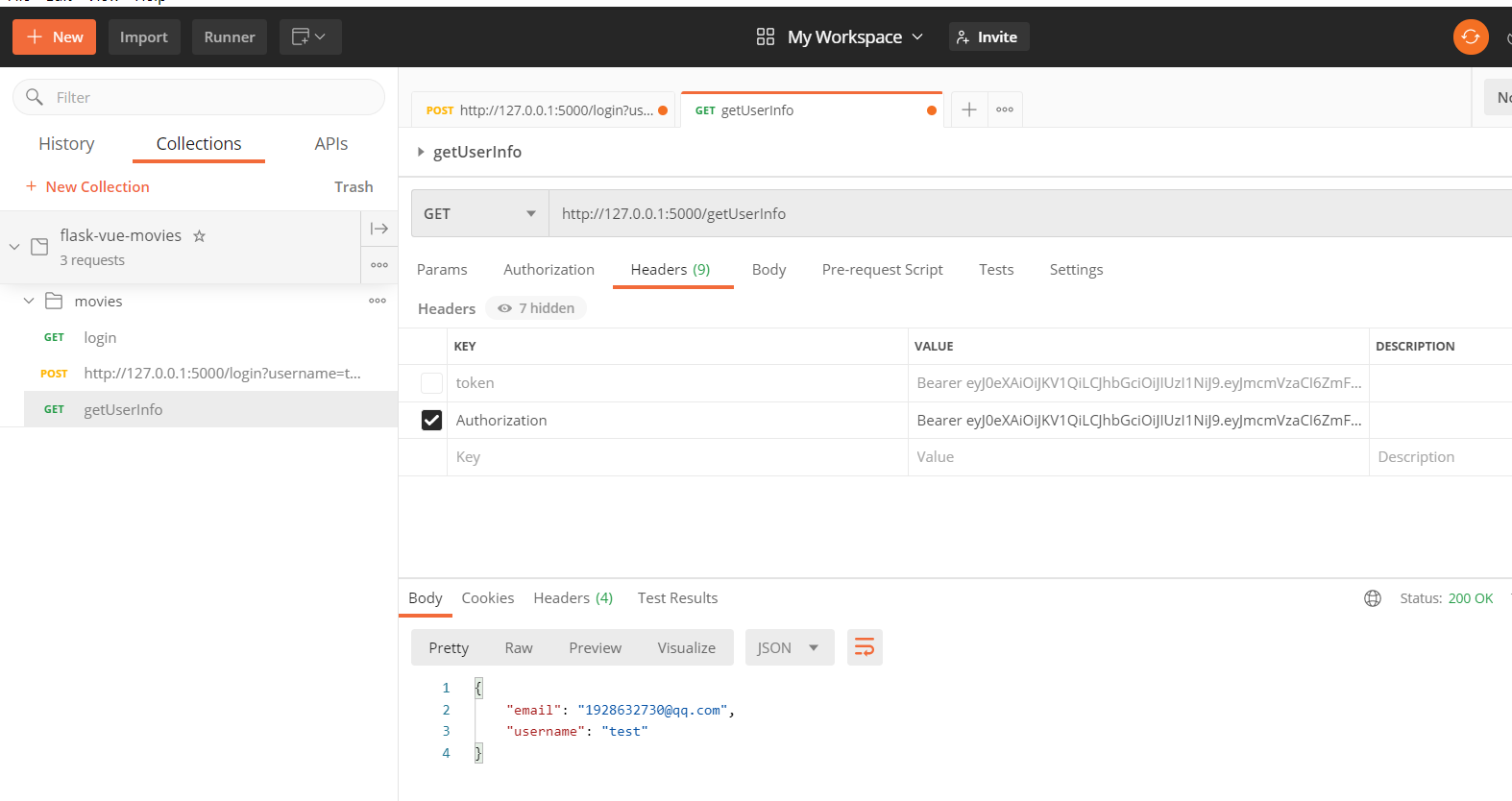
如果post请求参数是json需在boby里写。
遇到的问题
我把它定义为Flask和Vue在使用JWT过程中的跨域问题。因为使用了flask_cros中间件,其他的方法都是不存在跨域问题的,单单在前端携带token发送请求时报了错。如图:
后端控制台显示丢失head信息。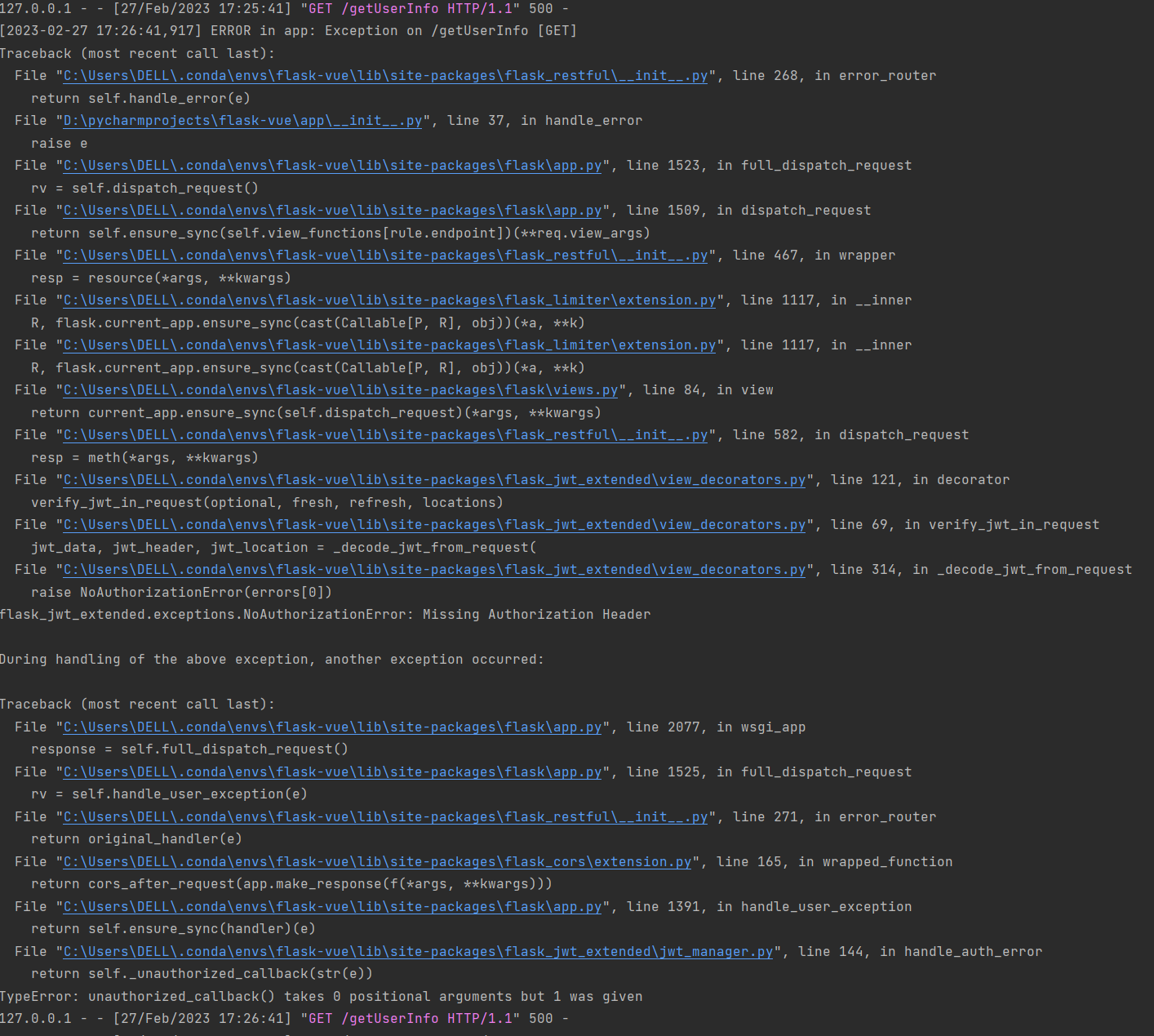
但postman测试,如果’Authorization’字段为’Bearer ‘ + token,则可以请求成功。于是把前端的request拦截器中携带token发送请求时也加上’Bearer ‘的头部信息,则成功解决。
查阅资料:在token前面加上Bearer是一种规范, W3C 的 HTTP 1.0 规范,Authorization 的格式是: Authorization: <type> <authorization-parameters>
Bearer 常见于 OAuth 和 JWT 授权。
明天目标
- 用户注册
- 用户首页设计
- 系统整体功能模块设计
Original link: http://example.com/2023/02/23/flask-vue-mysql前后分离项目每日记录/
Copyright Notice: 转载请注明出处.