PyTorch深度学习实践学习记录
0 配置环境
conda环境:’pytorch’
conda create -n pytorch python=3.9GPU:NVIDIA GeForce GTX 1050 Ti
安装cuda
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=10.2测试一下
import torch torch.cuda.is_available() //成功则返回True安装pycharm和jupyter notebook
dir()和help()函数
1 加载数据
- Dataset 提供一种方式去获取数据及其label
如何获取每一个数据及其label?
def __init__(self, root_dir, label_dir) def __getitem__(self, idx):
三种数据集结构 1.label是文件夹名 2.label在txt文件中 3.label包含在文件名中
告诉我们总共有多少的数据?
def __len__(self): return len(self.img_path_list)
Dataloader 为后面的网络提供不同的数据形式
test_loader = DataLoader(dataset=test_data, batch_size=64,shuffle=True, num_workers=0) writer = SummaryWriter("dataloader_logs") for epoch in range(2): step = 0 for data in test_loader: imgs, targets = data writer.add_images("epoch: {}".format(epoch), imgs, step) step = step + 1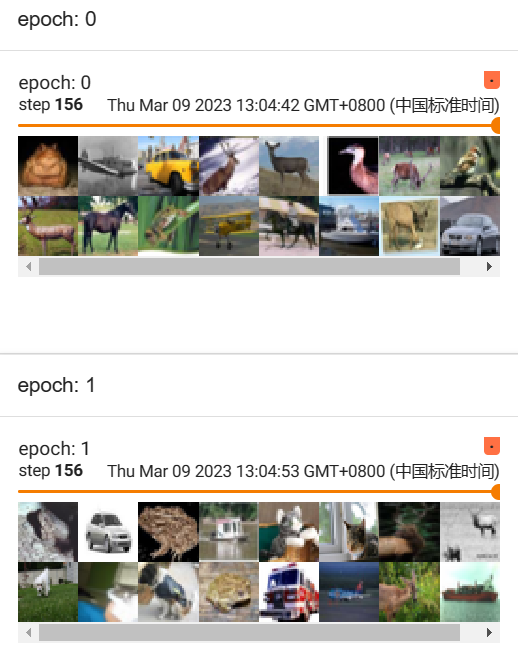
2 tensorboard的使用
启动tensorboard
tensorboard --logdir=logs --port=6007
example:
writer = SummaryWriter("logs")
image_path = "dataset/train/ants/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
writer.add_image("train", img_array, 1, dataformats='HWC')
# y = 2x
for i in range(100):
writer.add_scalar("y=2x", 2*i, i)
writer.close()
3 transform的使用
关注输入和输出类型,多看官方文档,关注方法需要的参数
ToTensor()
tensor_trans = transforms.ToTensor() tensor_img = tensor_trans(img)Normalize
trans_norm = transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) img_norm = trans_norm(tensor_img)Resize
trans_resize = transforms.Resize((256, 256))Compose
trans_resize_2 = transforms.Resize(256) trans_compose = transforms.Compose([trans_resize_2, tensor_trans]) img_resize_2 = trans_compose(img)RandomCrop
trans_random = transforms.RandomCrop(256) trans_compose_2 = transforms.Compose([trans_random, tensor_trans])
4 dataset 和 transform 一起使用
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train_set = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10",transform=dataset_transform, train=True, download=True)
test_set = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10", transform=dataset_transform, train=False, download=True)
5 Neural Network
1 nn.Module
Base class for all neural network modules
example:
import torch.nn as nn
import torch.nn.functional as F
class Model(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
2 nn.Conv2d
Parameters:
in_channels (int) – Number of channels in the input image
out_channels (int) – Number of channels produced by the convolution
kernel_size (int or tuple) – Size of the convolving kernel
stride (int or tuple, optional) – Stride of the convolution. Default: 1
padding (int, tuple or str, optional) – Padding added to all four sides of the input. Default: 0
padding_mode (str, optional) – ‘zeros’, ‘reflect’, ‘replicate’ or ‘circular’. Default: ‘zeros’
dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1 空洞卷积
groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
bias (bool, optional) – If True, adds a learnable bias to the output. Default: True

3 nn.MaxPool2d
又叫下采样, nn.MaxUnpool2d 为上采样
Parameters:
kernel_size (Union[int, Tuple[int, int]]) – the size of the window to take a max over
stride (Union[int, Tuple[int, int]]) – the stride of the window. Default value is kernel_size
padding (Union[int, Tuple[int, int]]) – Implicit negative infinity padding to be added on both sides
dilation (Union[int, Tuple[int, int]]) – a parameter that controls the stride of elements in the window
return_indices (bool) – if True, will return the max indices along with the outputs. Useful for torch.nn.MaxUnpool2d later
ceil_mode (bool) – when True, will use ceil instead of floor to compute the output shape

4 Non-linear Activations
nn.ReLU
nn.Sigmoid
效果:
5 nn.Sequential
example:
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)

使用已有模型开发
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
vgg16预训练是在ImagNet上,但ImagNetl类别是1000个,Cifar10类别是10个
方案1:add_module添加一个线性层
vgg16_true.classifier.add_module('add_linear', nn.Linear(1000, 10))
方案2:直接修改某一层
vgg16_false.classifier[6] = nn.Linear(4096, 10)
模型的保存与导入(两种)
torch.save(vgg16_false, “vgg16_method1.pth”)
model = torch.load(“vgg16_method1.pth”)(recommend) smaller 通过字典形式存储参数
torch.save(vgg16_false.state_dict(), "vgg16_method2.pth") vgg16_false.load_state_dict(torch.load("vgg16_method2.pth"))
完整的训练流程(套路)
准备数据集
dataloader加载数据集
搭建网络模型
创建网络模型实例
定义损失函数
定义优化器
设置网络训练的参数
开始训练
验证模型
最后保存模型
tensorboard训练结果展示
# 准备训练数据集 train_data = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10", train=True, transform=torchvision.transforms.ToTensor(),download=True) # 准备训练数据集 test_data = torchvision.datasets.CIFAR10(root="./dataset_CIFAR10", train=False, transform=torchvision.transforms.ToTensor(),download=True) print("训练数据集的长度为:{}".format(len(train_data))) # 利用DataLoader来加载数据集 train_dataloader = DataLoader(train_data, batch_size=64) test_dataloader = DataLoader(train_data, batch_size=64) # 创建网络模型 model = Model() # 损失函数 loss_fn = nn.CrossEntropyLoss() # 优化器 learning_rate = 1e-2 optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate) # 设置训练网络的一些参数 # 记录训练的次数 total_train_step = 0 # 记录测试的次数 total_test_step = 0 # 训练的轮数 epoch = 10 # 添加tensorboard writer = SummaryWriter("train_logs") for i in range(epoch): print("--------第 {} 轮训练开始--------".format(i+1)) # 训练步骤 # model.train() # 适用于有dropout层,Norm层 for data in train_dataloader: imgs, targets = data outputs = model(imgs) loss = loss_fn(outputs, targets) # 优化器优化模型 optimizer.zero_grad() loss.backward() optimizer.step() total_train_step = total_train_step + 1 if total_train_step % 100 == 0: print("训练次数:{},loss:{}".format(total_train_step, loss.item())) writer.add_scalar("train_loss", loss.item(), total_train_step) # 测试步骤 # model.eval() # 适用于有dropout层,Norm层 total_test_loss = 0.0 with torch.no_grad(): for data in test_dataloader: imgs, targets = data outputs = model(imgs) loss = loss_fn(outputs, targets) total_test_loss += loss.item() accuracy = (outputs.argmax(1) == targets).sum() total_accuracy = total_accuracy + accuracy print("整体测试集上的Loss:{}".format(total_test_loss)) print("整体测试集上的accuracy:{}".format(total_accuracy/len(test_data))) writer.add_scalar("test_loss", total_test_loss, total_test_step) writer.add_scalar("test_accuracy", total_accuracy/len(test_data), total_test_step) total_train_step += 1 # 保存模型 # torch.save(model, "model_{}.pth".format(i)) # print("模型已保存") writer.close()
使用GPU训练
对模型、损失函数、要训练和验证数据处理,两种方式:
- .cuda()
- 先定义device = torch.device(“cuda”),然后对模型、损失函数、数据使用.to(device)
可使用google.colab使用免费的计算资源
验证的流程
image_path = ""
image = Image.open(image_path)
transform = torchvision.transforms.Compose([torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()])
image = transform(image)
# 载入网络模型
# 如果是gpu上训练的结果在cpu上载入,要加map_location=torch.device('cpu')
model = torch.load("model_29_gpu.pth", map_location=torch.device('cpu'))
image = torch.reshape(image, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(image)
print(output)
print(output.argmax(1))
Original link: http://example.com/2023/02/28/pytorch-study/
Copyright Notice: 转载请注明出处.