Some ideas
对话推荐
- Conversation Module:对话模块,负责理解用户的自然语言反馈以及给出系统的文本答复
- Conversation Module:策略模块,根据当前状态做出如何回复的决定,是继续询问还是进行推荐
- Recommender Module:推荐模块,负责根据用户的偏好给出相应的推荐列表或者单个推荐结果
基于属性的对话推荐
更多地针对策略模块,希望在最短的交谈次数内实现尽可能精确的推荐。
单轮场景
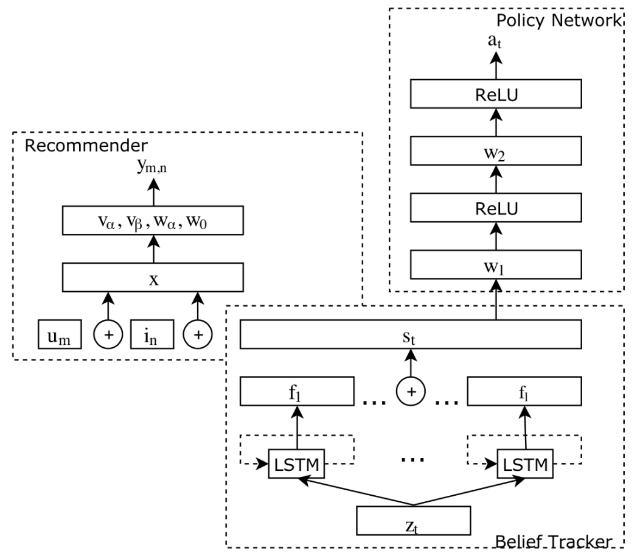
SIGIR 2018(CRM):Conversational Recommender System
- 动机:如何准确地理解用户的意图?如何实施序列化的决策并在每一步采取合适的行动?如何做个性化的推荐以最大化地提升用户的满意程度?
- 方法:提出三个模块分别解决上述三个问题。Belief Tracker + Policy Network + Recommender
- 对于一句话,利用n-gram词表转化为向量,LSTM 网络学习所有对话的隐含表示
- 推荐模块采用2-way FM二路因子分解机,输入为用户信息、物品信息和对话信息,输出为用户对物品的预测评分
- 策略模块,输入对话信息,简单的两层前馈神经网络,输出用户的动作预测 。利用强化学习中的 Policy Gradient 方法进行训练
多轮场景
WSDM 2020(EAR):Estimation–Action–Reflection: Towards Deep Interaction Between Conversational and Recommender Systems
- 动机:认为对话推荐应该采用多轮场景,系统能对一个用户进行多次推荐,并根据之前推荐的反馈改善后面的推荐
- 方法:加强对话模块和推荐模块的交互(What attributes to ask? When to recommend items? How to adapt to users’ online feedback?)
Estimation–Action–Reflection框架:- Estimation 模块完成推荐任务,FM + BPR
- Action 模块负责决策,基于强化学习训练,网络结构同CRM,更简单的奖励机制
- Reflection 模块以负反馈物品为负例构建新的损失函数项进一步训练
搜索剪枝
KDD 2022(CPR):Interactive Path Reasoning on Graph for Conversational Recommendation
- 动机:之前的工作都是用隐式的方法来利用用户在属性方面的反馈信息
- 方法:本文基于图机构(由用户、物品、属性三类节点构成),通过显式方法来利用用户喜欢的属性,删去了大量无关的候选物品。
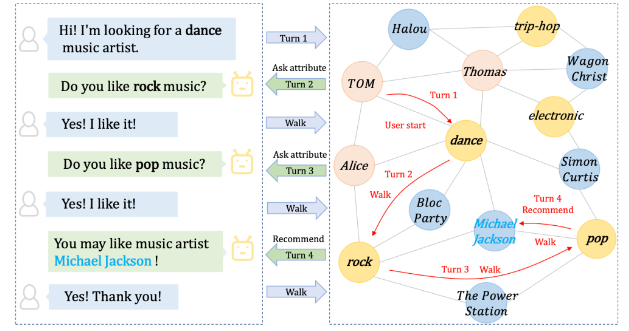
- 将决策的动作空间缩小为两个,询问or推荐
- 持久化地维护之前访问过的属性节点集合、询问用户时被予以否定的属性集合和候选物品集合。显式地利用用户的反馈信息确定了物品和属性的候选范围
- 在候选集合中进一步排序,与EAR类似
统一架构
SIGIR 2021(UNICORN):Unified Conversational Recommendation Policy Learning via Graph-based Reinforcement Learning
- 动机:过去基于属性的对话推荐系统工作总是将决策过程分到多个模块去完成,这对模型的可扩展性造成了影响
- 方法:将三个决策问题(询问还是推荐、询问什么、推荐什么)统一起来
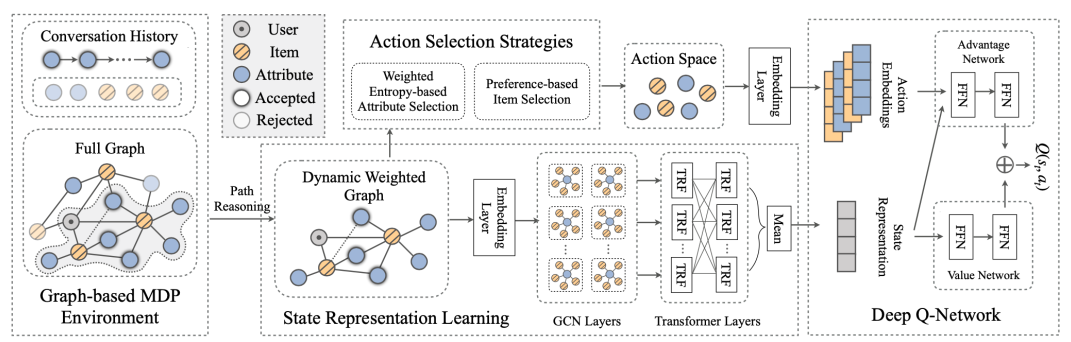
- Graph-based MDP Environment:基本上沿用了 CPR 构建的图上路径推理机制
- Graph-enhanced State Representation Learning:将当前对话状态表示成一个向量
- Action Selection Strategy:强化学习动作空间,两类动作(推荐和询问)各选 k1 和 k2 个,选择top-k1个物品推荐,选择top-k2个属性进行询问
- Deep Q-Learning Network:强化学习决策网络模块,输入是2中的对话状态向量和3中的k1 + k2个节点的embedding,采用DQN算法进行学习训练,输出是??
生成式对话推荐
更注重向用户提供流畅的对话体验,同时将推荐物品相关的信息融入到回复文本中,提高推荐的可解释性。
降噪协同
NeurIPS 2018(ReDial):Towards Deep Conversational Recommendations
- 构造了电影场景下的对话推荐数据集REDIAL(包含 6924 部电影、956 位用户、11348 个对话,平均每个对话由 18 个英文句子构成,并保证每个对话中至少提到 4 部电影,还包含语句的情感判断标签)
- 先按模块分别用更大的数据集训练,然后再一起端到端地用 REDIAL 训练
- 对话模块中,使用层次化的RNN结构HRED来编码对话,并采用了预训练的 Gensen 句子向量表示。HRED 得到对话的隐含向量表示之后,一方面会给情感分析 RNN 进行计算,一方面给 Switching Decoder 来将推荐结果融入到对话中,另外还能用于给 RNN 解码出回复语句
- 推荐模块中,采用降噪自编码器,同时利用了情感分析模块的计算结果进一步修正推荐结果
- 后续的工作基本上都不再利用情感标签
知识增强
EMNLP 2019(KBRD):Towards Knowledge-Based Recommender Dialog System
- 动机:ReDial当对话中没有提到物品时则无法向用户提供推荐结果
- 方法:引入知识图谱,从中抽取与 REDIAL 任务相关的子图,将上面的节点与 REDIAL 中的实体(包括电影实体和如导演、演员、影片类别等其他实体)进行对齐;R-GCN 学习图上实体的向量表示;采用自注意力机制来进行融合不同实体对应的 embedding,从而得到用户表示;最终通过向量内积来计算每个实体的得分;对话模块采用 Transformer 架构,并在最终生成的词汇分布上加上 Vocabulary Bias
- 对话模块获得的实体信息对推荐产生促进作用
- 推荐模块产生的用户embedding转化为Vocabulary Bias来促进对话生成
语义融合
KDD 2020(KGSF):Improving Conversational Recommender Systems via Knowledge Graph based Semantic Fusion
动机:过去的生成式对话推荐系统工作没能很好地处理文本信息,基于自然语言的表达与基于实体构建的用户偏好表示二者存在天然的语义差异
方法:通过互信息最大化的多知识图谱语义融合技术,打通不同类型信息之间的语义差异
- 实体信息方面,DBpedia 子图进行编码
- 词汇信息方面,与 ConceptNet 中的词汇对齐
- 使用互信息最大化算法来对两类 embedding 进行预训练
- 对话模块,KGSF 修改了 Transformer 的内部结构,将用户或者说对话构造的实体矩阵、词汇矩阵通过多头自注意力机制逐步融入解码过程中
话题引导
COLING 2020(TGReDial):Towards Topic-Guided Conversational Recommender System
- 动机:缺乏主动的引导来将非推荐场景的对话转变为推荐场景的对话;由数据标注平台的工作人员对话来生成的对话推荐数据集难以捕捉现实世界场景丰富且复杂的情况
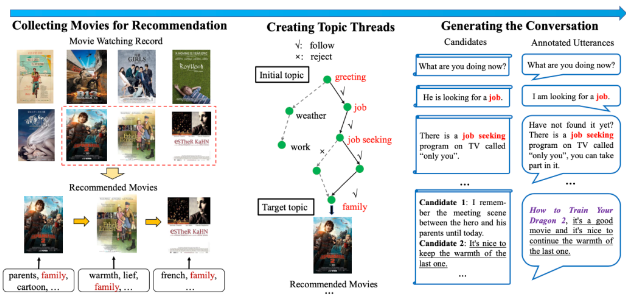
- 方法:
- 收集电影序列,对于某一用户可以从其观影记录中的电影构建若干子序列,其中每个序列的电影都有相同的话题标签
- 构建话题转移的通道,作者借助深度优先搜索算法,在知识图谱 ConceptNet 上找到一条从最初话题(greeting)到目标电影话题的转移路径
- 利用深度学习模型从话题生成对话文本,并进行人工修改和润色,以保证对话的流畅性
可控生成
EMNLP 2021(NTRD):Learning Neural Templates for Recommender Dialogue System
动机:不能总是将推荐结果精确且恰当地融入到生成的回复中;推荐结果总是在训练集中提到的物品,缺乏泛化性
方法:
- 将 KGSF 的对话模块改造为 Response Template Generator,具体做法是将数据集中的所有物品(电影)全部替换为特殊符号[ITEM],使得生成的对话不带具体的电影信息,而是一个个句子模板
- 构造一个物品选择器来填写模板中的[ITEM]槽,NTRD 使用堆叠的多头注意力函数来构造选择器。在这个堆叠的结构中逐步融入了模板词汇相关信息、模板的槽相关信息、推荐模块得到的候选物品相关信息
UCCR
User-Centric Conversational Recommendation with Multi-Aspect User Modeling
SIGIR 2022 以用户为中心的对话推荐系统
- 动机:现有方法本质上当前会话的建模,而忽略了用户建模。而本文发现用户历史会话和相似用户信息也可以很好地辅助用户兴趣建模,特别是在用户当前会话信息较少(冷启动)的场景下效果更佳。
- 方法:在历史会话建模部分,UCCR同时考虑了用户的实体偏好、语义偏好和消费偏好,从这三种偏好中提取有益于用户当前兴趣建模的信息;之后UCCR基于对比学习,学习不同用户当前/历史兴趣偏好之间的内在联系;在查找相似用户部分,UCCR考虑了用户兴趣的动态变化过程,基于用户历史兴趣查找相似用户;最终将多维度的用户信息融合在一起。
- 历史对话学习器:从历史对话中提取用户multi-view兴趣偏好,包含实体偏好(用户提到的实体)、语义偏好(用户提到的单词)、消费偏好(用户历史喜欢的商品)。
- 多视图兴趣偏好映射器:学习不同view的兴趣偏好间的内在联系。其核心思想是:同一用户的不同view的兴趣偏好应当相关,而不同用户之间应当无关。
- 时序相似用户选择器:历史兴趣相似的用户,其当前兴趣有更大概率会相似。
- 用户兴趣偏好融合:平衡当前对话信息与multi-aspect信息之间的关系
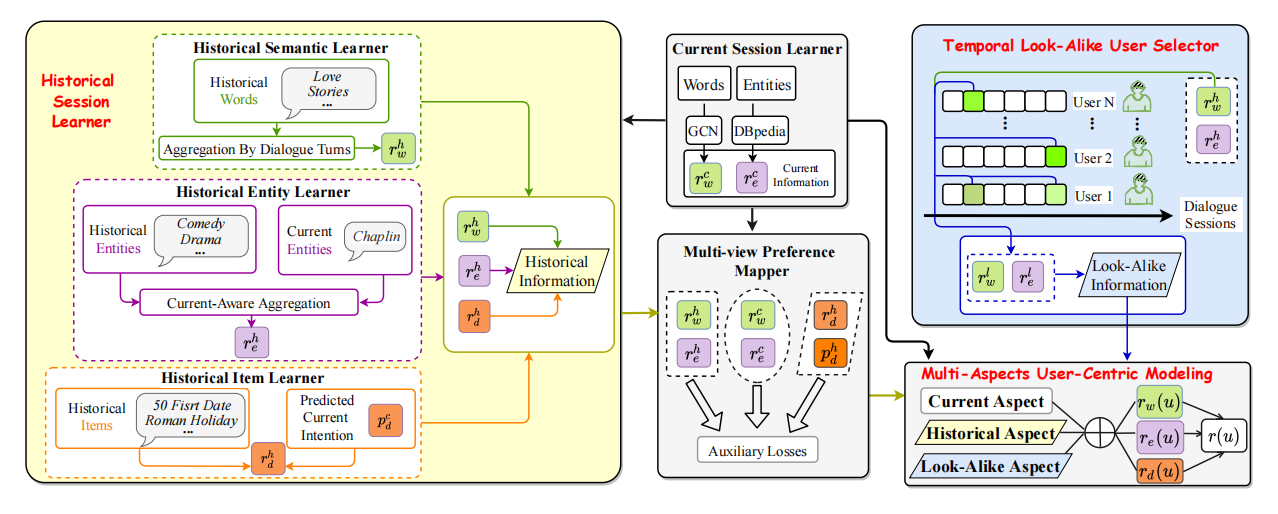
- Current Session Learner:对当前对话建模,与KGSF和KBRD差不多,DBpedia和ConceptNet分别编码实体和单词
- Historical Sessions Learner:
- Historical Entity Learner:用户历史提到的所有实体,与当前实体的相似度进行加权平均,目的是更多地选择和当前实体偏好相似的历史实体,以防止不相关信息干扰
- Historical Word Learner:建模近因效应提取到适当的语义知识,利用每个单词出现的对话轮数对齐加权平均
- Historical Item Learner:历史item,利用当前实体表示和当前单词表示的组合来代替当前商品表示,最终得到历史商品表示
- Multi-View Preference Mapper:基于对比学习,学习不同view的内在信息,进而得到更准确地表示
- Temporal Look-Alike User Selector:由于CRS中用户兴趣随着对话推进不断变化,将用户每一次交互历史都和target用户历史进行比较,学习其中最有用的信息
- Multi-Aspect User-Centric Modeling:Entity-View + Word-View + Item-View
ReDial英文数据集 和 TG-ReDial中文数据集
利用对话时间对数据集进行重排
UniCRS
KDD 2022:Towards Unified Conversational Recommender Systems via Knowledge-Enhanced Prompt Learning
Challenges
- 三个子模块的共同优化
- 推荐系统的去偏
- 精心设计的多轮对话策略
- 引入更多的知识如多模态数据
- 更合理的评测机制和更好的用户模拟器
Original link: http://example.com/2023/03/09/some-ideas/
Copyright Notice: 转载请注明出处.