1 Target-Guided Open-Domain Conversation(ACL 2019)
code: https://github.com/squareRoot3/Target-Guided-Conversation
- motivation: we want a conversational system to chat naturally with human and proactively guide the conversation to a designated target subject
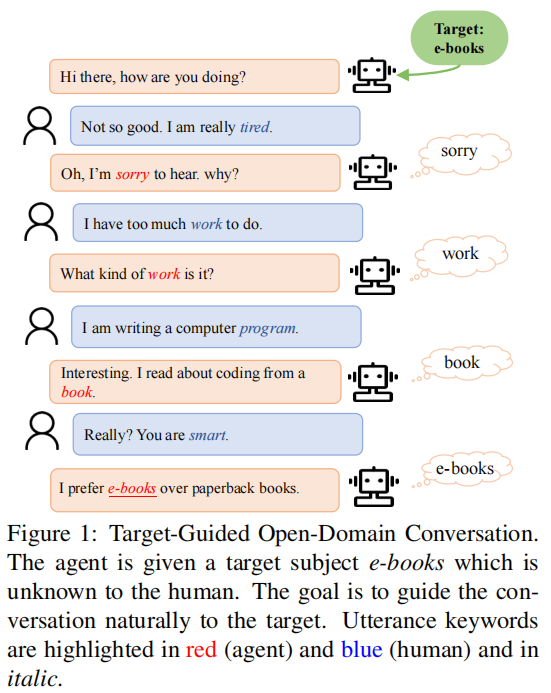
- approach:
- propose a structured approach that introduces coarse-grained keywords to control the intended content of system responses.
- then attain smooth conversation transition through turn-level supervised learning, and drive the conversation towards the target with
discourse-level constraints. - further derive a keyword-augmented conversation dataset for the study.
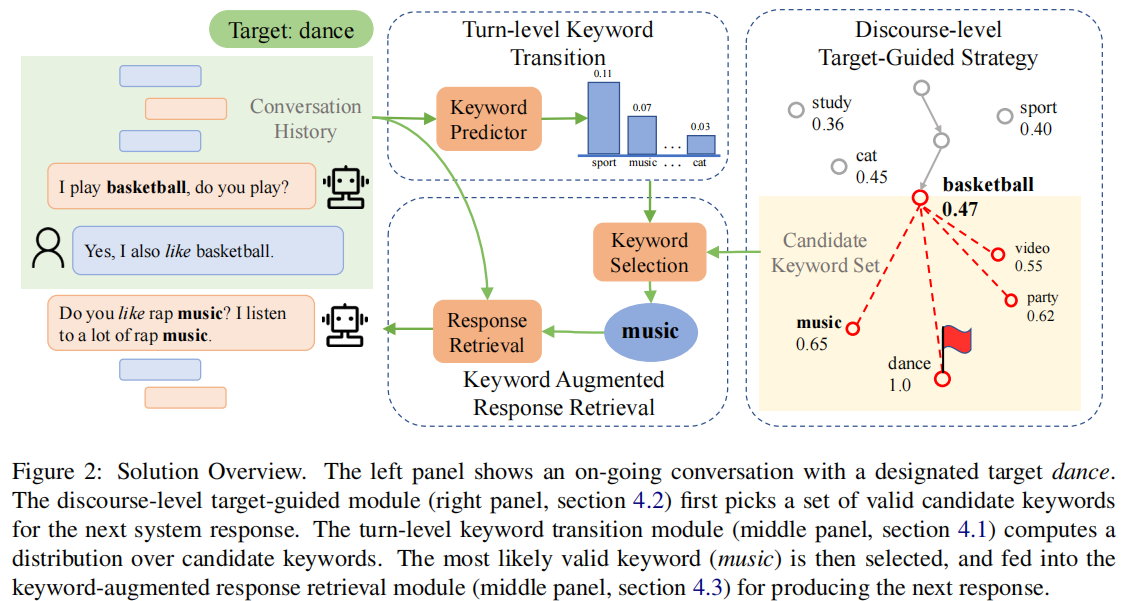
divide-and-conquer approach
Turn-level Keyword Transition
this module aims to predict keywords of the next response that is appropriate in the conversation context. This part is agnostic to the end target,and therefore aligns with the conventional chitchat objective. We thus can use any open-ended chat data with extracted utterance keywords to
learn the prediction module in a supervised manner.
Pairwise PMI-based Transition
given two keywords wi and wj , computes likeliness of wj → wi:
PMI(wi, wj ) = log p(wi|wj )/p(wi)
where p(wi|wj ) is the ratio of transitioning to wi in the next turn given wj in the current turn, and p(wi) is the ratio of wi occurrence.
- The approach enjoys simplicity and interpretability, yet can suffer from data sparsity and perform poorly with a priori unseen transition pairs.
Neural-based Prediction
first use a recurrent network to encode the conversation history, and feed the resulting features to a prediction layer to obtain a distribution over keywords for the next turn.The network is learned by maximizing the likelihood of observed keywords in the data.
- The neural approach is straightforward, but can rely on a large amount of data for learning.
Hybrid Kernel-based Method*
given a pair of a current keyword and a candidate next keyword, by first measuring the cosine similarity of their normalized word embeddings, and feeding the quantity to a kernel layer consisting of K RBF kernels.The output of the kernel layer is a K-dimension kernel feature vector, which is then fed to a single-unit dense layer for a candidate score.The score is finally normalized across all candidate keywords to yield the candidate probability distribution.
Discourse-level Target-Guided Strategy
This module aims to fulfill the end target by proactively driving the discussion topic forward in the course of the conversation.
- constrain that the keyword of each turn must move strictly closer to the end target compared to those of preceding turns.
- use cosine similarity between normalized word embeddings as the measure of keyword closeness.
- the above constraint first collects a set of valid candidates, and the turn-level transition module samples or picks the most likely one the from the set according to the keyword distribution.
- the predicted keyword for next response can be both a smooth transition and an effective step towards the target.
Keyword-augmented Response Retrieval
The final module in the system aims to produce a response conditioning on both the conversation history and the predicted keyword.
- retrieval-based approach* or generation-based method
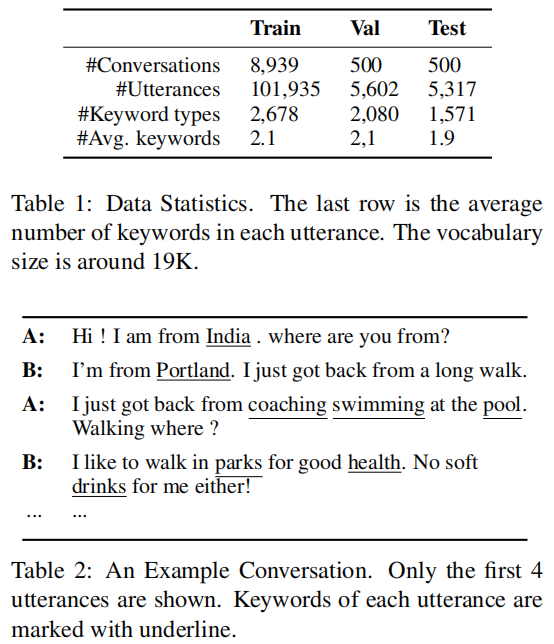
Dataset
the PersonaChat corpus:
- The conversations cover a broadrange of topics such as work, family, personal interest, etc; and the discussion topics change frequently during the course of the conversations.These properties make the conversations particularly suitable for learning smooth, natural transitions at each turn.
- without end targets and do not exhibit target-guided behaviors
*apply a rule-based keyword extractor which combines TF-IDF and Part-Of Speech features for scoring word salience
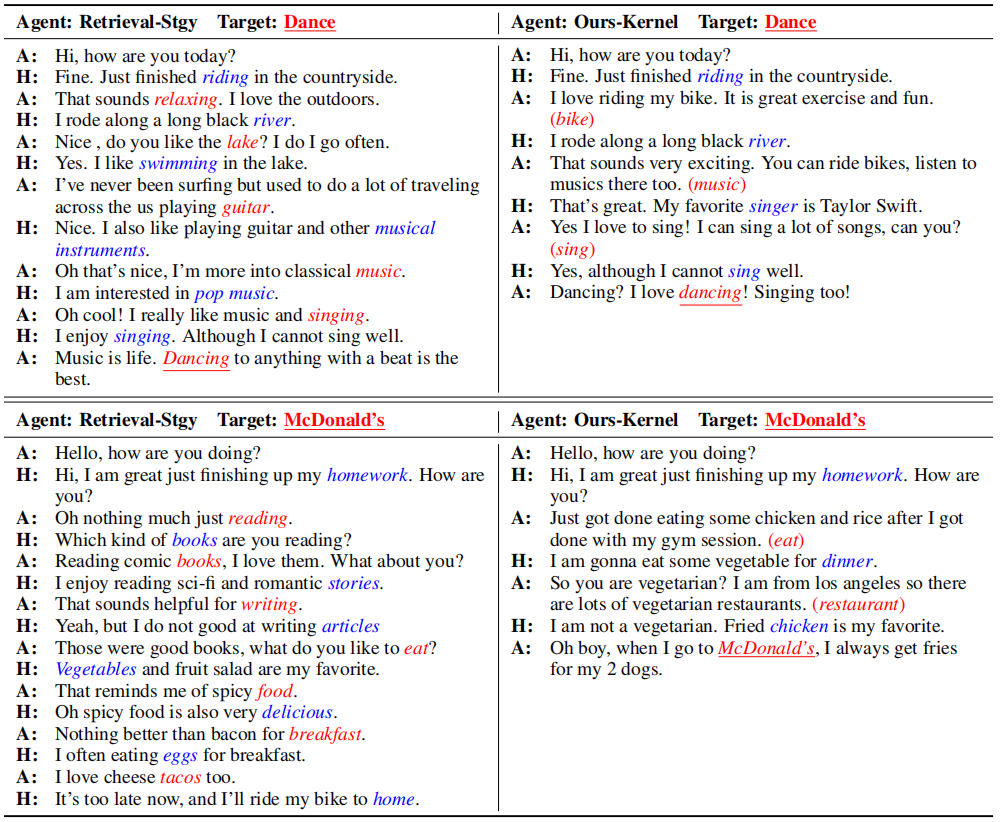
Case Study
2 Target-Guided Open-Domain Conversation Planning (COLING 2022)
motivation: Prior studies addressing target-oriented conversational tasks lack a crucial notion that has been intensively studied in the context of goaloriented artificial intelligence agents, namely,planning
contributions:
- propose the TGCP task as a framework to assess the prerequisite ability of a model for goal-oriented conversation planning

- conduct a set of experiments on the TGCP framework using
several existing retrieval-based neural models and recently proposed strong generative neural models of conversational agents
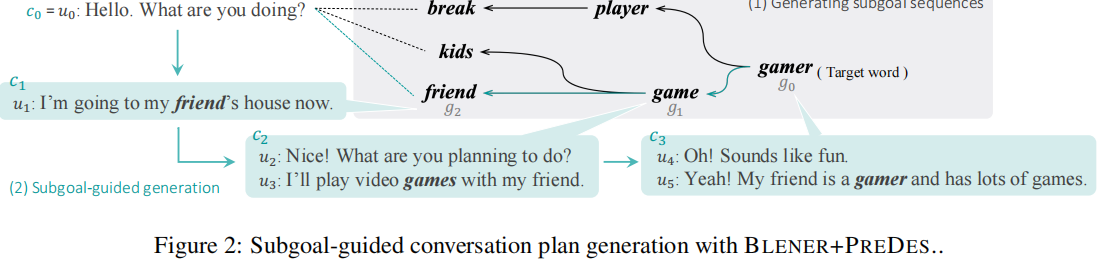
- Our experimental results reveal the challenges facing current technology
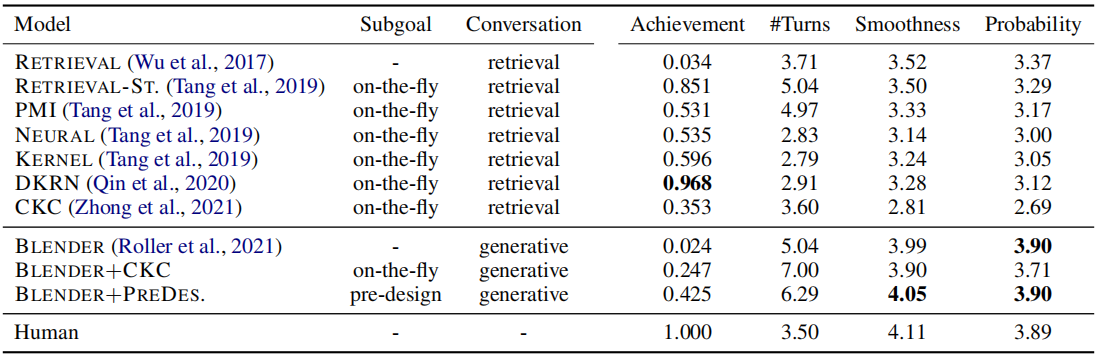
- Using TGCP, we revealed that the dialogue models with current technology have difficulty planning conversations to achieve given goals while ensuring the naturalness of the conversation.
- The experimental results also showed that refining the subgoal strategies for generative models might be an effective method to overcome this trade-off.
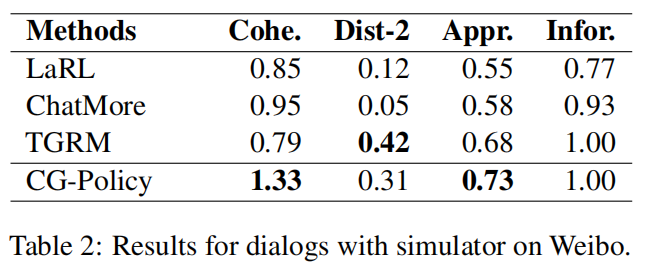
3 Conversational Graph Grounded Policy Learning for Open-Domain Conversation Generation(ACL 2020)
- motivation: utterance-level methods tend to produce less coherent multi-turn dialogs since it is quite challenging to learn semantic transitions in a dialog flow merely from dialog data without the help of prior information
- approach:propose to represent prior information about dialog transitions as a graph and learn a graph grounded dialog policy, aimed at fostering a more coherent and controllable dialog.
- a Conversational Graph (CG) that captures both localappropriateness and global-coherence information,
- a reinforcement learning (RL) based policy,model that learns to leverage the CG to foster a more coherent dialog.
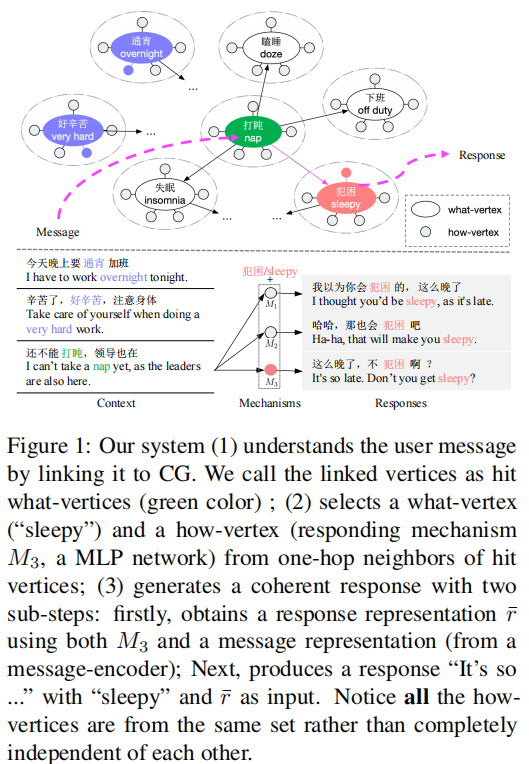
Conversational Graph (CG)
use vertices to represent utterance content, and edges to represent dialog transitions between utterances:
- a what-vertex that contains a keyword
- a how-vertex that contains a responding mechanism (from a multi-mapping based generator) to capture rich variability of expressions
also use this multi-mapping based method to build edges between two what-vertices to capture the local-appropriateness between the two keywords as a message and a response respectively
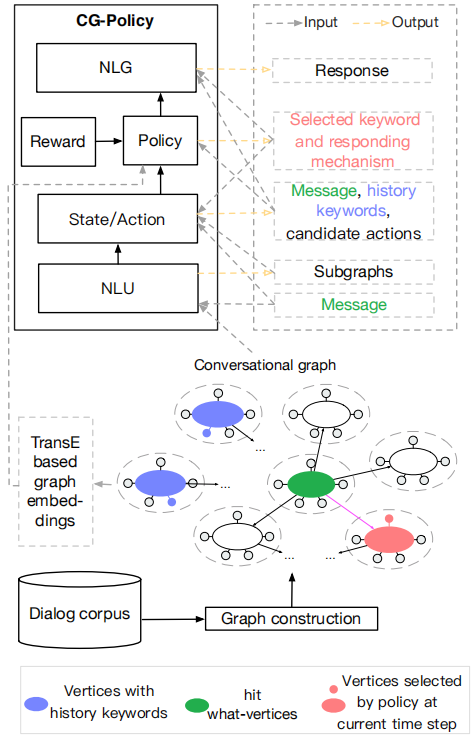
- Given a user message, to obtain candidate actions, the NLU module attempts to retrieve contextually relevant subgraphs from CG.
- The state/action module maintains candidate actions, history keywords that selected by policy at previous turns or mentioned by user, and the message.
- The policy module learns to select a response keyword and a
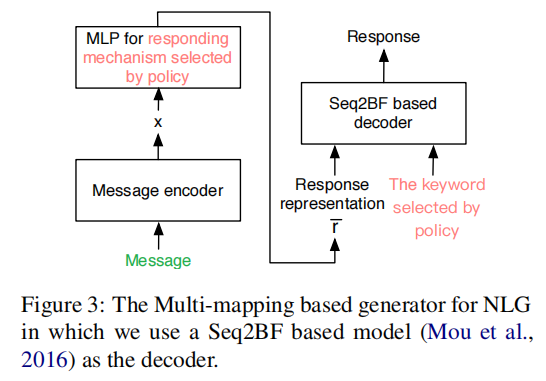
responding mechanism from the above subgraphs. - The NLG module first encodes the message into a representation using a message encoder and the selected mechanism, and then employs a Seq2BF
model (Mou et al., 2016) to produce a response with the above representation and the selected keyword as input.
Background: Multi-mapping Generator for NLG
CG Construction
Given a dialog corpus D, we construct the CG with three steps:
- what-vertex construction:use a rule-based keyword extractor to obtain salient keywords from utterances in D
- how-vertex construction: a set of responding mechanisms from the generator
- edge construction:
- One is to join two what-vertices:selecting top five keywords decoded (decoding length is 1) by each responding mechanism
- the other is to join a what-vertex and a how-vertex:use the ground-truth response to select the most suitable mechanism for each keyword.select top five mechanisms that are frequently selected for vw’s keyword
NLU
To obtain subgraphs to provide high-quality candidate actions:
- extract keywords in the last utterance of the context (message) using the same tool in CG construction
- link each keyword to the CG through exact string matching, to obtain multiple hit what-vertices
- retrieve a subgraph for each keyword, and use vertices (exclude hit what-vertices) in these subgraphs as candidate actions
State/Action
This module maintains candidate actions, history keywords that selected by the policy or mentioned by user, and the message.
Policy
- State representation: concatenate a message representation and a history keywords representation + a graph attention mechanism and graph embedding to encode global structure information into state representation
- Policy decision:
- what-policy selects a what-vertex from candidate what-vertices
- how-policy selects a how-vertex from how-vertex neighbors of the selected what-vertex
Rewards
utterance-level rewards:
- Local relevance:DualEncoder in (Lowe et al., 2015)
- Repetition:Repetition penalty is 1 if the generated response shares more than 60% words with any contextual utterances, otherwise 0
- Target similarity:calculate cosine similarity between the chosen keyword and the target word in pretrained word embedding space as target similarity
To leverage the global graph structure information of CG to facilitate policy learning:
- Global coherence: the average cosine distance between the chosen what-vertex and one of history what-vertices (selected or mentioned previously) in TransE based embedding space
- Sustainability: calculate a PageRank score (calculated on the full CG) for the chosen whatvertex
- Shortest path distance to the target:closer 1;otherwise 0;not change -1
NLG
feed the keyword in the selected what-vertex and r¯ into a Seq2BF decoder (Mou et al., 2016) for response generation.
Original link: http://example.com/2023/04/27/Dialog-Papers/
Copyright Notice: 转载请注明出处.