Prompt Engineering
Prompt Engineering, also known as In-Context Prompting, refers to methods for how to communicate with LLM to steer its behavior for desired outcomes without updating the model weights.
提示工程,也称为上下文提示,是指如何在不更新模型权重的情况下与LLM通信以引导其行为以获得所需结果的方法。
the goal of prompt engineering is about alignment and model steerability.
提示工程的核心目标是对齐和模型可控性。
Basic Prompting
Zero-Shot
Zero-shot learning is to simply feed the task text to the model and ask for results:
1 | Text: i'll bet the video game is a lot more fun than the film. |
Few-shot
Few-shot learning presents a set of high-quality demonstrations, each consisting of both input and desired output, on the target task. As the model first sees good examples, it can better understand human intention and criteria for what kinds of answers are wanted. Therefore, few-shot learning often leads to better performance than zero-shot. However, it comes at the cost of more token consumption and may hit the context length limit when input and output text are long.
但是,它以消耗更多的tokens为代价,并且当输入和输出文本较长时,可能会达到上下文长度限制。
1 | Text: (lawrence bounces) all over the stage, dancing, running, sweating, mopping his face and generally displaying the wacky talent that brought him fame in the first place. |
- choice of prompt format, training examples, and the order of the examples can lead to dramatically different performance
Calibrate Before Use: Improving Few-Shot Performance of Language Models
https://arxiv.org/abs/2102.09690
Tips for Example Selection
Tips for Example Ordering
Instruction Prompting
Instructed LM (e.g. InstructGPT, natural instruction) finetunes a pretrained model with high-quality tuples of (task instruction, input, ground truth output) to make LM better understand user intention and follow instruction.
RLHF (Reinforcement Learning from Human Feedback) is a common method to do so. The benefit of instruction following style fine-tuning improves the model to be more aligned with human intention and greatly reduces the cost of communication.
- When interacting with instruction models, we should describe the task requirement in details, trying to be specific and precise and avoiding say “not do something” but rather specify what to do.具体简洁地指明要做什么
1 | Please label the sentiment towards the movie of the given movie review. The sentiment label should be "positive" or "negative". |
Explaining the desired audience is another smart way to give instructions解释所需的受众
1
2Describe what is quantum physics to a 6-year-old.
safe content
1
2... in language that is safe for work.
few-shot learning with instruction prompting:
In-Context Instruction Learning
https://arxiv.org/abs/2302.14691
Self-Consistency Sampling
Self-consistency sampling is to sample multiple outputs with temperature > 0 and then selecting the best one out of these candidates. The criteria for selecting the best candidate can vary from task to task. A general solution is to pick majority vote. For tasks that are easy to validate such as a programming question with unit tests, we can simply run through the interpreter and verify the correctness with unit tests.
对温度为大于0的多个输出进行采样,然后从这些候选输出中选择最佳输出。选择最佳候选人的标准可能因任务而异。一般的解决方案是选择多数票。
Self-Consistency Improves Chain of Thought Reasoning in Language Models
https://arxiv.org/abs/2203.11171
Chain-of-Thought (CoT)
Chain-of-thought (CoT) prompting generates a sequence of short sentences to describe reasoning logics step by step, known as reasoning chains or rationales, to eventually lead to the final answer. The benefit of CoT is more pronounced for complicated reasoning tasks, while using large models (e.g. with more than 50B parameters). Simple tasks only benefit slightly from CoT prompting.
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
https://arxiv.org/abs/2201.11903
Types of CoT prompts
Few-shot CoT. It is to prompt the model with a few demonstrations, each containing manually written (or model-generated) high-quality reasoning chains.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15Question: Tom and Elizabeth have a competition to climb a hill. Elizabeth takes 30 minutes to climb the hill. Tom takes four times as long as Elizabeth does to climb the hill. How many hours does it take Tom to climb up the hill?
Answer: It takes Tom 30*4 = <<30*4=120>>120 minutes to climb the hill.
It takes Tom 120/60 = <<120/60=2>>2 hours to climb the hill.
So the answer is 2.
===
Question: Jack is a soccer player. He needs to buy two pairs of socks and a pair of soccer shoes. Each pair of socks cost $9.50, and the shoes cost $92. Jack has $40. How much more money does Jack need?
Answer: The total cost of two pairs of socks is $9.50 x 2 = $<<9.5*2=19>>19.
The total cost of the socks and the shoes is $19 + $92 = $<<19+92=111>>111.
Jack need $111 - $40 = $<<111-40=71>>71 more.
So the answer is 71.
===
Question: Marty has 100 centimeters of ribbon that he must cut into 4 equal parts. Each of the cut parts must be divided into 5 equal parts. How long will each final cut be?
Answer:Zero-shot CoT. Use natural language statement like “Let’s think step by step” to explicitly encourage the model to first generate reasoning chains and then to prompt with “Therefore, the answer is” to produce answers. Or a similar statement “Let’s work this out it a step by step to be sure we have the right answer”.
1
2
3Question: Marty has 100 centimeters of ribbon that he must cut into 4 equal parts. Each of the cut parts must be divided into 5 equal parts. How long will each final cut be?
Answer: Let's think step by step.Large Language Models are Zero-Shot Reasoners
https://arxiv.org/abs/2205.11916
Large Language Models Are Human-Level Prompt Engineers
https://arxiv.org/abs/2211.01910
Papers
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Google Research,Brain Team
- Motivation:
- scaling up model size alone has not proved sufficient for achieving high performance on challenging tasks such as arithmetic, commonsense, and symbolic reasoning;
- First, techniques for arithmetic reasoning can benefit from generating natural language rationales that lead to the final answer;
- Second, large language models offer the exciting prospect of in-context few-shot learning via prompting.
- Methods:
- Chain-of-Thought Prompting
- First, chain of thought, in principle, allows models to decompose multi-step problems into intermediate steps, which means that additional computation can be allocated to problems that require more reasoning steps;
- Second, a chain of thought provides an interpretable window into the behavior of the model;
- Third, chain-of-thought reasoning can be used for tasks such as math word problems, commonsense reasoning, and symbolic manipulation, and is potentially applicable (at least in principle) to any task that humans can solve via language;
- Finally, chain-of-thought reasoning can be readily elicited in sufficiently large off-the-shelf language models simply by including examples of chain of thought sequences into the exemplars of few-shot prompting.
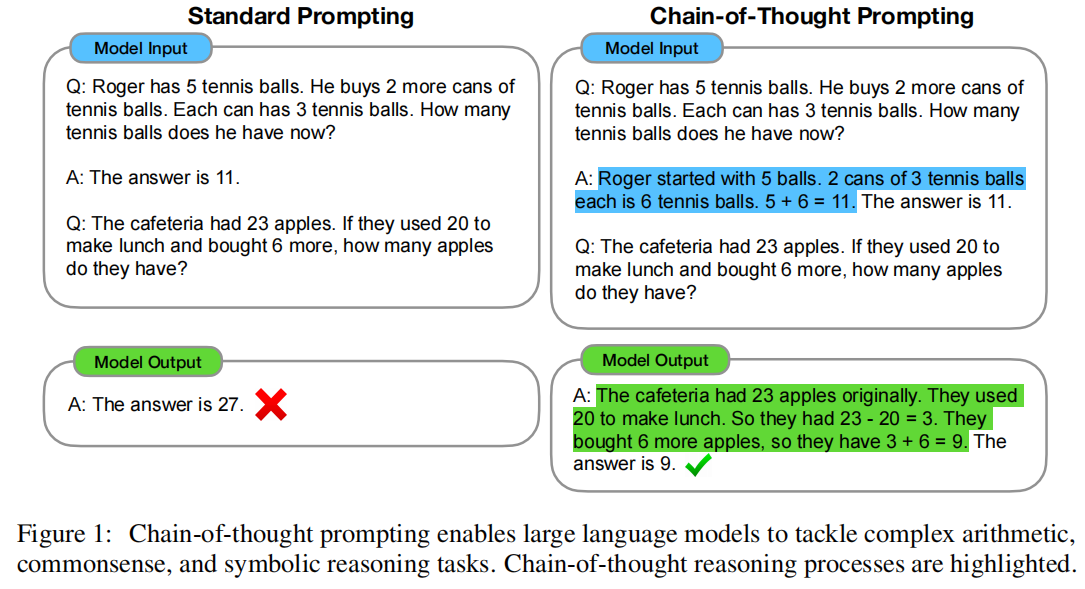
- Experiments:
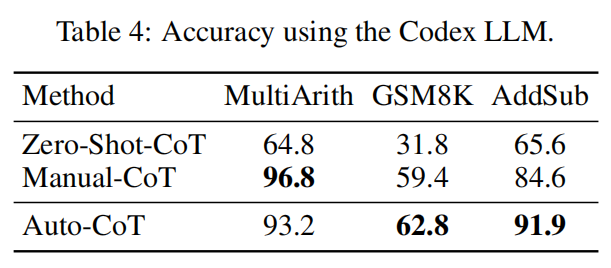
Arithmetic Reasoning
manually composed a set of eight few-shot exemplars with chains of thought for prompting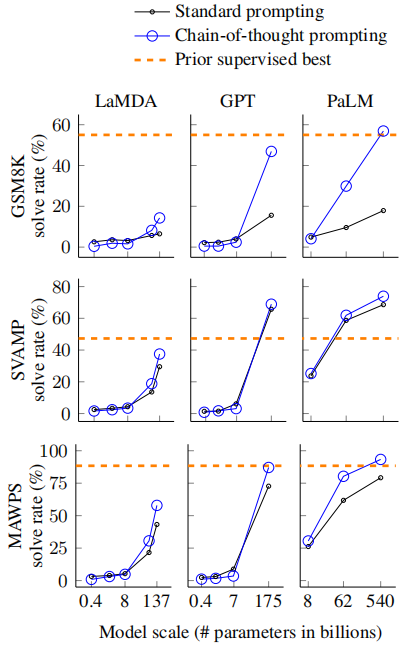
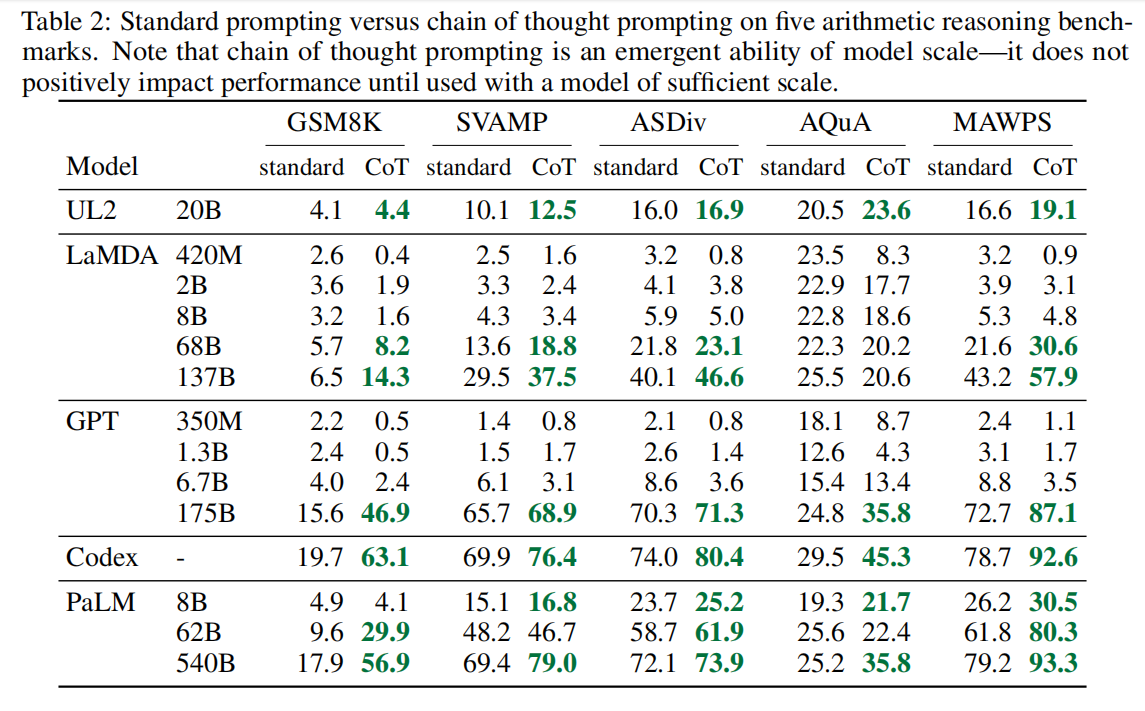
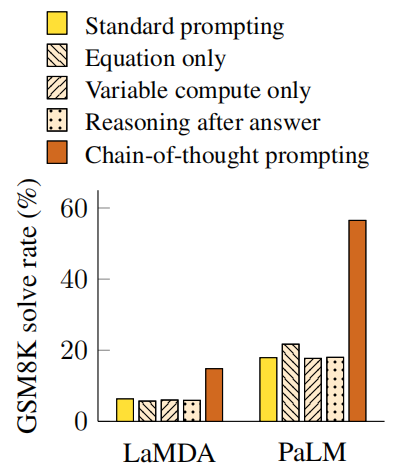
- chain-of-thought prompting does not positively impact performance for small models, and only yields performance gains when used with models of ∼100B parameters.
- chain-of-thought prompting has larger performance gains for more-complicated problems.
Robustness of Chain of Thought
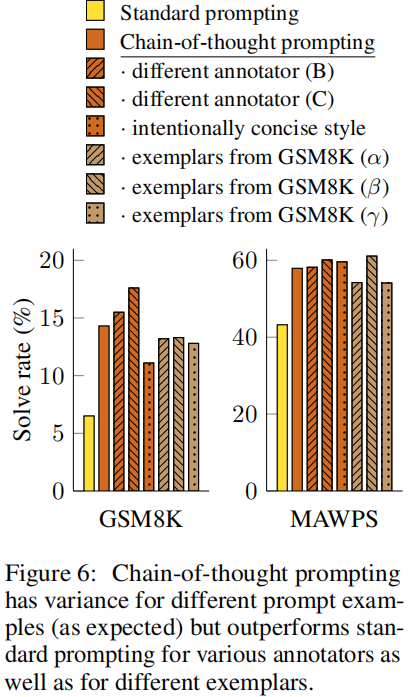
Commonsense Reasoning
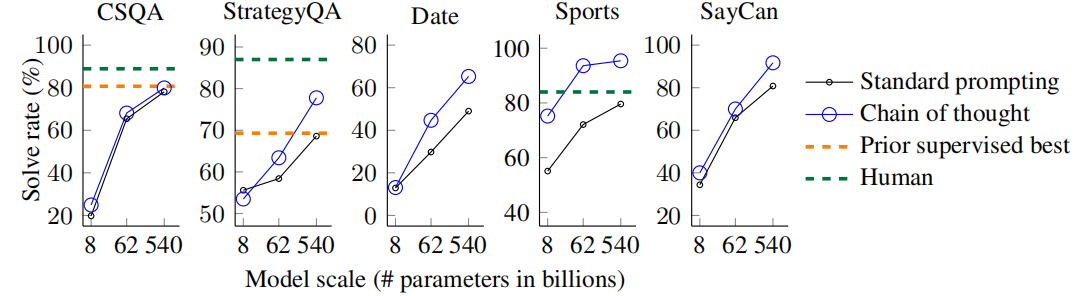
Symbolic Reasoning
Large Language Models are Zero-Shot Reasoners
Tokyo University + Google Research,Brain Team NeurIPS 2022
- Motivation:
- Few-shot-CoT requiring human engineering of multi-step reasoning prompts;
- their performance deteriorates if prompt example question types and task question type are unmatched, suggesting high sensitivity to per-task prompt designs;
- these successes are often attributed to LLMs’ ability for few-shot learning.
- Methods:
- Zero-shot-CoT : Zero-shot Chain of Thought

- Two-stage prompting:
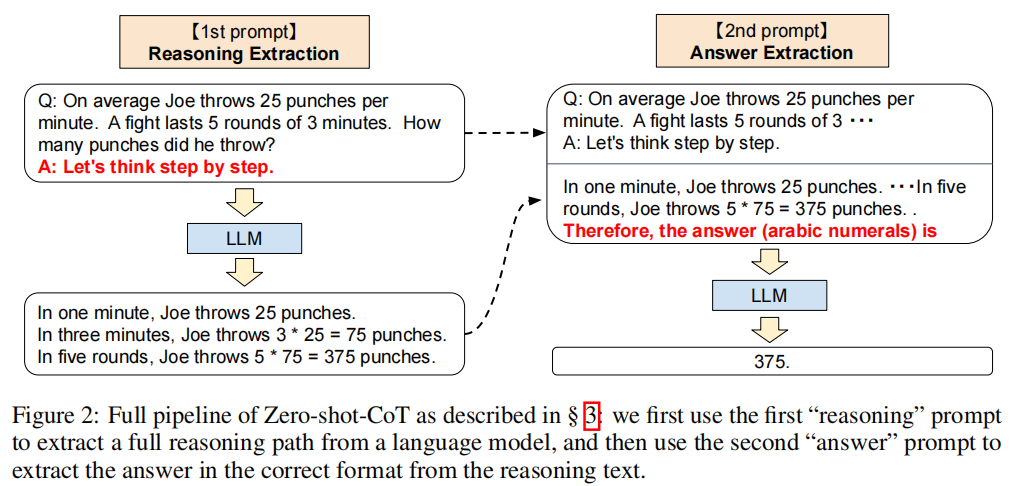
- Experiments:
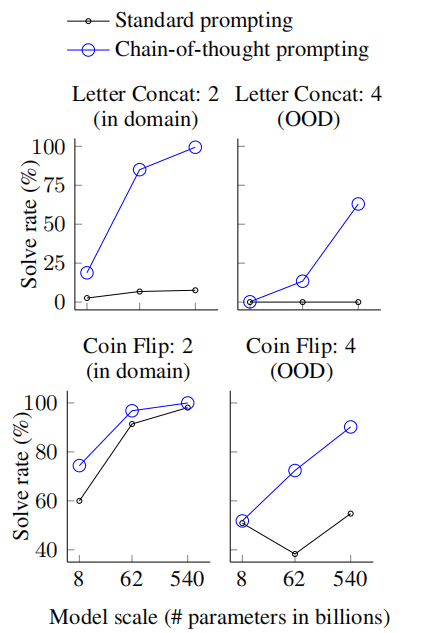
Zero-shot-CoT vs. Zero-shot
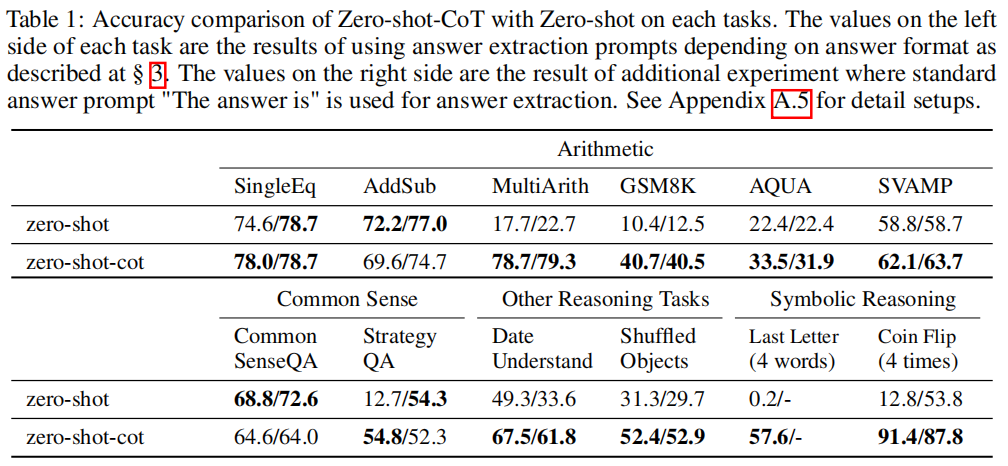
Comparison with other baselines
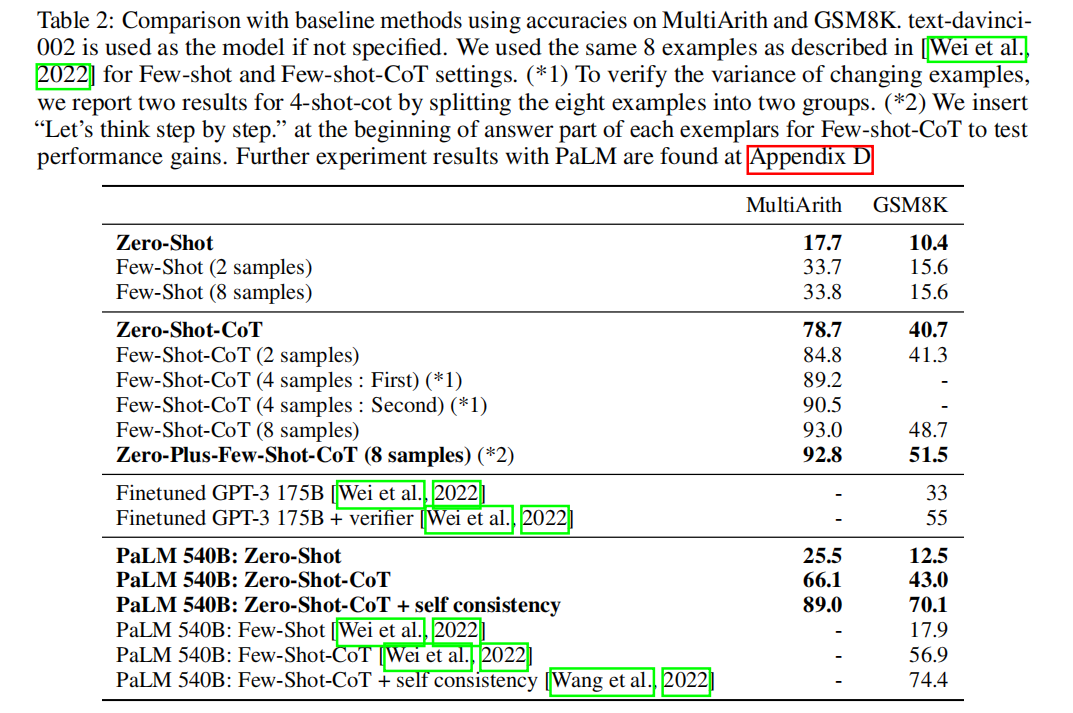
Does model size matter for zero-shot reasoning?
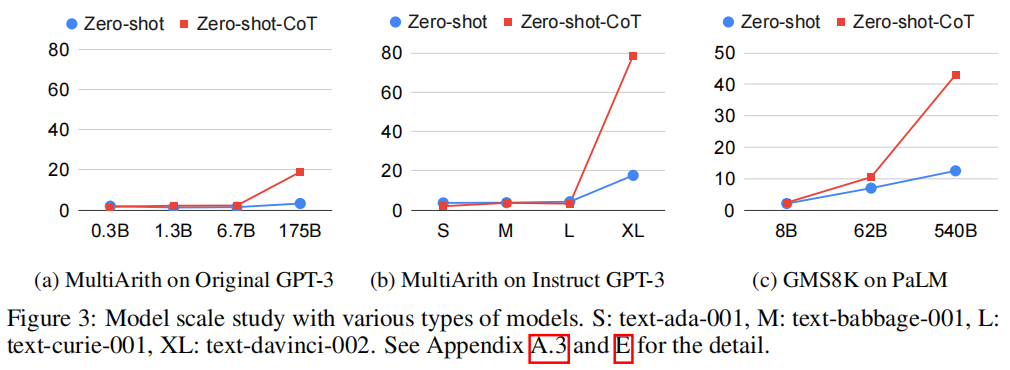
How does prompt selection affect Zero-shot-CoT?
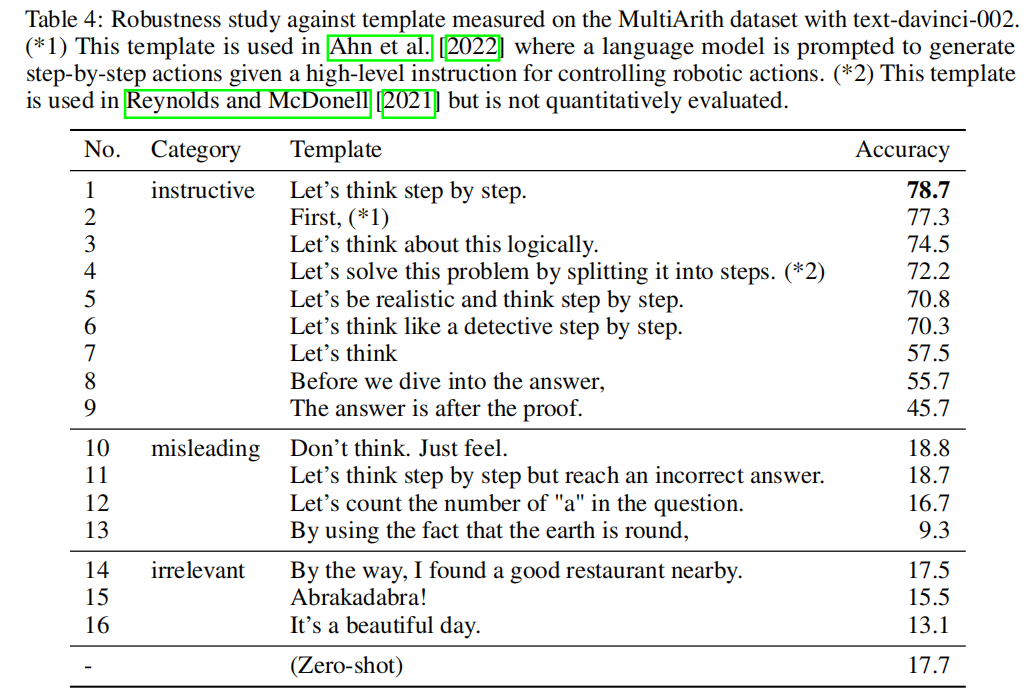
How does prompt selection affect Few-shot-CoT?
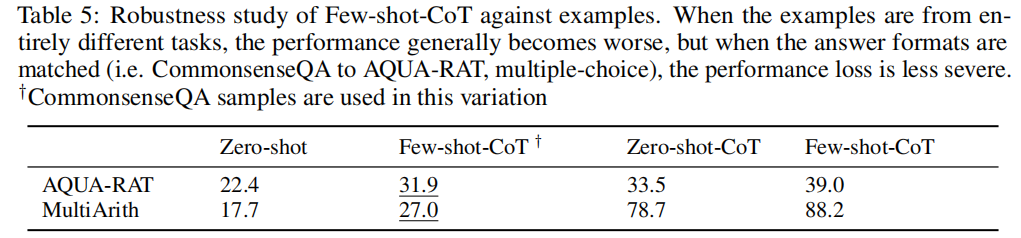
Automatic Chain of Thought Prompting in Large Language Models
Amazon Web Services
code: https://github.com/amazon-research/auto-cot
- Motivation:
- CoT prompting has two major paradigms. One leverages a simple prompt like “Let’s think step by step” to facilitate step-by-step thinking before answering a question. The other uses a few manual demonstrations one by one, each composed of a question and a reasoning chain that leads to an answer.
- The superior performance of the second paradigm hinges on the hand-crafting of task-specific
demonstrations one by one. - these generated chains by first paradigm often come with mistakes.
- Methods:
- Auto-CoT : samples questions with diversity and generates reasoning chains to construct demonstrations
(1) Retrieval-Q-CoT and Random-Q-CoT
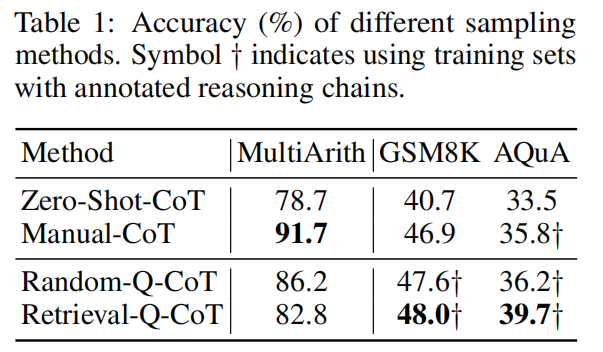
- Retrieval-Q-CoT Fails due to Misleading by Similarity
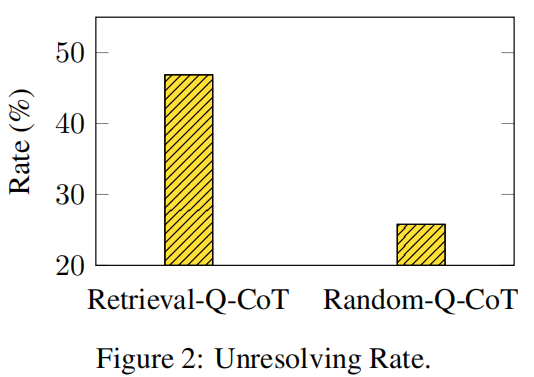
- Errors Frequently Fall into the Same Cluster
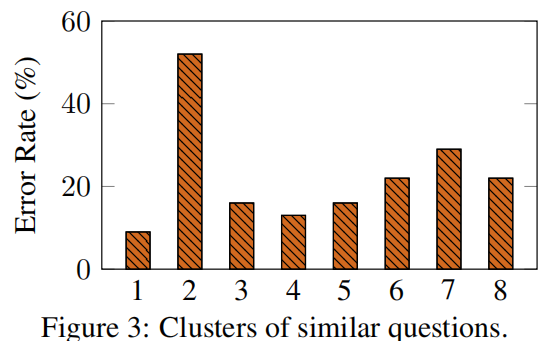
(2) Diversity May Mitigate Misleading by Similarity


- Experiments:
Competitive Performance of Auto-CoT on Ten Datasets
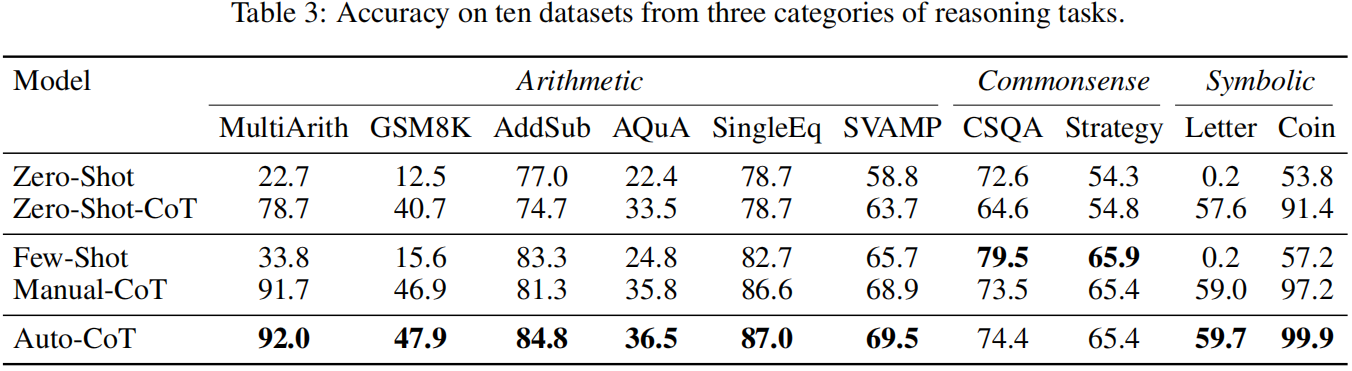
Effect of Wrong Demonstrations
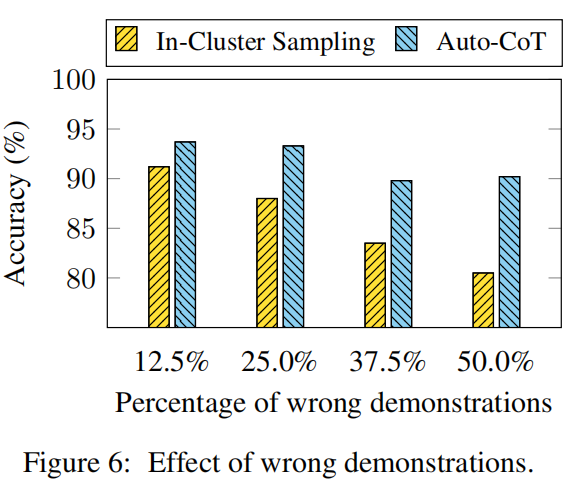
General Effectiveness Using the Codex LLM
Self-consistency Improves Chain of Thought Reasoning in Language Models
Google Research,Brain Team ICLR 2023
- Motivation:
- Although language models have demonstrated remarkable success across a range of NLP tasks, their ability to demonstrate reasoning is often seen as a limitation, which cannot be overcome solely by increasing model scale;
- The Greedy Decoding of traditional chain-of-thought prompting: the repetitiveness,local-optimality, and the stochasticity of a single sampled generation.
- Methods:
- self-consistency,a new decoding strategy.
- It first samples a diverse set of reasoning paths instead of only taking the greedy one, and then selects the most consistent answer by marginalizing out the sampled reasoning paths.
- Self-consistency leverages the intuition that a complex reasoning problem typically admits multiple different ways of thinking leading to its unique correct answer.
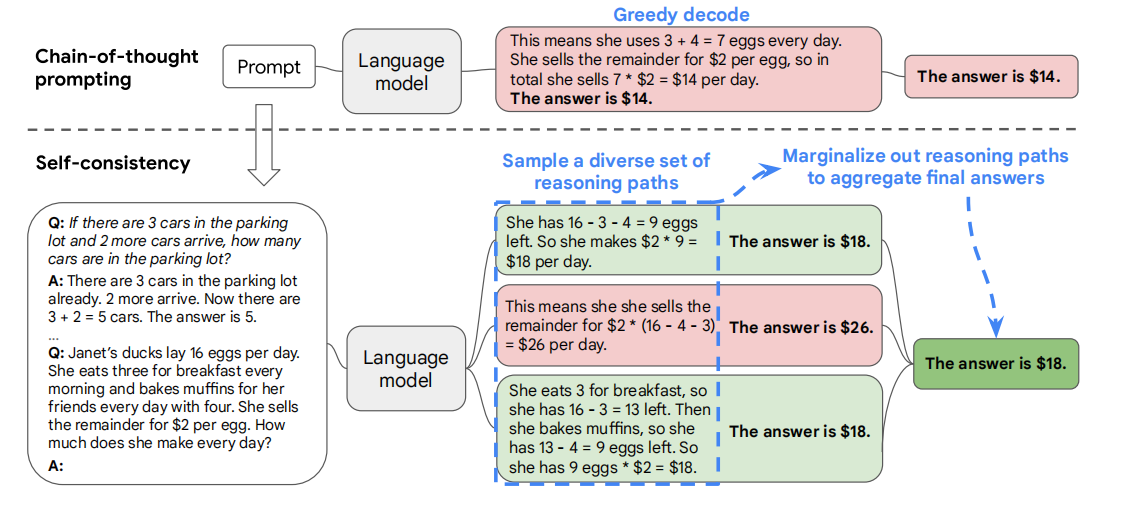
- Experiments:
test accuracy over a set of reasoning tasks by using different answer aggregation strategies
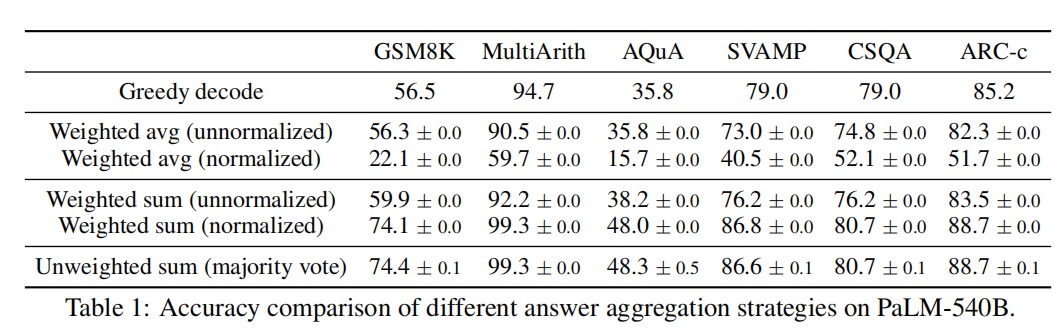
Arithmetic Reasoning
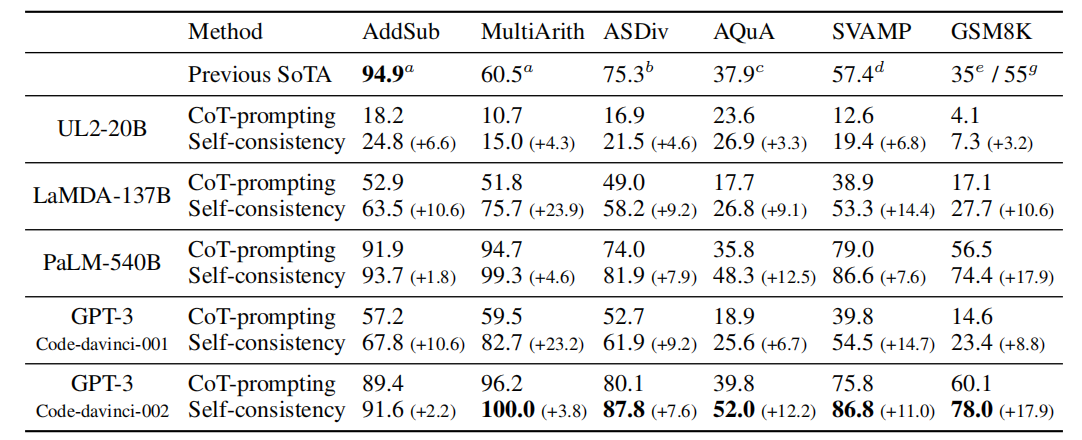
Commonsense and Symbolic Reasoning
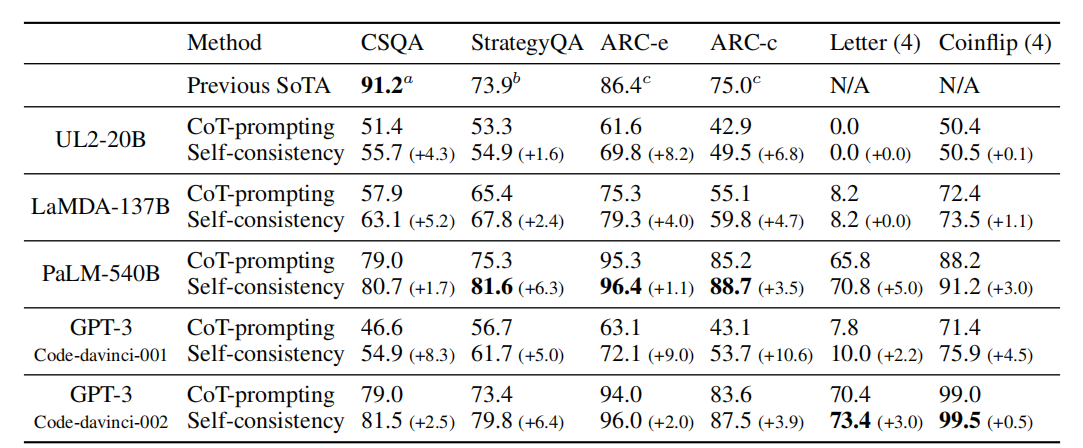
the num of sampled reasoning paths
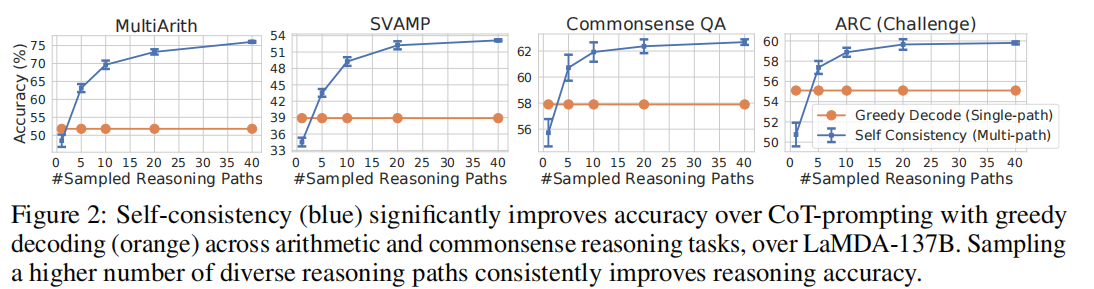
Self-Consistency helps when Chain-Of-Thought hurts performance

Self-Consistency is Robust to Sampling Strategies and Scaling

Self-Consistency Improves Robustness to Imperfect Prompts
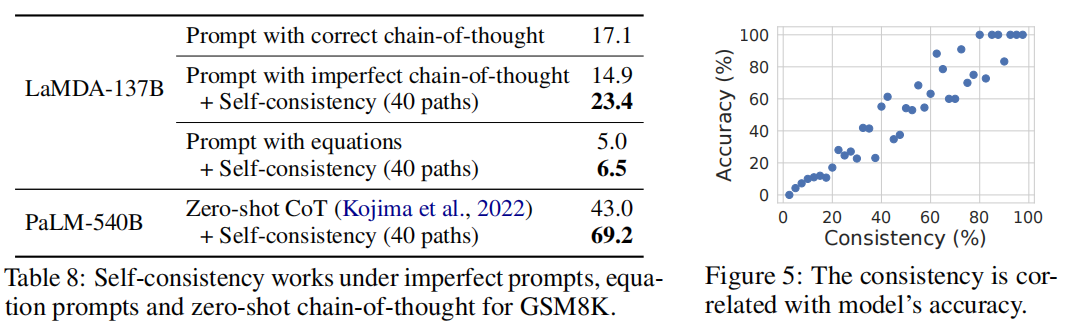
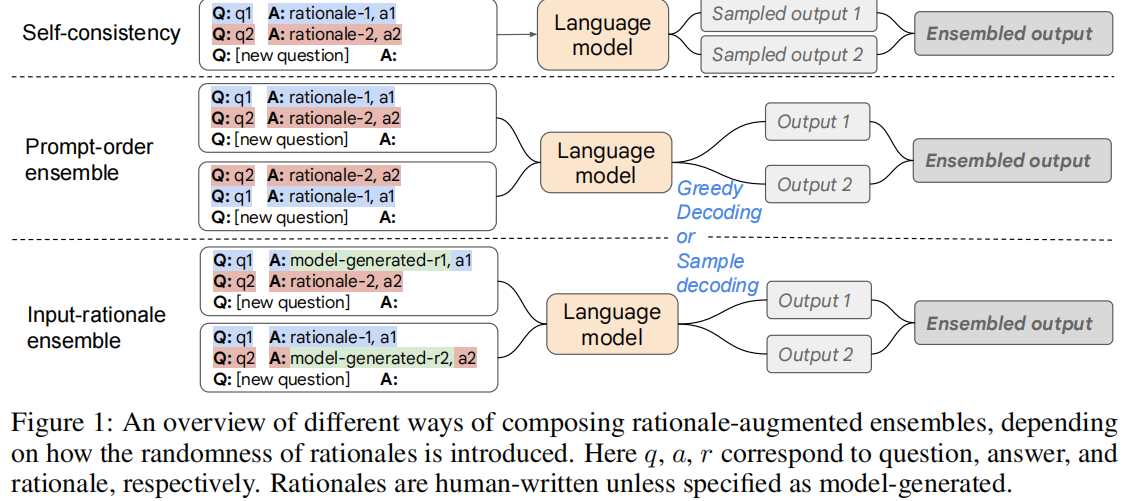
Rationale-Augmented Ensembles in Language Models
Google Research,Brain Team
- Motivation:
- existing approaches, which rely on manual prompt engineering, are subject to sub-optimal rationales that may harm performance.
- Methods:
- Rationale-Augmented Ensembles , where we identify rationale sampling in the output space as the key component to robustly improve performance.
(1) Optimality of the rationales in few-shot learning
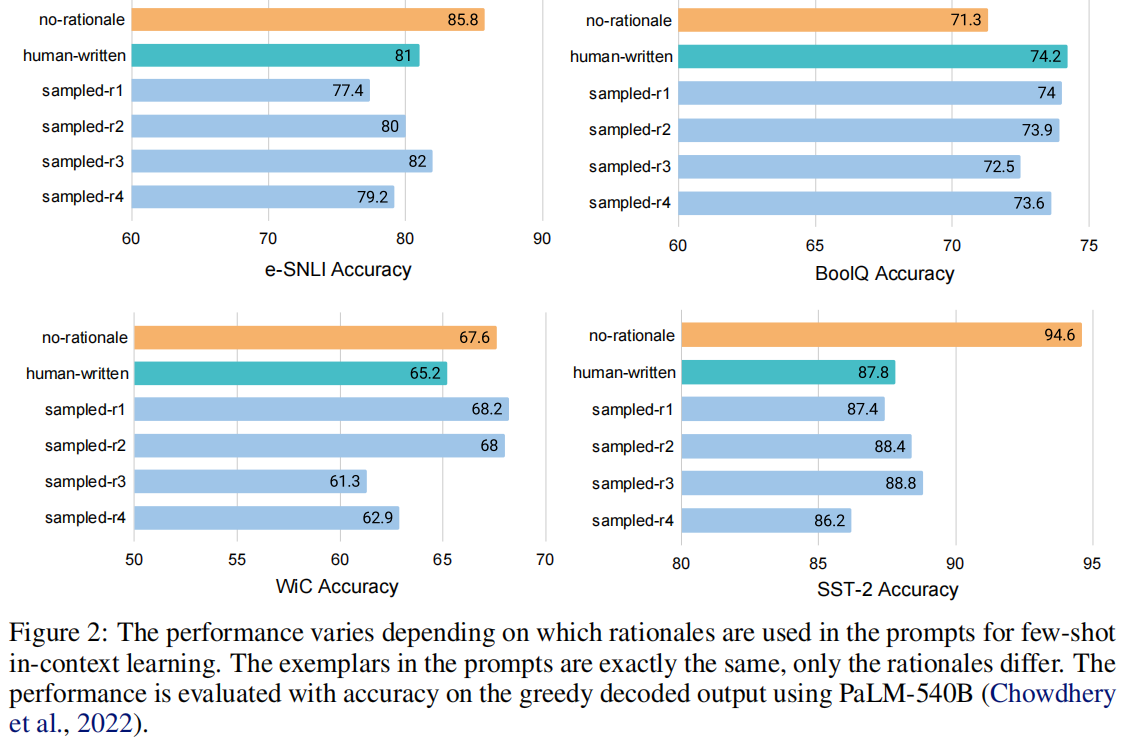
- the addition of human-written rationales does not always yield better performances;
- the quality of the rationales in the prompts has a significant effect on final performance;
- simply including a rationale does not always improve task performance.
(2) Rationale-augmented ensembles(that can automatically aggregate across diverse rationales to overcome the brittleness of performance to sub-optimal human-written rationales)

- Experiments:
results for the PaLM-540B model
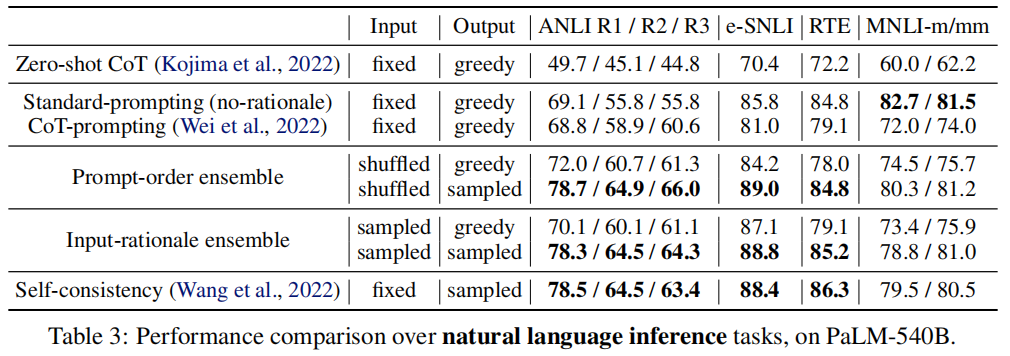
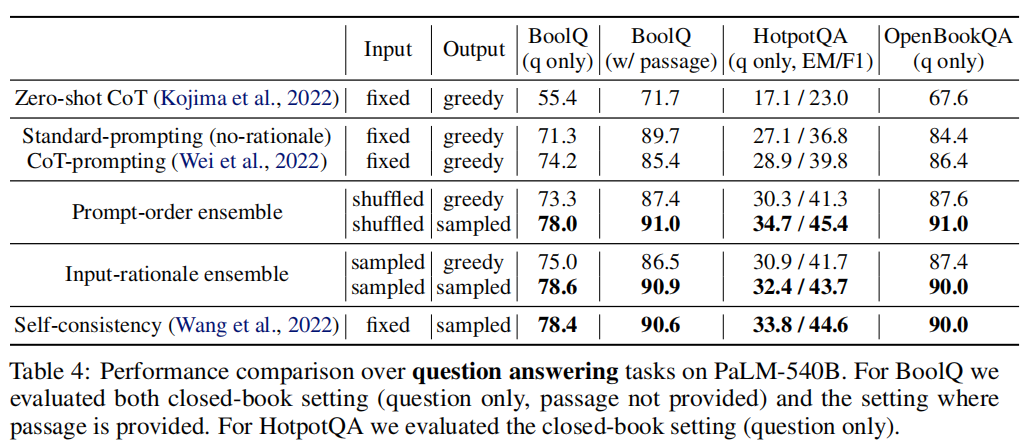
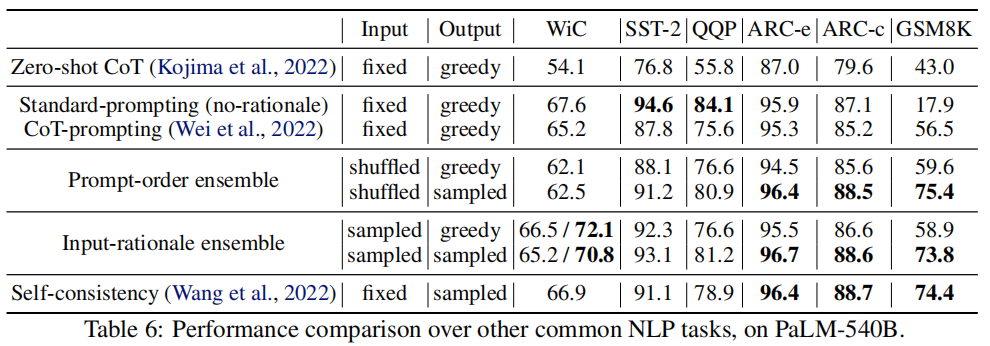
(1) the “output-sampled” version yields better final performance than the “output-greedy” version for almost every task;
(2) The “output-sampled” version of each rationale-ensembling method almost always improves performance over standard prompting without rationales, as well as rationale-based few-shot and zero-shot prompting;
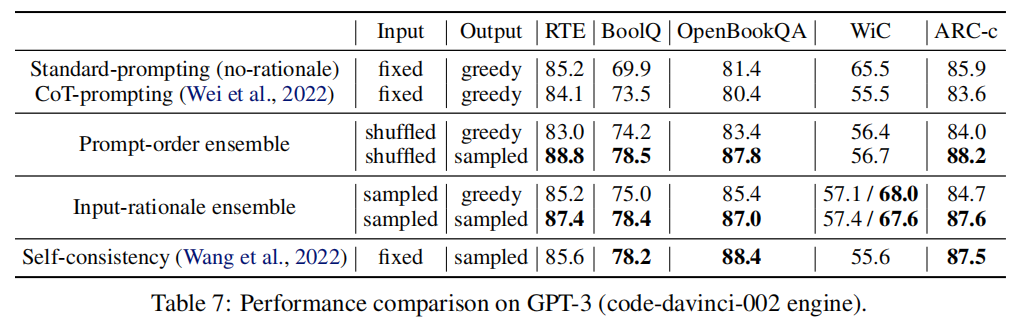
(3) rationale-augmented ensembles provide a reliable approach to improving the final task performance of rationale-based few-shot in-context learning. Interpretability of model predictions is also enhanced by the presence of generated rationales in the model outputs.Results on GPT-3
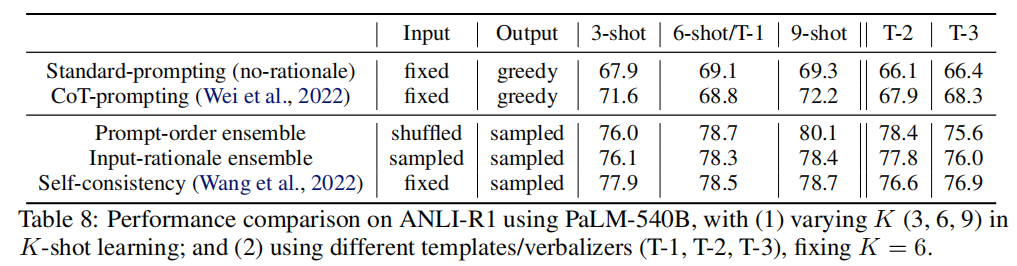
Effect of K in K-shot in-context learning & Effect of templates and verbalizers
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
Google Research,Brain Team ICLR 2023
- Motivation:
- Chain-of-thought prompting tends to perform poorly on tasks which requires solving problems harder than the exemplars shown in the prompts.
- Methods:
- least-to-most prompting, to break down a complex problem into a series of simpler subproblems and then solve them in sequence.
(1) query the language model to decompose the problem into subproblems;
(2) query the language model to sequentially solve the subproblems. The answer to the second subproblem is built on the answer to the first subproblem.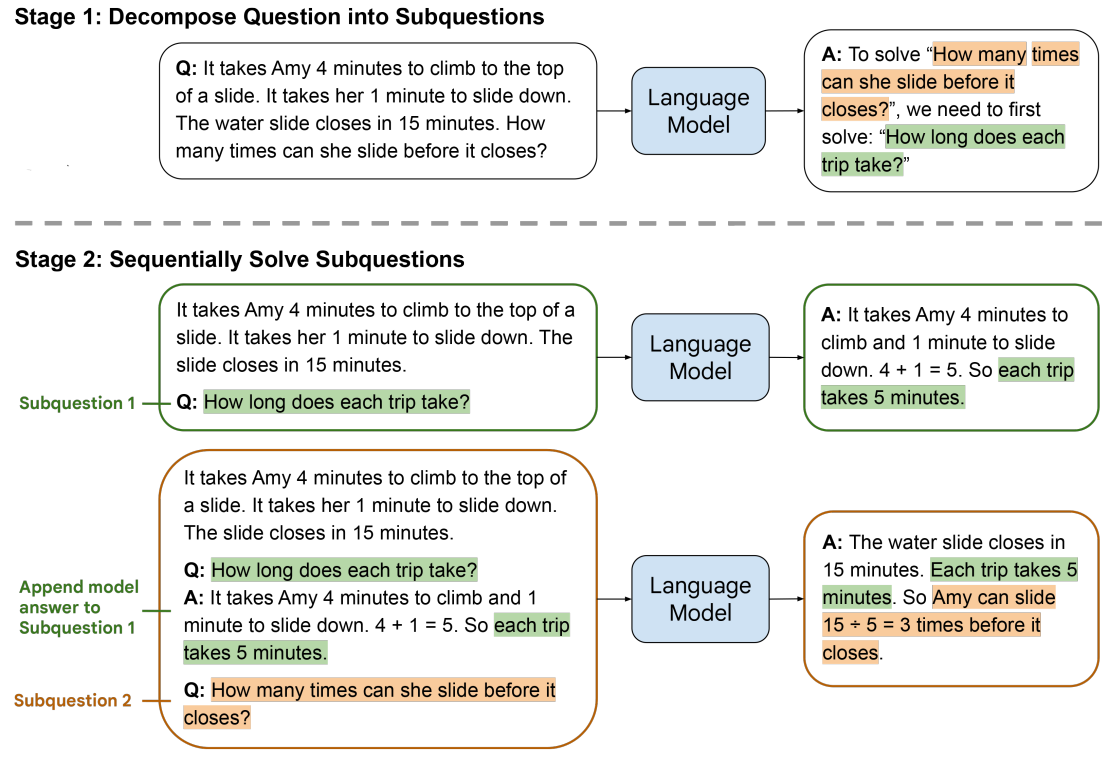
- Experiments:
- SYMBOLIC MANIPULATION
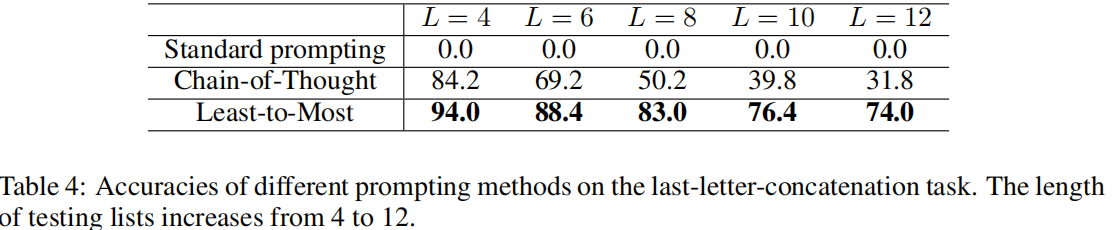
- COMPOSITIONAL GENERALIZATION


- MATH REASONING
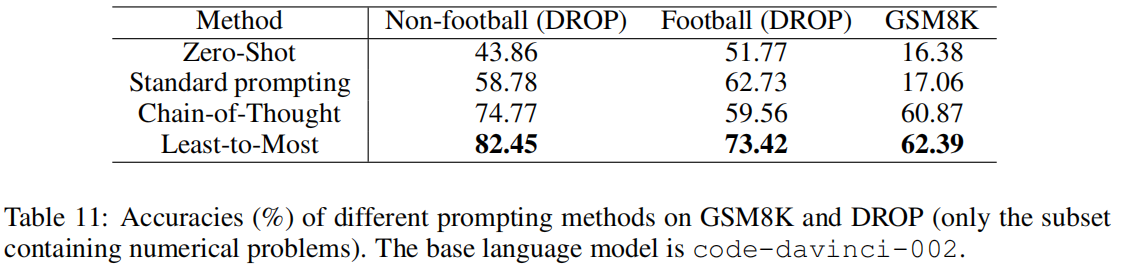

Compositional Semantic Parsing with Large Language Models
Google Research + UMass Amherst CICS
- Motivation:
- SCAN is an artificial task built upon a synthetic language with a tiny vocabulary and is generated from a small set of grammar rules, and it is unclear whether least-to-most prompting‘s strong results transfer to more realistic tasks that are based on a larger vocabulary and more complicated grammars.
- decomposing a problem is more difficult.
- translation of constituents is context-dependent.
- Methods:
dynamic least-to-most prompting
(1) tree-structured decomposition of natural language inputs through LM-predicted syntactic parsing; 通过lm预测的语法解析对自然语言输入进行树结构分解;
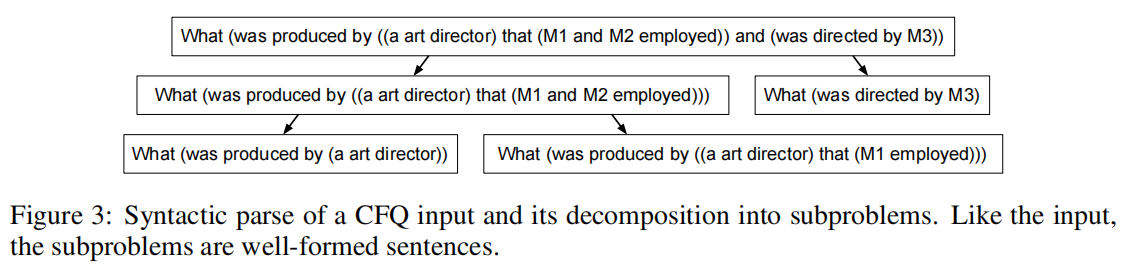
(2) use the decomposition to dynamically select exemplars; 使用分解动态选择范例;
- Top-down matching: anonymize the decomposition tree of the input; Starting at the top of the anonymized tree, we use a heuristic approach to find exemplars such that all nodes are covered, prioritizing exemplars that match large subtrees.
- Bottom-up matching: Then, we try to make sure that all leaf phrases are covered by an exemplar. If there is more than one exemplar for a certain phrase, we prefer exemplars where the phrase occurs within a similar anonymized subtree.
(3) linearize the decomposition tree and prompt the model to sequentially generate answers to subproblems. 将分解树线性化,并提示模型按顺序生成子问题的答案。
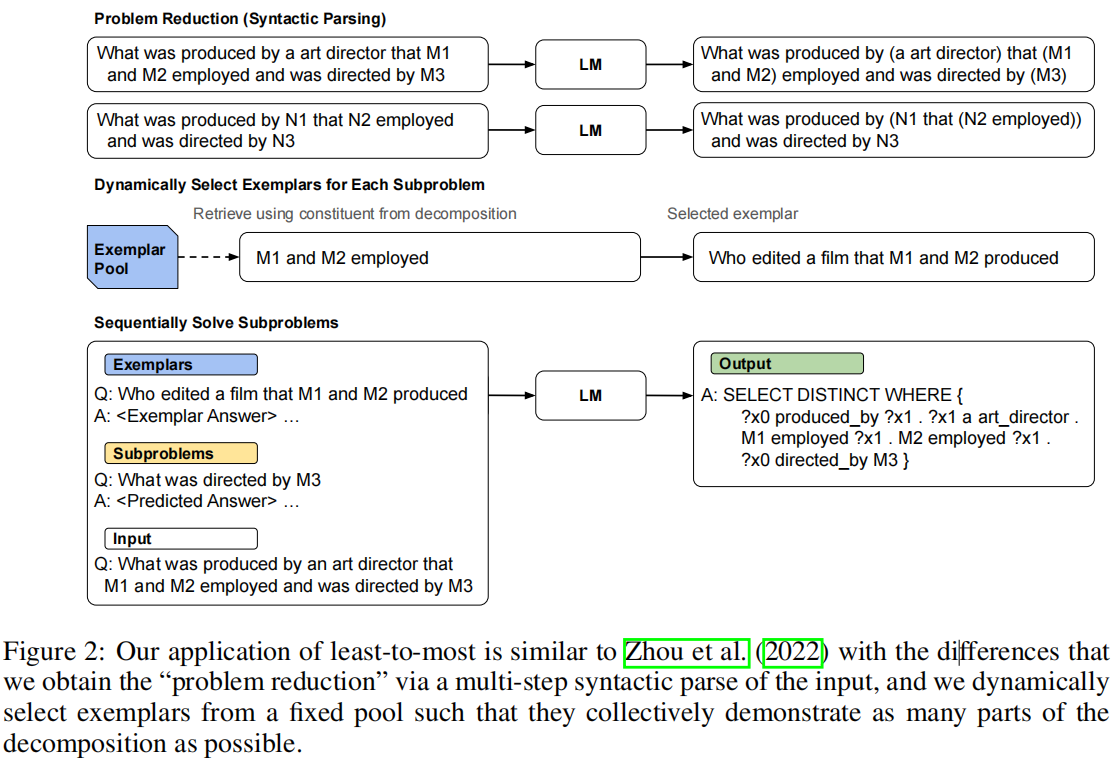
- Experiments:
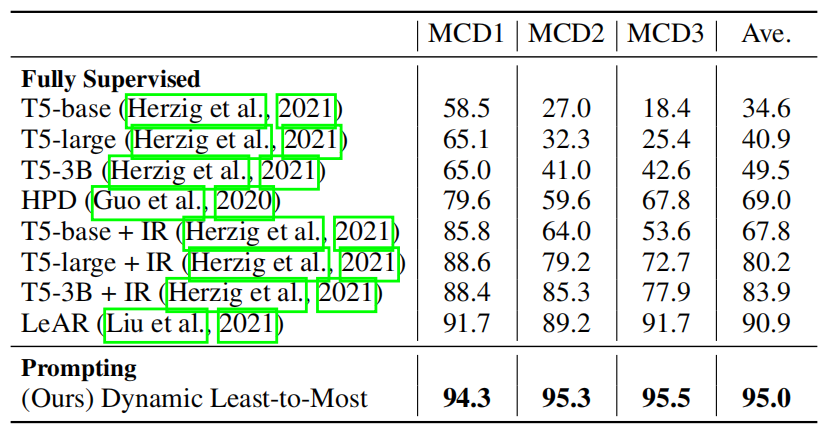
- CFQ

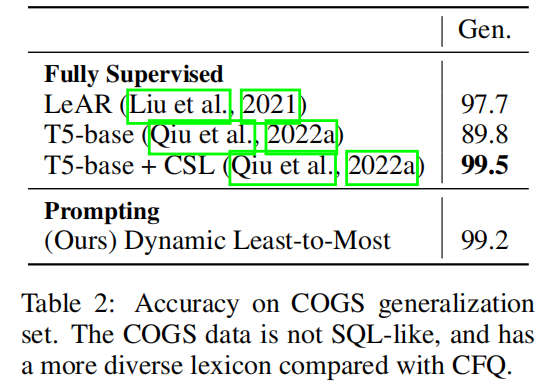
- COGS
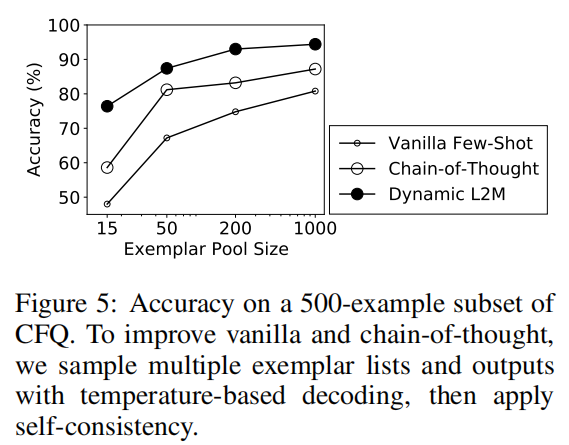
- Is dynamic least-to-most more effective than other prompting methods? & How many exemplars are needed in the pool?
Measuring and Narrowing the Compositionality Gap in Language Models
Paul G. Allen School of Computer Science & Engineering, University of Washington
code : https://github.com/ofirpress/self-ask
- Motivation:
- SCAN is an artificial task built upon a synthetic language with a tiny vocabulary and is generated from a small set of grammar rules, and it is unclear whether least-to-most prompting‘s strong results transfer to more realistic tasks that are based on a larger vocabulary and more complicated grammars.
- decomposing a problem is more difficult.
- translation of constituents is context-dependent.
- Methods:
dynamic least-to-most prompting
(1) tree-structured decomposition of natural language inputs through LM-predicted syntactic parsing; 通过lm预测的语法解析对自然语言输入进行树结构分解;
(2) use the decomposition to dynamically select exemplars; 使用分解动态选择范例;
- Top-down matching: anonymize the decomposition tree of the input; Starting at the top of the anonymized tree, we use a heuristic approach to find exemplars such that all nodes are covered, prioritizing exemplars that match large subtrees.
- Bottom-up matching: Then, we try to make sure that all leaf phrases are covered by an exemplar. If there is more than one exemplar for a certain phrase, we prefer exemplars where the phrase occurs within a similar anonymized subtree.
(3) linearize the decomposition tree and prompt the model to sequentially generate answers to subproblems. 将分解树线性化,并提示模型按顺序生成子问题的答案。
- Experiments:
- CFQ
- COGS
- Is dynamic least-to-most more effective than other prompting methods? & How many exemplars are needed in the pool?
STaR: Bootstrapping Reasoning With Reasoning
Making Large Language Models Better Reasoners with Step-Aware Verifier
Language Models are Multilingual Chain-of-Thought Reasoners
Chain of Thought Prompting Elicits Knowledge Augmentation
Tsinghua + Ruc ACL Findings 2023
- Motivation:
- Conventional knowledge-augmented deep learning methods typically employ task-specific approaches to gather external knowledge from various sources;
- In contrast, large language models are extensively pre-trained and can serve as a comprehensive source of external knowledge.
- Methods:
- CoT-KA, a Chain-of-Thought-based method that augments knowledge for deep learning. CoT-KA avoids the need for additional knowledge retrieval or knowledge reasoning models.
- (1) CoT Generation: Generating multiple CoTs for each sample in the train, dev, and test sets.
- (2) Input Augmentation: Taking the generated CoTs as the additional knowledge into the original input text for each sample.
- (3) Task-relevant Model Training: Fine-tuning a task-relevant model using the CoT-augmented samples.
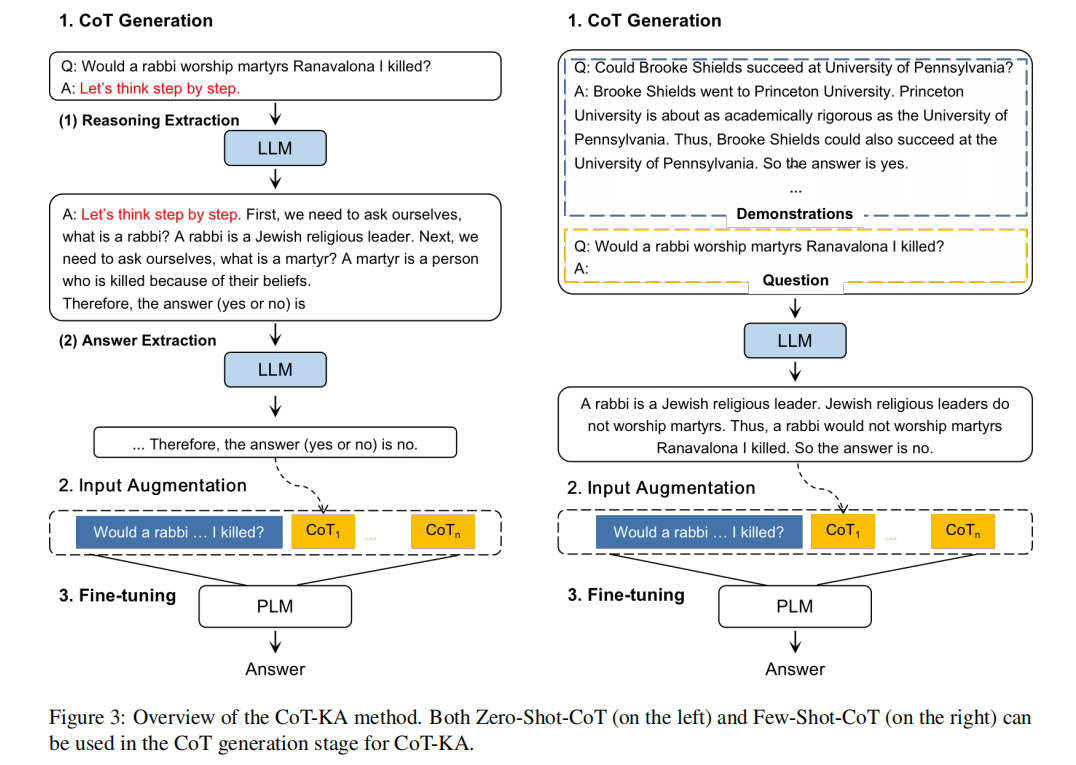
- Experiments:
NLU tasks
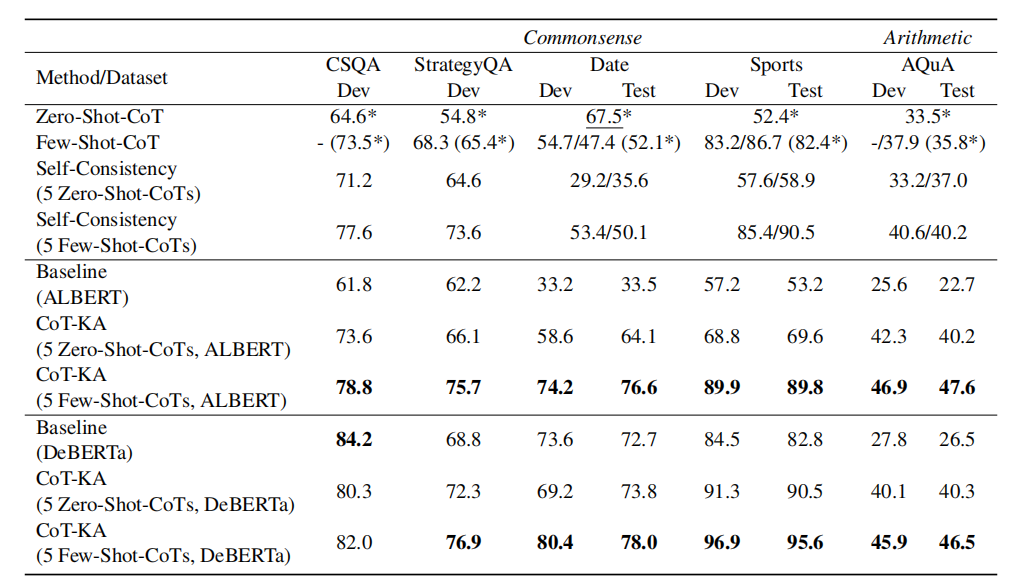
NLG tasks
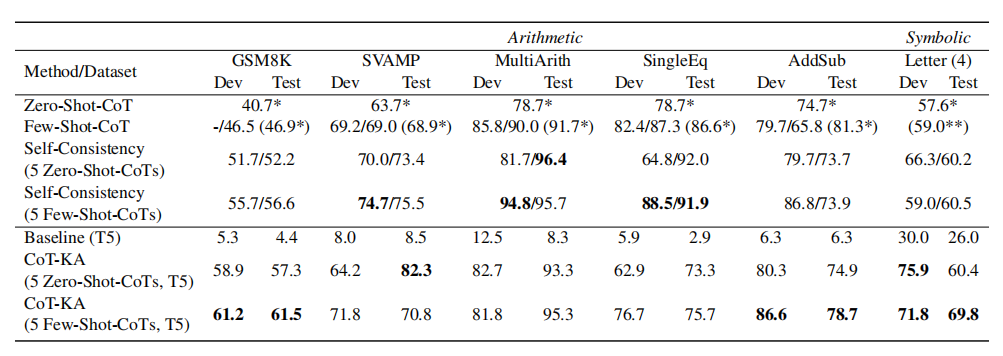
explore the effectiveness of CoT-augmented fine-tuning by simply appending one CoT to the original input. GPT-3 (text-davinci-002)
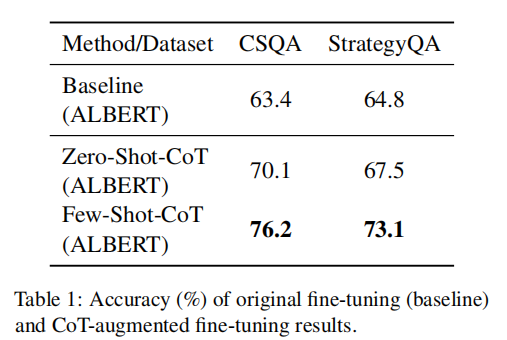
Given that the answers within CoTs can potentially be incorrect, we hypothesize that this portion of the CoTs will have a negative effect on the fine-tuning and mislead the model’s prediction.
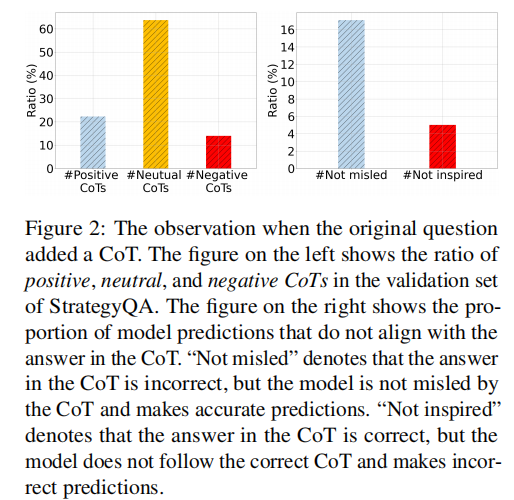
Knowledge Augmentation Comparison
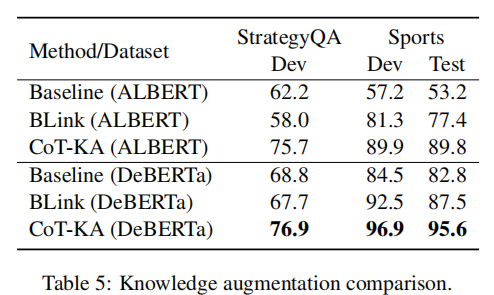
The Effect of CoT Size
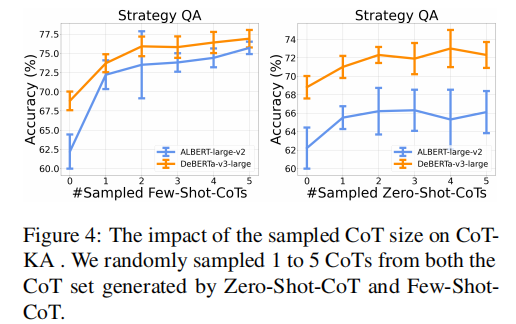
CoT Selection Strategy

Original link: http://example.com/2023/07/18/Prompt-Engineering/
Copyright Notice: 转载请注明出处.