Maven
版本:3.6.3
项目构建和依赖管理工具
Maven简介和快速入门
介绍
- Maven 是一款为 Java 项目构建管理、依赖管理的工具(软件),使用 Maven 可以自动化构建、测试、打包和发布项目,大大提高了开发效率和质量。
主要作用
- 依赖管理:Maven 可以管理项目的依赖,包括自动下载所需依赖库、自动下载依赖需要的依赖并且保证版本没有冲突、依赖版本管理等。通过 Maven,我们可以方便地维护项目所依赖的外部库,而我们仅仅需要编写配置即可。
- 构建管理:Maven 可以管理项目的编译、测试、打包、部署等构建过程。通过实现标准的构建生命周期,Maven 可以确保每一个构建过程都遵循同样的规则和最佳实践。同时,Maven 的插件机制也使得开发者可以对构建过程进行扩展和定制。主动触发构建,只需要简单的命令操作即可。
注:项目构建是指将源代码、配置文件、资源文件等转化为能够运行或部署的应用程序或库的过程!
安装与配置
修改maven/conf/settings.xml配置文件:1.依赖本地缓存位置(本地仓库位置) 2.maven下载镜像 3.maven选用编译项目的jdk版本
基于IDEA的Maven工程创建
Maven工程的GAVP属性
GAVP 是指 GroupId、ArtifactId、Version、Packaging 等四个属性的缩写,其中前三个是必要的,而 Packaging 属性为可选项。gav需要我们在创建项目的时指定,p有默认值,后期通过配置文件修改。
GAV规则:
- GroupID 格式:com.{公司/BU }.业务线.{子业务线},最多 4 级。
- ArtifactID 格式:产品线名-模块名。语义不重复不遗漏,先到仓库中心去查证一下。
- Version版本号格式推荐:主版本号.次版本号.修订号 1.0.0
Packaging定义规则:
- packaging 属性为 jar(默认值),代表普通的Java工程,打包以后是.jar结尾的文件。
- packaging 属性为 war,代表Java的web工程,打包以后.war结尾的文件。
- packaging 属性为 pom,代表不会打包,用来做继承的父工程。
Maven工程项目结构说明
1 | |-- pom.xml # Maven 项目管理文件 |
- pom.xml:Maven 项目管理文件,用于描述项目的依赖和构建配置等信息。
- src/main/java:存放项目的 Java 源代码。
- src/main/resources:存放项目的资源文件,如配置文件、静态资源等。
- src/main/webapp/WEB-INF:存放 Web 应用的配置文件。
- src/main/webapp/index.html:Web 应用的入口页面。
- src/test/java:存放项目的测试代码。
- src/test/resources:存放测试相关的资源文件,如测试配置文件等。
Maven核心功能依赖和构建管理
依赖管理和配置
Maven 依赖管理是 Maven 软件中最重要的功能之一。Maven 的依赖管理能够帮助开发人员自动解决软件包依赖问题,使得开发人员能够轻松地将其他开发人员开发的模块或第三方框架集成到自己的应用程序或模块中,避免出现版本冲突和依赖缺失等问题。
我们通过定义 POM 文件,Maven 能够自动解析项目的依赖关系,并通过 Maven **仓库自动**下载和管理依赖,从而避免了手动下载和管理依赖的繁琐工作和可能引发的版本冲突问题。
重点: 编写pom.xml文件!
1 | <!-- |
依赖版本提取和维护:
1 | <!--声明版本--> |
依赖传递和冲突
依赖传递指的是当一个模块或库 A 依赖于另一个模块或库 B,而 B 又依赖于模块或库 C,那么 A 会间接依赖于 C。这种依赖传递结构可以形成一个依赖树。当我们引入一个库或框架时,构建工具(如 Maven、Gradle)会自动解析和加载其所有的直接和间接依赖,确保这些依赖都可用。
依赖传递的作用是:
- 减少重复依赖:当多个项目依赖同一个库时,Maven 可以自动下载并且只下载一次该库。这样可以减少项目的构建时间和磁盘空间。
- 自动管理依赖: Maven 可以自动管理依赖项,使用依赖传递,简化了依赖项的管理,使项目构建更加可靠和一致。
- 确保依赖版本正确性:通过依赖传递的依赖,之间都不会存在版本兼容性问题,确保依赖的版本正确性!
依赖冲突:发现已经存在依赖(重复依赖)会终止依赖传递,避免循环依赖和重复依赖的问题。
maven自动解决依赖冲突问题能力,会按照自己的原则,进行重复依赖选择。同时也提供了手动解决的冲突的方式,不过不推荐!
解决依赖冲突(如何选择重复依赖)方式:
- 短路优先原则(第一原则)
A—>B—>C—>D—>E—>X(version 0.0.1)
A—>F—>X(version 0.0.2)
则A依赖于X(version 0.0.2)。
- 依赖路径长度相同情况下,则“先声明优先”(第二原则)
A—>E—>X(version 0.0.1)
A—>F—>X(version 0.0.2)
在<depencies></depencies>中,先声明的,路径相同,会优先选择!
思考:
1 | 前提: |
依赖导入失败场景和解决方案
在使用 Maven 构建项目时,可能会发生依赖项下载错误的情况,主要原因有以下几种:
- 下载依赖时出现网络故障或仓库服务器宕机等原因,导致无法连接至 Maven 仓库,从而无法下载依赖。
- 依赖项的版本号或配置文件中的版本号错误,或者依赖项没有正确定义,导致 Maven 下载的依赖项与实际需要的不一致,从而引发错误。
- 本地 Maven 仓库或缓存被污染或损坏,导致 Maven 无法正确地使用现有的依赖项,并且也无法重新下载!
解决方案:
检查网络连接和 Maven 仓库服务器状态。
确保依赖项的版本号与项目对应的版本号匹配,并检查 POM 文件中的依赖项是否正确。
清除本地 Maven 仓库缓存(lastUpdated 文件),因为只要存在lastupdated缓存文件,刷新也不会重新下载。本地仓库中,根据依赖的gav属性依次向下查找文件夹,最终删除内部的文件,刷新重新下载即可!
例如: pom.xml依赖
扩展构建管理和插件配置
构建概念:
项目构建是指将源代码、依赖库和资源文件等转换成可执行或可部署的应用程序的过程,在这个过程中包括编译源代码、链接依赖库、打包和部署等多个步骤。
清理→编译→测试→报告→打包→部署
主动触发场景:
- 重新编译 : 编译不充分, 部分文件没有被编译!
- 打包 : 独立部署到外部服务器软件,打包部署
- 部署本地或者私服仓库 : maven工程加入到本地或者私服仓库,供其他工程使用
命令方式构建:
语法: mvn 构建命令 构建命令….(1.命执行需要我们进入到项目的根路径,pom.xml平级;2.部署必须是jar包形式)
| 命令 | 描述 |
|---|---|
| mvn clean | 清理编译或打包后的项目结构,删除target文件夹 |
| mvn compile | 编译项目,生成target文件 |
| mvn test | 执行测试源码 (测试) |
| mvn site | 生成一个项目依赖信息的展示页面 |
| mvn package | 打包项目,生成war / jar 文件 |
| mvn install | 打包后上传到maven本地仓库(本地部署) |
| mvn deploy | 只打包,上传到maven私服仓库(私服部署) |
可视化方式构建:
IDE中的Maven界面,lifestyle。
构建命令周期:
构建生命周期可以理解成是一组固定构建命令的有序集合,触发周期后的命令,会自动触发周期前的命令!也是一种简化构建的思路!
清理周期:主要是对项目编译生成文件进行清理
包含命令:clean
构建周期:定义了真正构件时所需要执行的所有步骤,它是生命周期中最核心的部分
包含命令:compile - test - package - install / deploy
报告周期
包含命令:site
打包: mvn clean package 本地仓库: mvn clean install
最佳使用方案:
1 | 打包: mvn clean package |
周期,命令和插件:
周期→包含若干命令→包含若干插件!
使用周期命令构建,简化构建过程!
最终进行构建的是插件!
插件配置:
1 | <build> |
Maven继承和聚合特性
Maven工程继承关系
继承概念
Maven 继承是指在 Maven 的项目中,让一个项目从另一个项目中继承配置信息的机制。继承可以让我们在多个项目中共享同一配置信息,简化项目的管理和维护工作。继承作用
作用:在父工程中统一管理项目中的依赖信息,进行统一版本管理!
它的背景是:- 对一个比较大型的项目进行了模块拆分。
- 一个 project 下面,创建了很多个 module。
- 每一个 module 都需要配置自己的依赖信息。
它背后的需求是:
- 多个模块要使用同一个框架,它们应该是同一个版本,所以整个项目中使用的框架版本需要统一管理。
- 使用框架时所需要的 jar 包组合(或者说依赖信息组合)需要经过长期摸索和反复调试,最终确定一个可用组合。这个耗费很大精力总结出来的方案不应该在新的项目中重新摸索。
通过在父工程中为整个项目维护依赖信息的组合既保证了整个项目使用规范、准确的 jar 包;又能够将以往的经验沉淀下来,节约时间和精力。
继承语法
- 父工程
1 | <groupId>com.wzh.maven</groupId> |
- 子工程
1 | <!-- 使用parent标签指定当前工程的父工程 --> |
- 父工程依赖统一管理
- 父工程声明版本
1 | <!-- 使用dependencyManagement标签配置对依赖的管理 --> |
- 子工程引用版本
1 | <!-- 子工程引用父工程中的依赖信息时,可以把版本号去掉。 --> |
Maven工程聚合关系
- 聚合概念
Maven 聚合是指将多个项目组织到一个父级项目中,通过触发父工程的构建,统一按顺序触发子工程构建的过程!! - 聚合作用
- 统一管理子项目构建:通过聚合,可以将多个子项目组织在一起,方便管理和维护。
- 优化构建顺序:通过聚合,可以对多个项目进行顺序控制,避免出现构建依赖混乱导致构建失败的情况。
- 聚合语法
父项目中包含的子项目列表。
1 | <project> |
- 聚合演示
通过触发父工程构建命令、引发所有子模块构建!产生反应堆!
Spring
版本:6.0.6
Ioc和AOP以及TX
技术体系结构
总体技术体系
单一架构
一个项目,一个工程,导出为一个war包,在一个Tomcat上运行。也叫all in one。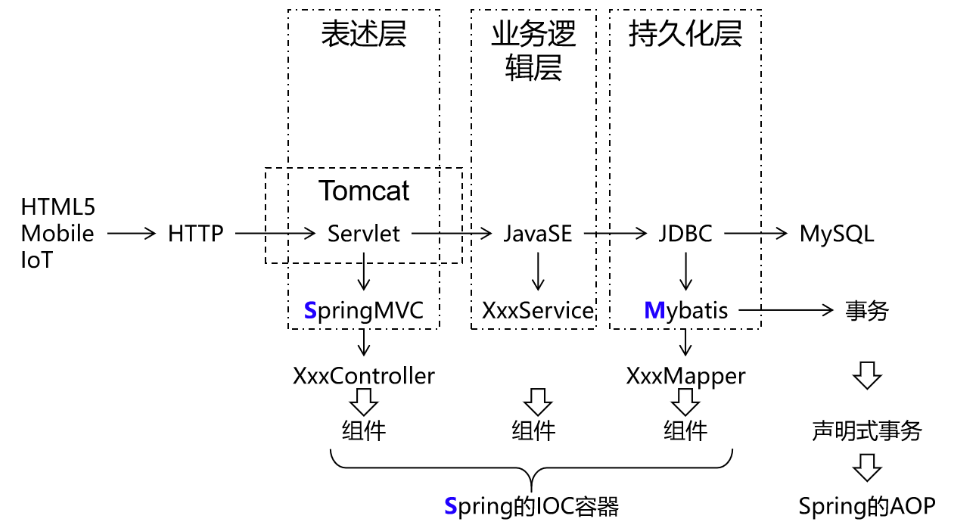
单一架构,项目主要应用技术框架为:Spring , SpringMVC , Mybatis
分布式架构
一个项目(对应 IDEA 中的一个 project),拆分成很多个模块,每个模块是一个 IDEA 中的一个 module。每一个工程都是运行在自己的 Tomcat 上。模块之间可以互相调用。每一个模块内部可以看成是一个单一架构的应用。
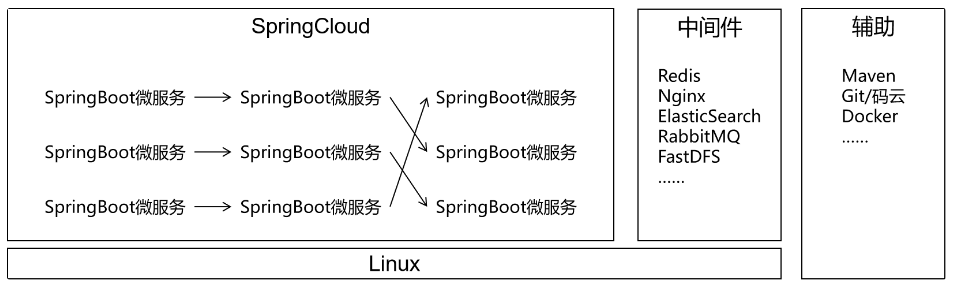
分布式架构,项目主要应用技术框架:SpringBoot (SSM), SpringCloud , 中间件等
框架概念和理解
框架( Framework )是一个集成了基本结构、规范、设计模式、编程语言和程序库等基础组件的软件系统,它可以用来构建更高级别的应用程序。框架的设计和实现旨在解决特定领域中的常见问题,帮助开发人员更高效、更稳定地实现软件开发目标。- 优点:1)提高开发效率;2)降低开发成本;3)提高应用程序的稳定性;4)提供标准化的解决方案。
- 缺点:1)学习成本高;2)可能存在局限性;3)版本变更和兼容性问题;4)架构风险。
站在文件结构的角度理解框架,可以将框架总结:框架 = jar包+配置文件
SpringFramework介绍
Spring和SpringFramework概念
- 广义的Spring:以 Spring Framework 为基础的 Spring 技术栈(全家桶)
- 狭义的Spring:Spring Framework
SpringFramework主要功能模块
SpringFramework框架结构图:
| 功能模块 | 功能介绍 |
|---|---|
| Core Container | 核心容器,在 Spring 环境下使用任何功能都必须基于 IOC 容器。 |
| AOP&Aspects | 面向切面编程 |
| TX | 声明式事务管理。 |
| Spring MVC | 提供了面向Web应用程序的集成功能。 |
SpringFramework主要优势
- 丰富的生态系统:Spring 生态系统非常丰富,支持许多模块和库,如 Spring Boot、Spring Security、Spring Cloud 等等,可以帮助开发人员快速构建高可靠性的企业应用程序。
- 模块化的设计:框架组件之间的松散耦合和模块化设计使得 Spring Framework 具有良好的可重用性、可扩展性和可维护性。开发人员可以轻松地选择自己需要的模块,根据自己的需求进行开发。
- 简化 Java 开发:Spring Framework 简化了 Java 开发,提供了各种工具和 API,可以降低开发复杂度和学习成本。同时,Spring Framework 支持各种应用场景,包括 Web 应用程序、RESTful API、消息传递、批处理等等。
- 不断创新和发展:Spring Framework 开发团队一直在不断创新和发展,保持与最新技术的接轨,为开发人员提供更加先进和优秀的工具和框架。
Spring IoC容器和核心概念
组件和组件管理概念
Spring充当组件管理角色(IoC)
组件可以完全交给Spring 框架进行管理,Spring框架替代了程序员原有的new对象和对象属性赋值动作等!Spring具体的组件管理动作包含:
- 组件对象实例化
- 组件属性属性赋值
- 组件对象之间引用
- 组件对象存活周期管理
- ……
我们只需要编写元数据(配置文件)告知Spring 管理哪些类组件和他们的关系即可!
注意:组件是映射到应用程序中所有可重用组件的Java对象,应该是可复用的功能对象!
- 组件一定是对象
- 对象不一定是组件
综上所述,Spring 充当一个组件容器,创建、管理、存储组件,减少了我们的编码压力,让我们更加专注进行业务编写!
组件交给Spring管理优势!
- 降低了组件之间的耦合性:Spring IoC容器通过依赖注入机制,将组件之间的依赖关系削弱,减少了程序组件之间的耦合性,使得组件更加松散地耦合。
- 提高了代码的可重用性和可维护性:将组件的实例化过程、依赖关系的管理等功能交给Spring IoC容器处理,使得组件代码更加模块化、可重用、更易于维护。
- 方便了配置和管理:Spring IoC容器通过XML文件或者注解,轻松的对组件进行配置和管理,使得组件的切换、替换等操作更加的方便和快捷。
- 交给Spring管理的对象(组件),方可享受Spring框架的其他功能(AOP,声明事务管理)等
Spring IoC容器和容器实现
普通和复杂容器
普通容器- 数组
- 集合:List
- 集合:Set
复杂容器
- Servlet 容器能够管理 Servlet(init,service,destroy)、Filter、Listener 这样的组件的一生,所以它是一个复杂容器。
- SpringIoC 容器也是一个复杂容器。它们不仅要负责创建组件的对象、存储组件的对象,还要负责调用组件的方法让它们工作,最终在特定情况下销毁组件。
总结:Spring管理组件的容器,就是一个复杂容器,不仅存储组件,也可以管理组件之间依赖关系,并且创建和销毁组件等!
SpringIoC容器介绍
Spring IoC 容器,负责实例化、配置和组装 bean(组件)。容器通过读取配置元数据来获取有关要实例化、配置和组装组件的指令。配置元数据以 XML、Java 注解或 Java 代码形式表现。它允许表达组成应用程序的组件以及这些组件之间丰富的相互依赖关系。
SpringIoC容器具体接口和实现类
SpringIoc容器接口:
BeanFactory接口提供了一种高级配置机制,能够管理任何类型的对象,它是SpringIoC容器标准化超接口!ApplicationContext是BeanFactory的子接口。它扩展了以下功能:- 更容易与 Spring 的 AOP 功能集成
- 消息资源处理(用于国际化)
- 特定于应用程序给予此接口实现,例如Web 应用程序的
WebApplicationContext
简而言之,
BeanFactory提供了配置框架和基本功能,而ApplicationContext添加了更多特定于企业的功能。ApplicationContext是BeanFactory的完整超集!ApplicationContext容器实现类:
| 类型名 | 简介 |
|---|---|
| ClassPathXmlApplicationContext | 通过读取类路径下的 XML 格式的配置文件创建 IOC 容器对象 |
| FileSystemXmlApplicationContext | 通过文件系统路径读取 XML 格式的配置文件创建 IOC 容器对象 |
| AnnotationConfigApplicationContext | 通过读取Java配置类创建 IOC 容器对象 |
| WebApplicationContext | 专门为 Web 应用准备,基于 Web 环境创建 IOC 容器对象,并将对象引入存入 ServletContext 域中。 |
SpringIoC容器管理配置方式
Spring IoC 容器使用多种形式的配置元数据。此配置元数据表示您作为应用程序开发人员如何告诉 Spring 容器实例化、配置和组装应用程序中的对象。
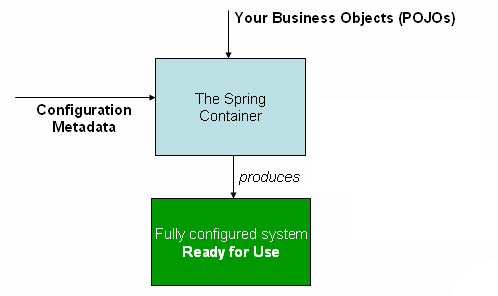
Spring框架提供了多种配置方式:XML配置方式、注解方式和Java配置类方式
- XML配置方式:是Spring框架最早的配置方式之一,通过在XML文件中定义Bean及其依赖关系、Bean的作用域等信息,让Spring IoC容器来管理Bean之间的依赖关系。该方式从Spring框架的第一版开始提供支持。
- 注解方式:从Spring 2.5版本开始提供支持,可以通过在Bean类上使用注解来代替XML配置文件中的配置信息。通过在Bean类上加上相应的注解(如@Component, @Service, @Autowired等),将Bean注册到Spring IoC容器中,这样Spring IoC容器就可以管理这些Bean之间的依赖关系。
- ** Java配置类**方式:从Spring 3.0版本开始提供支持,通过Java类来定义Bean、Bean之间的依赖关系和配置信息,从而代替XML配置文件的方式。Java配置类是一种使用Java编写配置信息的方式,通过@Configuration、@Bean等注解来实现Bean和依赖关系的配置。
为了迎合当下开发环境,我们将以配置类+注解方式为主进行讲解!
Spring IoC / DI概念总结
IoC容器
Spring IoC 容器,负责实例化、配置和组装 bean(组件)核心容器。容器通过读取配置元数据来获取有关要实例化、配置和组装组件的指令。
IoC(Inversion of Control)控制反转
IoC 主要是针对对象的创建和调用控制而言的,也就是说,当应用程序需要使用一个对象时,不再是应用程序直接创建该对象,而是由 IoC 容器来创建和管理,即控制权由应用程序转移到 IoC 容器中,也就是“反转”了控制权。这种方式基本上是通过依赖查找的方式来实现的,即 IoC 容器维护着构成应用程序的对象,并负责创建这些对象。
DI (Dependency Injection) 依赖注入
DI 是指在组件之间传递依赖关系的过程中,将依赖关系在容器内部进行处理,这样就不必在应用程序代码中硬编码对象之间的依赖关系,实现了对象之间的解耦合。在 Spring 中,DI 是通过 XML 配置文件或注解的方式实现的。它提供了三种形式的依赖注入:构造函数注入、Setter 方法注入和接口注入。
Spring IoC实践和应用
Spring IoC / DI 实现步骤
我们总结下,组件交给Spring IoC容器管理,并且获取和使用的基本步骤!
配置元数据(配置)
配置元数据,既是编写交给SpringIoC容器管理组件的信息,配置方式有三种。
基于 XML 的配置元数据的基本结构:
<bean id=”…” [1] class=”…” [2]>
<!-- collaborators and configuration for this bean go here -->
1 |
|
Spring IoC 容器管理一个或多个组件。这些组件是使用你提供给容器的配置元数据(例如,以 XML `<bean/>` 定义的形式)创建的。
<bean /> 标签 == 组件信息声明
- `id` 属性是标识单个 Bean 定义的字符串。
- `class` 属性定义 Bean 的类型并使用完全限定的类名。
实例化IoC容器
提供给
ApplicationContext构造函数的位置路径是资源字符串地址,允许容器从各种外部资源(如本地文件系统、JavaCLASSPATH等)加载配置元数据。我们应该选择一个合适的容器实现类,进行IoC容器的实例化工作:
1 | //实例化ioc容器,读取外部配置文件,最终会在容器内进行ioc和di动作 |
获取Bean(组件)
ApplicationContext是一个高级工厂的接口,能够维护不同 bean 及其依赖项的注册表。通过使用方法T getBean(String name, Class<T> requiredType),您可以检索 bean 的实例。允许读取 Bean 定义并访问它们,如以下示例所示:
1 | //创建ioc容器对象,指定配置文件,ioc也开始实例组件对象 |
基于XML配置方式组件管理
组件(Bean)信息声明配置(IoC)
- 基于无参数构造函数
当通过构造函数方法创建一个 bean(组件对象) 时,所有普通类都可以由 Spring 使用并与之兼容。也就是说,正在开发的类不需要实现任何特定的接口或以特定的方式进行编码。只需指定 Bean 类信息就足够了。但是,默认情况下,我们需要一个默认(空)构造函数。
1
2<!-- 实验一 [重要]创建bean -->
<bean id="happyComponent" class="com.wzh.ioc.HappyComponent"/>- bean标签:通过配置bean标签告诉IOC容器需要创建对象的组件信息 - id属性:bean的唯一标识,方便后期获取Bean! - class属性:组件类的全限定符! - 注意:要求当前组件类必须包含无参数构造函数! - 基于静态工厂方法实例化
除了使用构造函数实例化对象,还有一类是通过工厂模式实例化对象。接下来我们讲解如何定义使用静态工厂方法创建Bean的配置 !
1 | public class ClientService { |
1 | <bean id="clientService" |
- class属性:指定工厂类的全限定符!
- factory-method: 指定静态工厂方法,注意,该方法必须是static方法。
- 基于实例工厂方法实例化
接下来我们讲解下如何定义使用实例工厂方法创建Bean的配置 !
1
2
3
4
5
6
7
8public class DefaultServiceLocator {
private static ClientServiceImplclientService = new ClientServiceImpl();
public ClientService createClientServiceInstance() {
return clientService;
}
}1
2
3
4
5
6
7
8<!-- 将工厂类进行ioc配置 -->
<bean id="serviceLocator" class="examples.DefaultServiceLocator">
</bean>
<!-- 根据工厂对象的实例工厂方法进行实例化组件对象 -->
<bean id="clientService"
factory-bean="serviceLocator"
factory-method="createClientServiceInstance"/>- factory-bean属性:指定当前容器中工厂Bean 的名称。 - factory-method: 指定实例工厂方法名。注意,实例方法必须是非static的!
组件(Bean)依赖注入配置(DI)
- 通过配置文件,实现IoC容器中Bean之间的引用(依赖注入DI配置)。主要涉及注入场景:基于构造函数的依赖注入和基于 Setter 的依赖注入。
- 基于构造函数的依赖注入
1 | public class UserDao { |
1 | <beans> |
- constructor-arg标签:可以引用构造参数 ref引用其他bean的标识。
- 基于构造函数的依赖注入(多构造参数解析)
1 | public class UserDao { |
1 | <!-- 场景1: 多参数,可以按照相应构造函数的顺序注入数据 --> |
- constructor-arg标签:指定构造参数和对应的值
- constructor-arg标签:name属性指定参数名、index属性指定参数角标、value属性指定普通属性值
- 基于Setter方法依赖注入
1 | public Class MovieFinder{ |
1 | <bean id="simpleMovieLister" class="examples.SimpleMovieLister"> |
- property标签: 可以给setter方法对应的属性赋值
- property 标签: name属性代表**set方法标识**、ref代表引用bean的标识id、value属性代表基本属性值
IoC容器创建和使用
- 容器实例化
1 | //方式1:实例化并且指定配置文件 |
- Bean对象读取
1 | //方式1: 根据id获取 |
高级特性:组件(Bean)作用域和周期方法配置
- 组件周期方法配置
我们可以在组件类中定义方法,然后当IoC容器实例化和销毁组件对象的时候进行调用!这两个方法我们称为生命周期方法!类似于Servlet的init/destroy方法,我们可以在周期方法完成初始化和释放资源等工作。
1 | public class BeanOne { |
- 周期方法配置
1 | <beans> |
- 组件作用域配置
Bean作用域概念
<bean标签声明Bean,只是将Bean的信息配置给SpringIoC容器!在IoC容器中,这些
<bean标签对应的信息转成Spring内部BeanDefinition对象,BeanDefinition对象内,包含定义的信息(id,class,属性等等)!这意味着,
BeanDefinition与类概念一样,SpringIoC容器可以可以根据BeanDefinition对象反射创建多个Bean对象实例。具体创建多少个Bean的实例对象,由Bean的作用域Scope属性指定!
作用域可选值
| 取值 | 含义 | 创建对象的时机 | 默认值 |
|---|---|---|---|
| singleton | 在 IOC 容器中,这个 bean 的对象始终为单实例 | IOC 容器初始化时 | 是 |
| prototype | 这个 bean 在 IOC 容器中有多个实例 | 获取 bean 时 | 否 |
如果是在WebApplicationContext环境下还会有另外两个作用域(但不常用):
| 取值 | 含义 | 创建对象的时机 | 默认值 |
|---|---|---|---|
| request | 请求范围内有效的实例 | 每次请求 | 否 |
| session | 会话范围内有效的实例 | 每次会话 | 否 |
- 作用域配置
1 | <!--bean的作用域 |
高级特性:FactoryBean特性和使用
FactoryBean简介
FactoryBean接口是Spring IoC容器实例化逻辑的可插拔性点。用于配置复杂的Bean对象,可以将创建过程存储在
FactoryBean的getObject方法!FactoryBean<T>接口提供三种方法:T getObject():返回此工厂创建的对象的实例。该返回值会被存储到IoC容器!
boolean isSingleton():如果此
FactoryBean返回单例,则返回true,否则返回false。此方法的默认实现返回true(注意,lombok插件使用,可能影响效果)。Class<?> getObjectType(): 返回getObject()方法返回的对象类型,如果事先不知道类型,则返回null。
FactoryBean使用场景
- 代理类的创建
- 第三方框架整合
- 复杂对象实例化等
Factorybean应用
- 准备FactoryBean实现类
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32// 实现FactoryBean接口时需要指定泛型
// 泛型类型就是当前工厂要生产的对象的类型
public class HappyFactoryBean implements FactoryBean<HappyMachine> {
private String machineName;
public String getMachineName() {
return machineName;
}
public void setMachineName(String machineName) {
this.machineName = machineName;
}
public HappyMachine getObject() throws Exception {
// 方法内部模拟创建、设置一个对象的复杂过程
HappyMachine happyMachine = new HappyMachine();
happyMachine.setMachineName(this.machineName);
return happyMachine;
}
public Class<?> getObjectType() {
// 返回要生产的对象的类型
return HappyMachine.class;
}
} - 配置FactoryBean实现类
1
2
3
4
5
6<!-- FactoryBean机制 -->
<!-- 这个bean标签中class属性指定的是HappyFactoryBean,但是将来从这里获取的bean是HappyMachine对象 -->
<bean id="happyMachine7" class="com.wzh.ioc.HappyFactoryBean">
<!-- property标签仍然可以用来通过setXxx()方法给属性赋值 -->
<property name="machineName" value="iceCreamMachine"/>
</bean> - 测试读取FactoryBean和FactoryBean.getObject对象
1
2
3
4
5
6
7
8
9
10
11
12
13
public void testExperiment07() {
ApplicationContext iocContainer = new ClassPathXmlApplicationContext("spring-bean-07.xml");
//注意: 直接根据声明FactoryBean的id,获取的是getObject方法返回的对象
HappyMachine happyMachine = iocContainer.getBean("happyMachine7",HappyMachine.class);
System.out.println("happyMachine = " + happyMachine);
//如果想要获取FactoryBean对象, 直接在id前添加&符号即可! &happyMachine7 这是一种固定的约束
Object bean = iocContainer.getBean("&happyMachine7");
System.out.println("bean = " + bean);
}- FactoryBean和BeanFactory区别
**FactoryBean **是 Spring 中一种特殊的 bean,可以在 getObject() 工厂方法自定义的逻辑创建Bean!是一种能够生产其他 Bean 的 Bean。FactoryBean 在容器启动时被创建,而在实际使用时则是通过调用 getObject() 方法来得到其所生产的 Bean。因此,FactoryBean 可以自定义任何所需的初始化逻辑,生产出一些定制化的 bean。
一般情况下,整合第三方框架,都是通过定义FactoryBean实现!!!
BeanFactory 是 Spring 框架的基础,其作为一个顶级接口定义了容器的基本行为,例如管理 bean 的生命周期、配置文件的加载和解析、bean 的装配和依赖注入等。BeanFactory 接口提供了访问 bean 的方式,例如 getBean() 方法获取指定的 bean 实例。它可以从不同的来源(例如 Mysql 数据库、XML 文件、Java 配置类等)获取 bean 定义,并将其转换为 bean 实例。同时,BeanFactory 还包含很多子类(例如,ApplicationContext 接口)提供了额外的强大功能。
总的来说,FactoryBean 和 BeanFactory 的区别主要在于前者是用于创建 bean 的接口,它提供了更加灵活的初始化定制功能,而后者是用于管理 bean 的框架基础接口,提供了基本的容器功能和 bean 生命周期管理。
- 准备FactoryBean实现类
基于XML方式整合三层架构组件
1 |
|
XML-IoC方式问题总结
1. 注入的属性必须添加setter方法、代码结构乱!
2. 配置文件和Java代码分离、编写不是很方便!
3. XML配置文件解析效率低
基于注解方式管理Bean
Bean注解标记和扫描(IoC)
组件添加标记注解
Spring 提供了以下多个注解,这些注解可以直接标注在 Java 类上,将它们定义成 Spring Bean。
| 注解 | 说明 |
|---|---|
| @Component | 该注解用于描述 Spring 中的 Bean,它是一个泛化的概念,仅仅表示容器中的一个组件(Bean),并且可以作用在应用的任何层次,例如 Service 层、Dao 层等。 使用时只需将该注解标注在相应类上即可。 |
| @Repository | 该注解用于将数据访问层(Dao 层)的类标识为 Spring 中的 Bean,其功能与 @Component 相同。 |
| @Service | 该注解通常作用在业务层(Service 层),用于将业务层的类标识为 Spring 中的 Bean,其功能与 @Component 相同。 |
| @Controller | 该注解通常作用在控制层(如SpringMVC 的 Controller),用于将控制层的类标识为 Spring 中的 Bean,其功能与 @Component 相同。 |
通过查看源码我们得知,@Controller、@Service、@Repository这三个注解只是在@Component注解的基础上起了三个新的名字。
对于Spring使用IOC容器管理这些组件来说没有区别,也就是语法层面没有区别。所以@Controller、@Service、@Repository这三个注解只是给开发人员看的,让我们能够便于分辨组件的作用。
注意:虽然它们本质上一样,但是为了代码的可读性、程序结构严谨!我们肯定不能随便胡乱标记。
1 | /** |
配置文件确定扫描范围
情况1:基本扫描配置
1 |
|
情况2:指定排除组件
1 | <!-- 指定不扫描的组件 --> |
情况3:指定扫描组件
1 | <!-- 仅扫描指定的组件 --> |
组件BeanName问题
在我们使用 XML 方式管理 bean 的时候,每个 bean 都有一个唯一标识——id 属性的值,便于在其他地方引用。现在使用注解后,每个组件仍然应该有一个唯一标识。
默认情况:
类名首字母小写就是 bean 的 id。例如:SoldierController 类对应的 bean 的 id 就是 soldierController。
使用value属性指定:
1 |
|
当注解中只设置一个属性时,value属性的属性名可以省略:
1 |
|
- 总结
- 注解方式IoC只是标记哪些类要被Spring管理
- 最终,我们还需要XML方式或者后面讲解Java配置类方式指定注解生效的包
- 现阶段配置方式为 注解 (标记)+ XML(扫描)
组件(Bean)作用域和周期方法注解
- 组件周期方法配置
周期方法概念
我们可以在组件类中定义方法,然后当IoC容器实例化和销毁组件对象的时候进行调用!这两个方法我们成为生命周期方法!
类似于Servlet的init/destroy方法,我们可以在周期方法完成初始化和释放资源等工作。
周期方法声明
1 | public class BeanOne { |
- 组件作用域配置
1 | //单例,默认值 |
Bean属性赋值:引用类型自动装配 (DI)
设定场景
SoldierController 需要 SoldierService
SoldierService 需要 SoldierDao
同时在各个组件中声明要调用的方法。
SoldierController中声明方法
自动装配实现
前提
参与自动装配的组件(需要装配、被装配)全部都必须在IoC容器中。
注意:不区分IoC的方式!XML和注解都可以!
@Autowired注解
在成员变量上直接标记@Autowired注解即可,不需要提供setXxx()方法。以后我们在项目中的正式用法就是这样。
给Controller装配Service
@Autowired注解细节
- 标记位置
成员变量
这是最主要的使用方式!
与xml进行bean ref引用不同,他不需要有set方法!
- 标记位置
1 |
|
2. 构造器
3. setXxx()方法
2. 工作流程
- 首先根据所需要的组件类型到 IOC 容器中查找
- 能够找到唯一的 bean:直接执行装配
- 如果完全找不到匹配这个类型的 bean:装配失败
- 和所需类型匹配的 bean 不止一个
- 没有 @Qualifier 注解:根据 @Autowired 标记位置成员变量的变量名作为 bean 的 id 进行匹配
- 能够找到:执行装配
- 找不到:装配失败
- 使用 @Qualifier 注解:根据 @Qualifier 注解中指定的名称作为 bean 的id进行匹配
- 能够找到:执行装配
- 找不到:装配失败
1 |
|
佛系装配
给 @Autowired 注解设置 required = false 属性表示:能装就装,装不上就不装。但是实际开发时,基本上所有需要装配组件的地方都是必须装配的,用不上这个属性
1 |
|
- 扩展JSR-250注解@Resource
理解JSR系列注解
JSR(Java Specification Requests)是Java平台标准化进程中的一种技术规范,而JSR注解是其中一部分重要的内容。按照JSR的分类以及注解语义的不同,可以将JSR注解分为不同的系列,主要有以下几个系列:
- JSR-175: 这个JSR是Java SE 5引入的,是Java注解最早的规范化版本,Java SE 5后的版本中都包含该JSR中定义的注解。主要包括以下几种标准注解:
@Deprecated: 标识一个程序元素(如类、方法或字段)已过时,并且在将来的版本中可能会被删除。@Override: 标识一个方法重写了父类中的方法。@SuppressWarnings: 抑制编译时产生的警告消息。@SafeVarargs: 标识一个有安全性警告的可变参数方法。@FunctionalInterface: 标识一个接口只有一个抽象方法,可以作为lambda表达式的目标。
- JSR-250: 这个JSR主要用于在Java EE 5中定义一些支持注解。该JSR主要定义了一些用于进行对象管理的注解,包括:
@Resource: 标识一个需要注入的资源,是实现Java EE组件之间依赖关系的一种方式。@PostConstruct: 标识一个方法作为初始化方法。@PreDestroy: 标识一个方法作为销毁方法。@Resource.AuthenticationType: 标识注入的资源的身份验证类型。@Resource.AuthenticationType: 标识注入的资源的默认名称。
- JSR-269: 这个JSR主要是Java SE 6中引入的一种支持编译时元数据处理的框架,即使用注解来处理Java源文件。该JSR定义了一些可以用注解标记的注解处理器,用于生成一些元数据,常用的注解有:
@SupportedAnnotationTypes: 标识注解处理器所处理的注解类型。@SupportedSourceVersion: 标识注解处理器支持的Java源码版本。
- JSR-330: 该JSR主要为Java应用程序定义了一个依赖注入的标准,即Java依赖注入标准(javax.inject)。在此规范中定义了多种注解,包括:
@Named: 标识一个被依赖注入的组件的名称。@Inject: 标识一个需要被注入的依赖组件。@Singleton: 标识一个组件的生命周期只有一个唯一的实例。
- JSR-250: 这个JSR主要是Java EE 5中定义一些支持注解。该JSR包含了一些支持注解,可以用于对Java EE组件进行管理,包括:
@RolesAllowed: 标识授权角色@PermitAll: 标识一个活动无需进行身份验证。@DenyAll: 标识不提供针对该方法的访问控制。@DeclareRoles: 声明安全角色。
但是你要理解JSR是Java提供的技术规范,也就是说,他只是规定了注解和注解的含义,JSR并不是直接提供特定的实现,而是提供标准和指导方针,由第三方框架(Spring)和库来实现和提供对应的功能。
JSR-250 @Resource注解
@Resource注解也可以完成属性注入。那它和@Autowired注解有什么区别?
- @Resource注解是JDK扩展包中的,也就是说属于JDK的一部分。所以该注解是标准注解,更加具有通用性。(JSR-250标准中制定的注解类型。JSR是Java规范提案。)
- @Autowired注解是Spring框架自己的。
- @Resource注解默认根据Bean名称装配,未指定name时,使用属性名作为name。通过name找不到的话会自动启动通过类型装配。
- @Autowired注解默认根据类型装配,如果想根据名称装配,需要配合@Qualifier注解一起用。
- @Resource注解用在属性上、setter方法上。
- @Autowired注解用在属性上、setter方法上、构造方法上、构造方法参数上。
@Resource注解属于JDK扩展包,所以不在JDK当中,需要额外引入以下依赖:【高于JDK11或低于JDK8需要引入以下依赖】
1 | <dependency> |
- @Resource使用
1 |
|
Bean属性赋值:基本类型属性赋值 (DI)
@Value 通常用于注入外部化属性
声明外部配置
application.properties
1 | catalog.name=MovieCatalog |
xml引入外部配置
1 | <!-- 引入外部配置文件--> |
@Value注解读取配置
1 |
|
基于配置类方式管理 Bean
完全注解开发理解
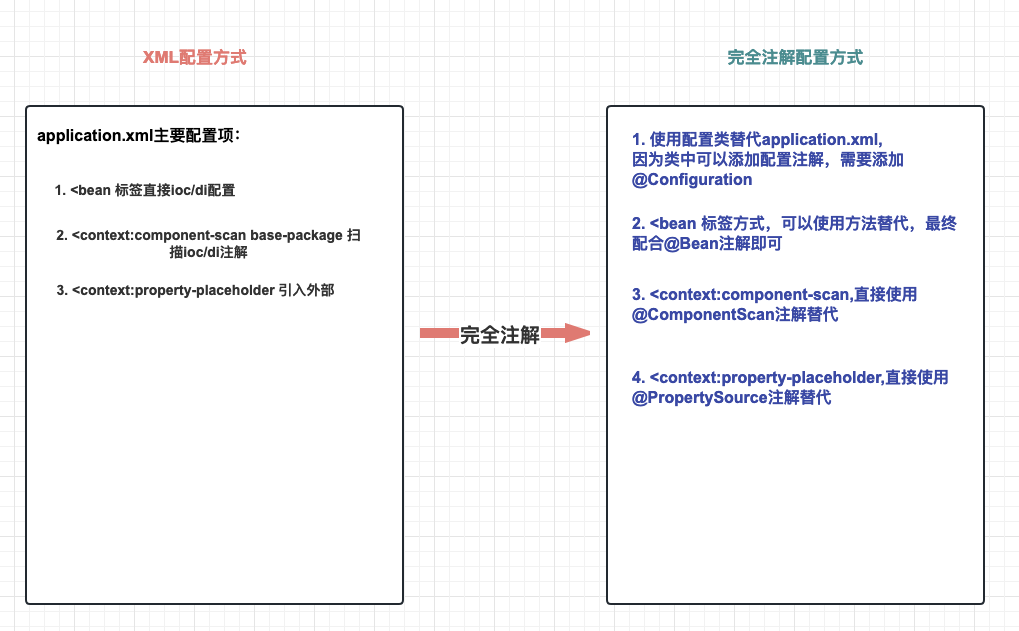
Spring 完全注解配置(Fully Annotation-based Configuration)是指通过 Java配置类 代码来配置 Spring 应用程序,使用注解来替代原本在 XML 配置文件中的配置。相对于 XML 配置,完全注解配置具有更强的类型安全性和更好的可读性。
两种方式思维转化:
配置类和扫描注解
1 | //标注当前类是配置类,替代application.xml |
测试创建IoC容器
1 | // AnnotationConfigApplicationContext 根据配置类创建 IOC 容器对象 |
可以使用 no-arg 构造函数实例化 `AnnotationConfigApplicationContext` ,然后使用 `register()` 方法对其进行配置。此方法在以编程方式生成 `AnnotationConfigApplicationContext` 时特别有用。以下示例演示如何执行此操作:
1 | // AnnotationConfigApplicationContext-IOC容器对象 |
总结:
@Configuration指定一个类为配置类,可以添加配置注解,替代配置xml文件
@ComponentScan(basePackages = {"包","包"}) 替代<context:component-scan标签实现注解扫描
@PropertySource("classpath:配置文件地址") 替代 <context:property-placeholder标签
配合IoC/DI注解,可以进行完整注解开发!
@Bean定义组件
场景需求:将Druid连接池对象存储到IoC容器
需求分析:第三方jar包的类,添加到ioc容器,无法使用@Component等相关注解!因为源码jar包内容为只读模式!
xml方式实现:
1 |
|
**配置类方式实现**:
`@Bean` 注释用于指示方法实例化、配置和初始化要由 Spring IoC 容器管理的新对象。对于那些熟悉 Spring 的 `<beans/>` XML 配置的人来说, `@Bean` 注释与 `<bean/>` 元素起着相同的作用。
1 | //标注当前类是配置类,替代application.xml |
高级特性:@Bean注解细节
@Bean生成BeanName问题
@Bean注解源码:
1 | public Bean { |
指定@Bean的名称:
1 |
|
`@Bean` 注释注释方法。使用此方法在指定为方法返回值的类型的 `ApplicationContext` 中注册 Bean 定义。缺省情况下,Bean 名称与方法名称相同。下面的示例演示 `@Bean` 方法声明:
1 |
|
前面的配置完全等同于下面的Spring XML:
1 | <beans> |
@Bean 初始化和销毁方法指定
@Bean注解支持指定任意初始化和销毁回调方法,非常类似于 Spring XML 在bean元素上的init-method和destroy-method属性,如以下示例所示:
1 | public class BeanOne { |
@Bean Scope作用域
可以指定使用
@Bean注释定义的 bean 应具有特定范围。您可以使用在 Bean 作用域部分中指定的任何标准作用域。默认作用域为
singleton,但您可以使用@Scope注释覆盖此范围,如以下示例所示:
1 |
|
@Bean方法之间依赖
准备组件
1 | public class HappyMachine { |
1 | public class HappyComponent { |
Java配置类实现:
方案1:
直接调用方法返回 Bean 实例:在一个 @Bean 方法中直接调用其他 @Bean 方法来获取 Bean 实例,虽然是方法调用,也是通过IoC容器获取对应的Bean,例如:
1 |
|
方案2:
参数引用法:通过方法参数传递 Bean 实例的引用来解决 Bean 实例之间的依赖关系,例如:
1 | package com.wzh.config; |
高级特性:@Import扩展
@Import 注释允许从另一个配置类加载 @Bean 定义,如以下示例所示:
1 |
|
现在,在实例化上下文时不需要同时指定 ConfigA.class 和 ConfigB.class ,只需显式提供 ConfigB ,如以下示例所示:
1 | public static void main(String[] args) { |
此方法简化了容器实例化,因为只需要处理一个类,而不是要求您在构造期间记住可能大量的 @Configuration 类。
Spring AOP面向切面编程
场景设定和问题复现
- 声明接口
1 | /** |
- 接口实现
1 | package com.wzh.proxy; |
- 声明带日志接口实现
新需求: 需要在每个方法中,添加控制台输出,输出参数和输出计算后的返回值!
1 | package com.wzh.proxy; |
- 代码问题分析
代码缺陷
- 对核心业务功能有干扰,导致程序员在开发核心业务功能时分散了精力
- 附加功能代码重复,分散在各个业务功能方法中!冗余,且不方便统一维护!
解决思路
核心就是:解耦。我们需要把附加功能从业务功能代码中抽取出来。
将重复的代码统一提取,并且[[动态插入]]到每个业务方法!
技术困难
解决问题的困难:提取重复附加功能代码到一个类中,可以实现
但是如何将代码插入到各个方法中,我们不会,我们需要引用新技术!!!
解决技术代理模式
代理模式
二十三种设计模式中的一种,属于结构型模式。它的作用就是通过提供一个代理类,让我们在调用目标方法的时候,不再是直接对目标方法进行调用,而是通过代理类间接调用。让不属于目标方法核心逻辑的代码从目标方法中剥离出来——解耦。调用目标方法时先调用代理对象的方法,减少对目标方法的调用和打扰,同时让附加功能能够集中在一起也有利于统一维护。
相关术语:
- 代理:将非核心逻辑剥离出来以后,封装这些非核心逻辑的类、对象、方法。(中介)
- 动词:指做代理这个动作,或这项工作
- 名词:扮演代理这个角色的类、对象、方法
- 目标:被代理“套用”了核心逻辑代码的类、对象、方法。(房东)
代理在开发中实现的方式具体有两种:静态代理,[动态代理技术]
- 代理:将非核心逻辑剥离出来以后,封装这些非核心逻辑的类、对象、方法。(中介)
静态代理
主动创建代理类:
1 | public class CalculatorStaticProxy implements Calculator { |
静态代理确实实现了解耦,但是由于代码都写死了,完全不具备任何的灵活性。就拿日志功能来说,将来其他地方也需要附加日志,那还得再声明更多个静态代理类,那就产生了大量重复的代码,日志功能还是分散的,没有统一管理。
提出进一步的需求:将日志功能集中到一个代理类中,将来有任何日志需求,都通过这一个代理类来实现。这就需要使用动态代理技术了。
动态代理
动态代理技术分类
- JDK动态代理:JDK原生的实现方式,需要被代理的目标类必须实现接口!他会根据目标类的接口动态生成一个代理对象!代理对象和目标对象有相同的接口!(拜把子)
- cglib:通过继承被代理的目标类实现代理,所以不需要目标类实现接口!(认干爹)
JDK动态代理技术实现(了解)
代理工程:基于jdk代理技术,生成代理对象
1 | public class ProxyFactory { |
测试代码:
1 |
|
代理总结
代理方式可以解决附加功能代码干扰核心代码和不方便统一维护的问题!
他主要是将附加功能代码提取到代理中执行,不干扰目标核心代码!
但是我们也发现,无论使用静态代理和动态代理(jdk,cglib),程序员的工作都比较繁琐!
需要自己编写代理工厂等!
但是,我们在实际开发中,不需要编写代理代码,我们可以使用[Spring AOP]框架,
他会简化动态代理的实现!!!
面向切面编程思维(AOP)
面向切面编程思想AOP
AOP:Aspect Oriented Programming面向切面编程
AOP可以说是OOP(Object Oriented Programming,面向对象编程)的补充和完善。OOP引入封装、继承、多态等概念来建立一种对象层次结构,用于模拟公共行为的一个集合。不过OOP允许开发者定义纵向的关系,但并不适合定义横向的关系,例如日志功能。日志代码往往横向地散布在所有对象层次中,而与它对应的对象的核心功能毫无关系对于其他类型的代码,如安全性、异常处理和透明的持续性也都是如此,这种散布在各处的无关的代码被称为横切(cross cutting),在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
AOP技术恰恰相反,它利用一种称为”横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其命名为”Aspect”,即切面。所谓”切面”,简单说就是那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块之间的耦合度,并有利于未来的可操作性和可维护性。
使用AOP,可以在不修改原来代码的基础上添加新功能。
AOP思想主要的应用场景
AOP(面向切面编程)是一种编程范式,它通过将通用的横切关注点(如日志、事务、权限控制等)与业务逻辑分离,使得代码更加清晰、简洁、易于维护。AOP可以应用于各种场景,以下是一些常见的AOP应用场景:
- 日志记录:在系统中记录日志是非常重要的,可以使用AOP来实现日志记录的功能,可以在方法执行前、执行后或异常抛出时记录日志。
- 事务处理:在数据库操作中使用事务可以保证数据的一致性,可以使用AOP来实现事务处理的功能,可以在方法开始前开启事务,在方法执行完毕后提交或回滚事务。
- 安全控制:在系统中包含某些需要安全控制的操作,如登录、修改密码、授权等,可以使用AOP来实现安全控制的功能。可以在方法执行前进行权限判断,如果用户没有权限,则抛出异常或转向到错误页面,以防止未经授权的访问。
- 性能监控:在系统运行过程中,有时需要对某些方法的性能进行监控,以找到系统的瓶颈并进行优化。可以使用AOP来实现性能监控的功能,可以在方法执行前记录时间戳,在方法执行完毕后计算方法执行时间并输出到日志中。
- 异常处理:系统中可能出现各种异常情况,如空指针异常、数据库连接异常等,可以使用AOP来实现异常处理的功能,在方法执行过程中,如果出现异常,则进行异常处理(如记录日志、发送邮件等)。
- 缓存控制:在系统中有些数据可以缓存起来以提高访问速度,可以使用AOP来实现缓存控制的功能,可以在方法执行前查询缓存中是否有数据,如果有则返回,否则执行方法并将方法返回值存入缓存中。
- 动态代理:AOP的实现方式之一是通过动态代理,可以代理某个类的所有方法,用于实现各种功能。
综上所述,AOP可以应用于各种场景,它的作用是将通用的横切关注点与业务逻辑分离,使得代码更加清晰、简洁、易于维护。
AOP术语名词介绍
1-横切关注点
从每个方法中抽取出来的同一类非核心业务。在同一个项目中,我们可以使用多个横切关注点对相关方法进行多个不同方面的增强。
这个概念不是语法层面天然存在的,而是根据附加功能的逻辑上的需要:有十个附加功能,就有十个横切关注点。
AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处基本相似,比如权限认证、日志、事务、异常等。AOP的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。
2-通知(增强)
每一个横切关注点上要做的事情都需要写一个方法来实现,这样的方法就叫通知方法。
- 前置通知:在被代理的目标方法前执行
- 返回通知:在被代理的目标方法成功结束后执行(寿终正寝)
- 异常通知:在被代理的目标方法异常结束后执行(死于非命)
- 后置通知:在被代理的目标方法最终结束后执行(盖棺定论)
- 环绕通知:使用try…catch…finally结构围绕整个被代理的目标方法,包括上面四种通知对应的所有位置
3-连接点 joinpoint
这也是一个纯逻辑概念,不是语法定义的。
指那些被拦截到的点。在 Spring 中,可以被动态代理拦截目标类的方法
4-切入点 pointcut
定位连接点的方式,或者可以理解成被选中的连接点!
是一个表达式,比如execution(* com.spring.service.impl..(..))。符合条件的每个方法都是一个具体的连接点。
5-切面 aspect
切入点和通知的结合。是一个类。
6-目标 target
被代理的目标对象。
7-代理 proxy
向目标对象应用通知之后创建的代理对象。
8-织入 weave
指把通知应用到目标上,生成代理对象的过程。可以在编译期织入,也可以在运行期织入,Spring采用后者。
Spring AOP框架介绍和关系梳理
- AOP一种区别于OOP的编程思维,用来完善和解决OOP的非核心代码冗余和不方便统一维护问题!
- 代理技术(动态代理|静态代理)是实现AOP思维编程的具体技术,但是自己使用动态代理实现代码比较繁琐!
- Spring AOP框架,基于AOP编程思维,封装动态代理技术,简化动态代理技术实现的框架!SpringAOP内部帮助我们实现动态代理,我们只需写少量的配置,指定生效范围即可,即可完成面向切面思维编程的实现!
Spring AOP基于注解方式实现和细节
Spring AOP底层技术组成
- 动态代理(InvocationHandler):JDK原生的实现方式,需要被代理的目标类必须实现接口。因为这个技术要求代理对象和目标对象实现同样的接口(兄弟两个拜把子模式)。
- cglib:通过继承被代理的目标类(认干爹模式)实现代理,所以不需要目标类实现接口。
- AspectJ:早期的AOP实现的框架,SpringAOP借用了AspectJ中的AOP注解。
初步实现
- 加入依赖
1 | <!-- spring-aspects会帮我们传递过来aspectjweaver --> |
- 准备接口
1 | public interface Calculator { |
- 纯净实现类
1 | package com.wzh.proxy; |
- 声明切面类
1 | package com.wzh.advice; |
- 开启aspectj注解支持
- xml方式
1 |
|
- 测试效果
1 | //@SpringJUnitConfig(locations = "classpath:spring-aop.xml") |
获取通知细节信息
JointPoint接口
需要获取方法签名、传入的实参等信息时,可以在通知方法声明JoinPoint类型的形参。
- 要点1:JoinPoint 接口通过 getSignature() 方法获取目标方法的签名(方法声明时的完整信息)
- 要点2:通过目标方法签名对象获取方法名
- 要点3:通过 JoinPoint 对象获取外界调用目标方法时传入的实参列表组成的数组
1 | // @Before注解标记前置通知方法 |
方法返回值
在返回通知中,通过**@AfterReturning**注解的returning属性获取目标方法的返回值!
1 | // @AfterReturning注解标记返回通知方法 |
异常对象捕捉
在异常通知中,通过@AfterThrowing注解的throwing属性获取目标方法抛出的异常对象
1 | // @AfterThrowing注解标记异常通知方法 |
切点表达式语法
切点表达式作用
AOP切点表达式(Pointcut Expression)是一种用于指定切点的语言,它可以通过定义匹配规则,来选择需要被切入的目标对象。
切点表达式语法
切点表达式总结
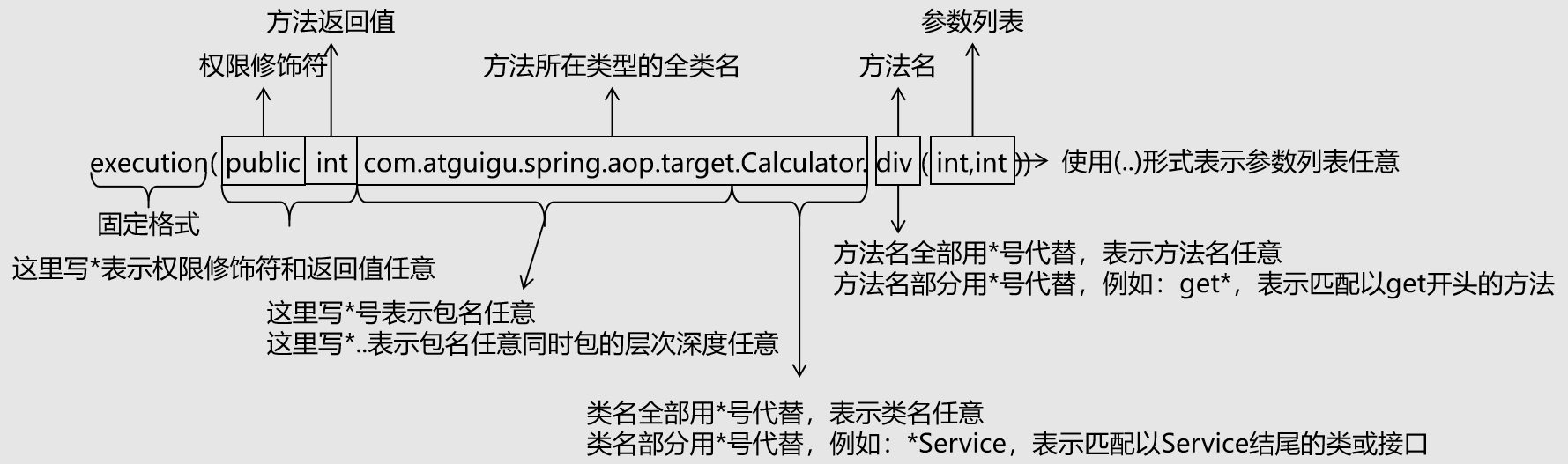
语法细节
- 第一位:execution( ) 固定开头
- 第二位:方法访问修饰符
1 | public private 直接描述对应修饰符即可 |
- 第三位:方法返回值
1 | int String void 直接描述返回值类型 |
注意:
特殊情况 不考虑 访问修饰符和返回值
execution(* * ) 这是错误语法
execution(*) == 你只要考虑返回值 或者 不考虑访问修饰符 相当于全部不考虑了
- 第四位:指定包的地址
1 | 固定的包: com.wzh.api | service | dao |
- 第五位:指定类名称
1 | 固定名称: UserService |
- 第六位:指定方法名称
1 | 语法和类名一致 |
- 第七位:方法参数
1 |
|
重用(提取)切点表达式
- 重用切点表达式优点
1 | // @Before注解:声明当前方法是前置通知方法 |
上面案例,是我们之前编写切点表达式的方式,发现, 所有增强方法的切点表达式相同!
出现了冗余,如果需要切换也不方便统一维护!
我们可以将切点提取,在增强上进行引用即可!
同一类内部引用
提取
1 | // 切入点表达式重用 |
注意:提取切点注解使用@Pointcut(切点表达式) , 需要添加到一个无参数无返回值方法上即可!
引用
1 |
|
不同类中引用
不同类在引用切点,只需要添加类的全限定符+方法名即可!
1 |
|
切点统一管理
建议:将切点表达式统一存储到一个类中进行集中管理和维护!
1 |
|
环绕通知
环绕通知对应整个 try…catch…finally 结构,包括前面四种通知的所有功能。
1 | // 使用@Around注解标明环绕通知方法 |
切面优先级设置
相同目标方法上同时存在多个切面时,切面的优先级控制切面的内外嵌套顺序。
- 优先级高的切面:外面
- 优先级低的切面:里面
使用 @Order 注解可以控制切面的优先级:
- @Order(较小的数):优先级高
- @Order(较大的数):优先级低
实际意义
实际开发时,如果有多个切面嵌套的情况,要慎重考虑。例如:如果事务切面优先级高,那么在缓存中命中数据的情况下,事务切面的操作都浪费了。
此时应该将缓存切面的优先级提高,在事务操作之前先检查缓存中是否存在目标数据。
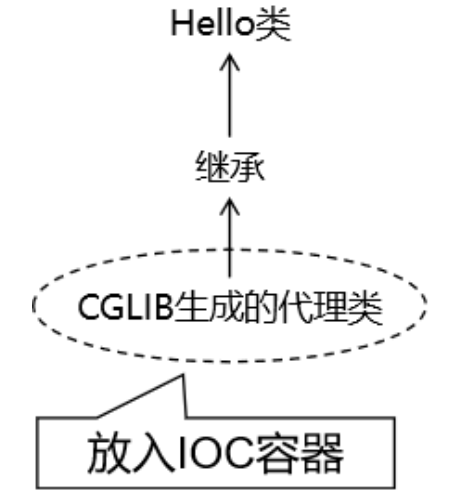
CGLib动态代理生效
在目标类没有实现任何接口的情况下,Spring会自动使用cglib技术实现代理。为了证明这一点,我们做下面的测试:
1 |
|
测试:
1 |
|
使用总结:
a. 如果目标类有接口,选择使用jdk动态代理
b. 如果目标类没有接口,选择cglib动态代理
c. 如果有接口,接口接值
d. 如果没有接口,类进行接值
Spring AOP基于XML方式实现(了解)
1 | <!-- 配置目标类的bean --> |
Spring AOP对获取Bean的影响理解
对实现了接口的类应用切面
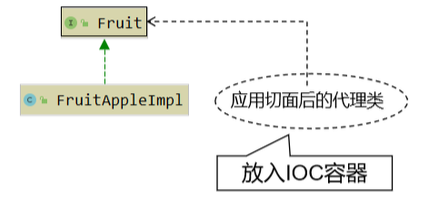
对没实现接口的类应用切面new
如果使用AOP技术,目标类有接口,必须使用接口类型接收IoC容器中代理组件!
Spring 声明式事务
声明式事务概念
编程式事务
编程式事务是指手动编写程序来管理事务,即通过编写代码的方式直接控制事务的提交和回滚。在 Java 中,通常使用事务管理器(如 Spring 中的 PlatformTransactionManager)来实现编程式事务。
编程式事务的主要优点是灵活性高,可以按照自己的需求来控制事务的粒度、模式等等。但是,编写大量的事务控制代码容易出现问题,对代码的可读性和可维护性有一定影响。
1 | Connection conn = ...; |
编程式的实现方式存在缺陷:
- 细节没有被屏蔽:具体操作过程中,所有细节都需要程序员自己来完成,比较繁琐。
- 代码复用性不高:如果没有有效抽取出来,每次实现功能都需要自己编写代码,代码就没有得到复用。
声明式事务
声明式事务是指使用注解或 XML 配置的方式来控制事务的提交和回滚。
开发者只需要添加配置即可, 具体事务的实现由第三方框架实现,避免我们直接进行事务操作!
使用声明式事务可以将事务的控制和业务逻辑分离开来,提高代码的可读性和可维护性。
区别:
- 编程式事务需要手动编写代码来管理事务
- 而声明式事务可以通过配置文件或注解来控制事务。
Spring事务管理器
Spring声明式事务对应依赖
- spring-tx: 包含声明式事务实现的基本规范(事务管理器规范接口和事务增强等等)
- spring-jdbc: 包含DataSource方式事务管理器实现类DataSourceTransactionManager
- spring-orm: 包含其他持久层框架的事务管理器实现类例如:Hibernate/Jpa等
Spring声明式事务对应事务管理器接口
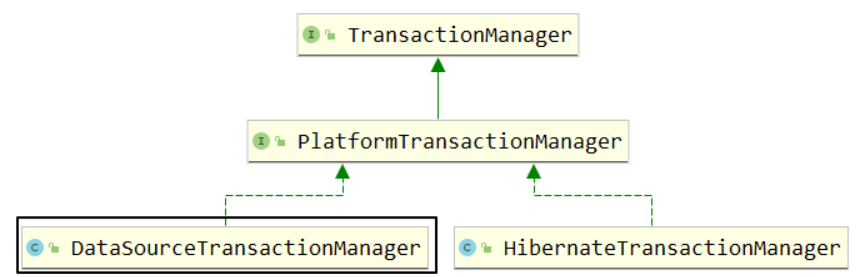
我们现在要使用的事务管理器是org.springframework.jdbc.datasource.DataSourceTransactionManager,将来整合 JDBC方式、JdbcTemplate方式、Mybatis方式的事务实现!
DataSourceTransactionManager类中的主要方法:
- doBegin():开启事务
- doSuspend():挂起事务
- doResume():恢复挂起的事务
- doCommit():提交事务
- doRollback():回滚事务
基于注解的声明式事务
准备工作
准备项目,导入相关依赖
外部配置文件
jdbc.properties
spring配置文件
1 |
|
准备dao/service层
dao
1 |
|
service
1 |
|
- 测试环境搭建
1 | /** |
基本事务控制
配置事务管理器
数据库相关的配置
1 | /** |
- 使用声明事务注解@Transactional
1 | /** |
- 测试事务效果
1 | /** |
事务属性:只读
只读介绍
对一个查询操作来说,如果我们把它设置成只读,就能够明确告诉数据库,这个操作不涉及写操作。这样数据库就能够针对查询操作来进行优化。
设置方式
1 | // readOnly = true把当前事务设置为只读 默认是false! |
针对DML动作设置只读模式
会抛出下面异常:
Caused by: java.sql.SQLException: Connection is read-only. Queries leading to data modification are not allowed
@Transactional注解放在类上
生效原则
如果一个类中每一个方法上都使用了 @Transactional 注解,那么就可以将 @Transactional 注解提取到类上。反过来说:@Transactional 注解在类级别标记,会影响到类中的每一个方法。同时,类级别标记的 @Transactional 注解中设置的事务属性也会延续影响到方法执行时的事务属性。除非在方法上又设置了 @Transactional 注解。
对一个方法来说,离它最近的 @Transactional 注解中的事务属性设置生效。
用法举例
在类级别@Transactional注解中设置只读,这样类中所有的查询方法都不需要设置@Transactional注解了。因为对查询操作来说,其他属性通常不需要设置,所以使用公共设置即可。
然后在这个基础上,对增删改方法设置@Transactional注解 readOnly 属性为 false。
1 |
|
事务属性:超时时间
需求
事务在执行过程中,有可能因为遇到某些问题,导致程序卡住,从而长时间占用数据库资源。而长时间占用资源,大概率是因为程序运行出现了问题(可能是Java程序或MySQL数据库或网络连接等等)。
此时这个很可能出问题的程序应该被回滚,撤销它已做的操作,事务结束,把资源让出来,让其他正常程序可以执行。
概括来说就是一句话:超时回滚,释放资源。
设置超时时间
1 |
|
测试超时效果
执行抛出事务超时异常
事务属性:事务异常
默认情况
默认只针对运行时异常回滚,编译时异常不回滚。情景模拟代码如下:
1 |
|
设置回滚异常
rollbackFor属性:指定哪些异常类才会回滚,默认是 RuntimeException and Error 异常方可回滚!
1 | /** |
设置不回滚的异常
在默认设置和已有设置的基础上,再指定一个异常类型,碰到它不回滚。
noRollbackFor属性:指定哪些异常不会回滚, 默认没有指定,如果指定,应该在rollbackFor的范围内!
1 |
|
事务属性:事务隔离级别
事务隔离级别
数据库事务的隔离级别是指在多个事务并发执行时,数据库系统为了保证数据一致性所遵循的规定。常见的隔离级别包括:
- 读未提交(Read Uncommitted):事务可以读取未被提交的数据,容易产生脏读、不可重复读和幻读等问题。实现简单但不太安全,一般不用。
- 读已提交(Read Committed):事务只能读取已经提交的数据,可以避免脏读问题,但可能引发不可重复读和幻读。
- 可重复读(Repeatable Read):在一个事务中,相同的查询将返回相同的结果集,不管其他事务对数据做了什么修改。可以避免脏读和不可重复读,但仍有幻读的问题。
- 串行化(Serializable):最高的隔离级别,完全禁止了并发,只允许一个事务执行完毕之后才能执行另一个事务。可以避免以上所有问题,但效率较低,不适用于高并发场景。
不同的隔离级别适用于不同的场景,需要根据实际业务需求进行选择和调整。
事务隔离级别设置
1 |
|
事务属性:事务传播行为
事务传播行为要研究的问题

举例代码:
1 |
|
propagation属性
@Transactional 注解通过 propagation 属性设置事务的传播行为。它的默认值是:
1 | Propagation propagation() default Propagation.REQUIRED; |
propagation 属性的可选值由 org.springframework.transaction.annotation.Propagation 枚举类提供:
| 名称 | 含义 |
|---|---|
| REQUIRED 默认值 | 如果父方法有事务,就加入,如果没有就新建自己独立! |
| REQUIRES_NEW | 不管父方法是否有事务,我都新建事务,都是独立的! |
**注意:**
在同一个类中,对于@Transactional注解的方法调用,事务传播行为不会生效。这是因为Spring框架中使用代理模式实现了事务机制,在同一个类中的方法调用并不经过代理,而是通过对象的方法调用,因此@Transactional注解的设置不会被代理捕获,也就不会产生任何事务传播行为的效果。
- 其他传播行为值(了解)
- Propagation.REQUIRED:如果当前存在事务,则加入当前事务,否则创建一个新事务。
- Propagation.REQUIRES_NEW:创建一个新事务,并在新事务中执行。如果当前存在事务,则挂起当前事务,即使新事务抛出异常,也不会影响当前事务。
- Propagation.NESTED:如果当前存在事务,则在该事务中嵌套一个新事务,如果没有事务,则与Propagation.REQUIRED一样。
- Propagation.SUPPORTS:如果当前存在事务,则加入该事务,否则以非事务方式执行。
- Propagation.NOT_SUPPORTED:以非事务方式执行,如果当前存在事务,挂起该事务。
- Propagation.MANDATORY:必须在一个已有的事务中执行,否则抛出异常。
- Propagation.NEVER:必须在没有事务的情况下执行,否则抛出异常。
Spring核心掌握总结
| 核心点 | 掌握目标 |
| spring框架理解 | spring家族和spring framework框架 |
| spring核心功能 | ioc/di , aop , tx |
| spring ioc / di | 组件管理、ioc容器、ioc/di , 三种配置方式 |
| spring aop | aop和aop框架和代理技术、基于注解的aop配置 |
| spring tx | 声明式和编程式事务、动态事务管理器、事务注解、属性 |
MyBatis
版本:3.5.11
提高持久层开发效率
Mybatis简介
简介
MyBatis最初是Apache的一个开源项目iBatis, 2010年6月这个项目由Apache Software Foundation迁移到了Google Code。随着开发团队转投Google Code旗下, iBatis3.x正式更名为MyBatis。代码于2013年11月迁移到Github。
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
持久层框架对比
- JDBC
- SQL 夹杂在Java代码中耦合度高,导致硬编码内伤
- 维护不易且实际开发需求中 SQL 有变化,频繁修改的情况多见
- 代码冗长,开发效率低
- Hibernate 和 JPA
- 操作简便,开发效率高
- 程序中的长难复杂 SQL 需要绕过框架
- 内部自动生成的 SQL,不容易做特殊优化
- 基于全映射的全自动框架,大量字段的 POJO 进行部分映射时比较困难。
- 反射操作太多,导致数据库性能下降
- MyBatis
- 轻量级,性能出色
- SQL 和 Java 编码分开,功能边界清晰。Java代码专注业务、SQL语句专注数据
- 开发效率稍逊于 Hibernate,但是完全能够接收
开发效率:Hibernate>Mybatis>JDBC
运行效率:JDBC>Mybatis>Hibernate
快速入门(基于Mybatis3方式)
- 准备数据模型(数据库)
- 项目搭建和依赖导入
1 | <dependencies> |
- 实体类准备
1 | public class Employee { |
准备Mapper接口和MapperXML文件
MyBatis 框架下,SQL语句编写位置发生改变,从原来的Java类,改成XML或者注解定义!
推荐在XML文件中编写SQL语句,让用户能更专注于 SQL 代码,不用关注其他的JDBC代码。
如果拿它跟具有相同功能的 JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码!!
一般编写SQL语句的文件命名:XxxMapper.xml Xxx一般取表名!!
Mybatis 中的 Mapper 接口相当于以前的 Dao。但是区别在于,Mapper 仅仅只是建接口即可,我们不需要提供实现类,具体的SQL写到对应的Mapper文件,该用法的思路如下图所示:
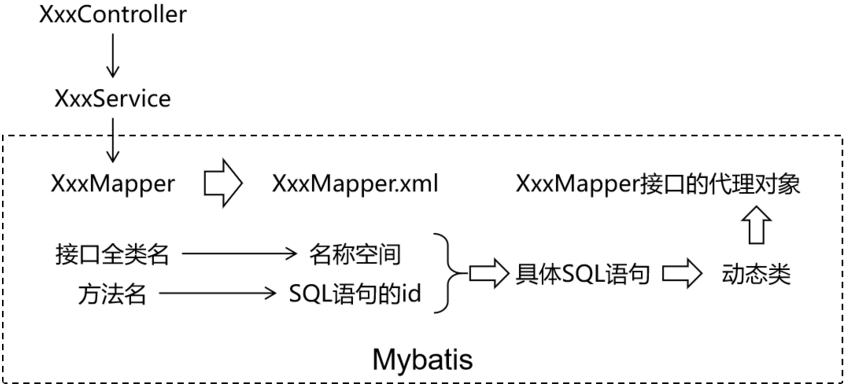
- 定义mapper接口
1 | /** |
2. 定义mapper.xml
位置: resources/mappers/EmployeeMapper.xml
1 |
|
注意:
- 方法名和SQL的id一致
- 方法返回值和resultType一致
- 方法的参数和SQL的参数一致
- 接口的全类名和映射配置文件的名称空间一致
准备MyBatis配置文件
mybatis框架配置文件: 数据库连接信息,性能配置,mapper.xml配置等!
习惯上命名为 mybatis-config.xml,这个文件名仅仅只是建议,并非强制要求。将来整合 Spring 之后,这个配置文件可以省略,所以大家操作时可以直接复制、粘贴。
1 |
|
- 运行和测试
1 | /** |
说明:
- SqlSession:代表Java程序和数据库之间的会话。(HttpSession是Java程序和浏览器之间的会话)
- SqlSessionFactory:是“生产”SqlSession的“工厂”。
- 工厂模式:如果创建某一个对象,使用的过程基本固定,那么我们就可以把创建这个对象的相关代码封装到一个“工厂类”中,以后都使用这个工厂类来“生产”我们需要的对象。
- SqlSession和HttpSession区别
- HttpSession:工作在Web服务器上,属于表述层。
- 代表浏览器和Web服务器之间的会话。
- SqlSession:不依赖Web服务器,属于持久化层。
- 代表Java程序和数据库之间的会话。
- HttpSession:工作在Web服务器上,属于表述层。
MyBatis基本使用
向SQL语句传参
mybatis日志输出配置
mybatis配置文件设计标签和顶层结构如下:
- configuration(配置)
- properties(属性)
- settings(设置)
- typeAliases(类型别名)
- typeHandlers(类型处理器)
- objectFactory(对象工厂)
- plugins(插件)
- environments(环境配置)
- environment(环境变量)
- transactionManager(事务管理器)
- dataSource(数据源)
- environment(环境变量)
- databaseIdProvider(数据库厂商标识)
- mappers(映射器)
我们可以在mybatis的配置文件使用settings标签设置,输出运行过程SQL日志!
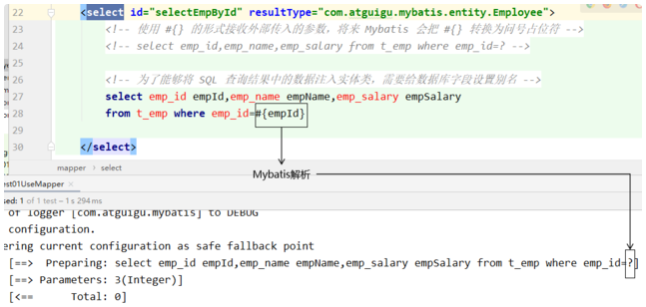
通过查看日志,我们可以判定#{} 和 ${}的输出效果!
日志配置:
1 | <settings> |
#{}形式
Mybatis会将SQL语句中的#{}转换为问号占位符。
${}形式
${}形式传参,底层Mybatis做的是字符串拼接操作。
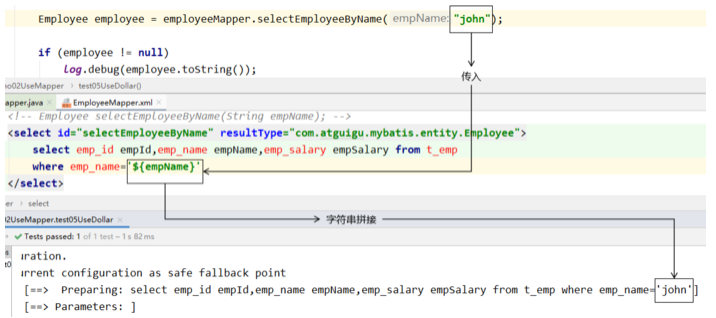
通常不会采用${}的方式传值。一个特定的适用场景是:通过Java程序动态生成数据库表,表名部分需要Java程序通过参数传入;而JDBC对于表名部分是不能使用问号占位符的,此时只能使用
结论:实际开发中,能用#{}实现的,肯定不用${}。
特殊情况: 动态的不是值,是列名或者关键字,需要使用${}拼接
1 | //注解方式传入参数!! |
数据输入
概念说明
这里数据输入具体是指上层方法(例如Service方法)调用Mapper接口时,数据传入的形式。
- 简单类型:只包含一个值的数据类型
- 基本数据类型:int、byte、short、double、……
- 基本数据类型的包装类型:Integer、Character、Double、……
- 字符串类型:String
- 复杂类型:包含多个值的数据类型
- 实体类类型:Employee、Department、……
- 集合类型:List、Set、Map、……
- 数组类型:int[]、String[]、……
- 复合类型:List
、实体类中包含集合……
单个简单类型参数
Mapper接口中抽象方法的声明
1 | Employee selectEmployee(Integer empId); |
SQL语句
1 | <select id="selectEmployee" resultType="com.atguigu.mybatis.entity.Employee"> |
单个简单类型参数,在#{}中可以随意命名,但是没有必要。通常还是使用和接口方法参数同名。
实体类类型参数
Mapper接口中抽象方法的声明
1 | int insertEmployee(Employee employee); |
SQL语句
1 | <insert id="insertEmployee"> |
Mybatis会根据#{}中传入的数据,加工成getXxx()方法,通过反射在实体类对象中调用这个方法,从而获取到对应的数据。填充到#{}解析后的问号占位符这个位置。
零散的简单类型数据
零散的多个简单类型参数,如果没有特殊处理,那么Mybatis无法识别自定义名称:
Mapper接口中抽象方法的声明
1 | int updateEmployee( Integer empId, Double empSalary); |
SQL语句
1 | <update id="updateEmployee"> |
Map类型参数
Mapper接口中抽象方法的声明
1 | int updateEmployeeByMap(Map<String, Object> paramMap); |
SQL语句
1 | <update id="updateEmployeeByMap"> |
junit测试
1 | private SqlSession session; |
对应关系
#{}中写Map中的key
使用场景
有很多零散的参数需要传递,但是没有对应的实体类类型可以使用。使用@Param注解一个一个传入又太麻烦了。所以都封装到Map中。
数据输出
输出概述
数据输出总体上有两种形式:
- 增删改操作返回的受影响行数:直接使用 int 或 long 类型接收即可
- 查询操作的查询结果
我们需要做的是,指定查询的输出数据类型即可!
并且插入场景下,实现主键数据回显示!
单个简单类型
Mapper接口中的抽象方法
1 | int selectEmpCount(); |
SQL语句
1 | <select id="selectEmpCount" resultType="int"> |
Mybatis 内部给常用的数据类型设定了很多别名。 以 int 类型为例,可以写的名称有:int、integer、Integer、java.lang.Integer、Int、INT、INTEGER 等等。
细节解释:
select标签,通过resultType指定查询返回值类型!
resultType = "全限定符 | 别名 | 如果是返回集合类型,写范型类型即可"
别名问题:
[https://mybatis.org/mybatis-3/zh/configuration.html#typeAliases](https://mybatis.org/mybatis-3/zh/configuration.html#typeAliases)
类型别名可为 Java 类型设置一个缩写名字。 它仅用于 XML 配置,意在降低冗余的全限定类名书写。例如:
1 | <typeAliases> |
当这样配置时,`Blog` 可以用在任何使用 `domain.blog.Blog` 的地方。
也可以指定一个包名,MyBatis 会在包名下面搜索需要的 Java Bean,比如:
1 | <typeAliases> <package name="domain.blog"/> </typeAliases> |
每一个在包 `domain.blog` 中的 Java Bean,在没有注解的情况下,会使用 Bean 的首字母小写的非限定类名来作为它的别名。 比如 `domain.blog.Author` 的别名为 `author`;若有注解,则别名为其注解值。见下面的例子:
1 |
|
下面是Mybatis为常见的 Java 类型内建的类型别名。它们都是不区分大小写的,注意,为了应对原始类型的命名重复,采取了特殊的命名风格。
| 别名 | 映射的类型 |
|---|---|
| _byte | byte |
| _char (since 3.5.10) | char |
| _character (since 3.5.10) | char |
| _long | long |
| _short | short |
| _int | int |
| _integer | int |
| _double | double |
| _float | float |
| _boolean | boolean |
| string | String |
| byte | Byte |
| char (since 3.5.10) | Character |
| character (since 3.5.10) | Character |
| long | Long |
| short | Short |
| int | Integer |
| integer | Integer |
| double | Double |
| float | Float |
| boolean | Boolean |
| date | Date |
| decimal | BigDecimal |
| bigdecimal | BigDecimal |
| biginteger | BigInteger |
| object | Object |
| object[] | Object[] |
| map | Map |
| hashmap | HashMap |
| list | List |
| arraylist | ArrayList |
| collection | Collection |
返回实体类对象
Mapper接口的抽象方法
1 | Employee selectEmployee(Integer empId); |
SQL语句
1 | <!-- 编写具体的SQL语句,使用id属性唯一的标记一条SQL语句 --> |
通过给数据库表字段加别名,让查询结果的每一列都和Java实体类中属性对应起来。
增加全局配置自动识别对应关系
在 Mybatis 全局配置文件中,做了下面的配置,select语句中可以不给字段设置别名
1 | <!-- 在全局范围内对Mybatis进行配置 --> |
返回Map类型
适用于SQL查询返回的各个字段综合起来并不和任何一个现有的实体类对应,没法封装到实体类对象中。能够封装成实体类类型的,就不使用Map类型。
Mapper接口的抽象方法
1 | Map<String,Object> selectEmpNameAndMaxSalary(); |
SQL语句
1 | <!-- Map<String,Object> selectEmpNameAndMaxSalary(); --> |
返回List类型
查询结果返回多个实体类对象,希望把多个实体类对象放在List集合中返回。此时不需要任何特殊处理,在resultType属性中还是设置实体类类型即可。
Mapper接口中抽象方法
1 | List<Employee> selectAll(); |
SQL语句
1 | <!-- List<Employee> selectAll(); --> |
返回主键值
- 自增长类型主键
Mapper接口中的抽象方法
1 | int insertEmployee(Employee employee); |
SQL语句
1 | <!-- int insertEmployee(Employee employee); --> |
注意:
Mybatis是将自增主键的值设置到实体类对象中,而不是以Mapper接口方法返回值的形式返回。
2. 非自增长类型主键
而对于不支持自增型主键的数据库(例如 Oracle)或者字符串类型主键,则可以使用 selectKey 子元素:selectKey 元素将会首先运行,id 会被设置,然后插入语句会被调用!
使用 selectKey 帮助插入UUID作为字符串类型主键示例:
1 | <insert id="insertUser" parameterType="User"> |
在上例中,我们定义了一个 insertUser 的插入语句来将 User 对象插入到 user 表中。我们使用 selectKey 来查询 UUID 并设置到 id 字段中。
通过 keyProperty 属性来指定查询到的 UUID 赋值给对象中的 id 属性,而 resultType 属性指定了 UUID 的类型为 java.lang.String。
需要注意的是,我们将 selectKey 放在了插入语句的前面,这是因为 MySQL 在 insert 语句中只支持一个 select 子句,而 selectKey 中查询 UUID 的语句就是一个 select 子句,因此我们需要将其放在前面。
最后,在将 User 对象插入到 user 表中时,我们直接使用对象中的 id 属性来插入主键值。
使用这种方式,我们可以方便地插入 UUID 作为字符串类型主键。当然,还有其他插入方式可以使用,如使用Java代码生成UUID并在类中显式设置值等。需要根据具体应用场景和需求选择合适的插入方式。
实体类属性和数据库字段对应关系
别名对应
将字段的别名设置成和实体类属性一致。
1 | <!-- 编写具体的SQL语句,使用id属性唯一的标记一条SQL语句 --> |
关于实体类属性的约定:getXxx()方法、setXxx()方法把方法名中的get或set去掉,首字母小写。
全局配置自动识别驼峰式命名规则
在Mybatis全局配置文件加入如下配置:
1 | <!-- 使用settings对Mybatis全局进行设置 --> |
SQL语句中可以不使用别名
1 | <!-- Employee selectEmployee(Integer empId); --> |
使用resultMap
使用resultMap标签定义对应关系,再在后面的SQL语句中引用这个对应关系
1 | <!-- 专门声明一个resultMap设定column到property之间的对应关系 --> |
mapperXML标签总结
MyBatis 的真正强大在于它的语句映射,这是它的魔力所在。由于它的异常强大,映射器的 XML 文件就显得相对简单。如果拿它跟具有相同功能的 JDBC 代码进行对比,你会立即发现省掉了将近 95% 的代码。MyBatis 致力于减少使用成本,让用户能更专注于 SQL 代码。
SQL 映射文件只有很少的几个顶级元素(按照应被定义的顺序列出):
insert– 映射插入语句。update– 映射更新语句。delete– 映射删除语句。select– 映射查询语句。
select标签:
MyBatis 在查询和结果映射做了相当多的改进。一个简单查询的 select 元素是非常简单:
1 | <select id="selectPerson" |
这个语句名为 selectPerson,接受一个 int(或 Integer)类型的参数,并返回一个 HashMap 类型的对象,其中的键是列名,值便是结果行中的对应值。
注意参数符号:#{id} ${key}
MyBatis 创建一个预处理语句(PreparedStatement)参数,在 JDBC 中,这样的一个参数在 SQL 中会由一个“?”来标识,并被传递到一个新的预处理语句中,就像这样:
1 | // 近似的 JDBC 代码,非 MyBatis 代码... |
select 元素允许你配置很多属性来配置每条语句的行为细节:
| 属性 | 描述 |
|---|---|
id |
在命名空间中唯一的标识符,可以被用来引用这条语句。 |
resultType |
期望从这条语句中返回结果的类全限定名或别名。 注意,如果返回的是集合,那应该设置为集合包含的类型,而不是集合本身的类型。 resultType 和 resultMap 之间只能同时使用一个。 |
resultMap |
对外部 resultMap 的命名引用。结果映射是 MyBatis 最强大的特性,如果你对其理解透彻,许多复杂的映射问题都能迎刃而解。 resultType 和 resultMap 之间只能同时使用一个。 |
timeout |
这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动)。 |
statementType |
可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
insert, update 和 delete标签:
数据变更语句 insert,update 和 delete 的实现非常接近:
1 | <insert |
| 属性 | 描述 |
|---|---|
id |
在命名空间中唯一的标识符,可以被用来引用这条语句。 |
timeout |
这个设置是在抛出异常之前,驱动程序等待数据库返回请求结果的秒数。默认值为未设置(unset)(依赖数据库驱动)。 |
statementType |
可选 STATEMENT,PREPARED 或 CALLABLE。这会让 MyBatis 分别使用 Statement,PreparedStatement 或 CallableStatement,默认值:PREPARED。 |
useGeneratedKeys |
(仅适用于 insert 和 update)这会令 MyBatis 使用 JDBC 的 getGeneratedKeys 方法来取出由数据库内部生成的主键(比如:像 MySQL 和 SQL Server 这样的关系型数据库管理系统的自动递增字段),默认值:false。 |
keyProperty |
(仅适用于 insert 和 update)指定能够唯一识别对象的属性,MyBatis 会使用 getGeneratedKeys 的返回值或 insert 语句的 selectKey 子元素设置它的值,默认值:未设置(unset)。如果生成列不止一个,可以用逗号分隔多个属性名称。 |
keyColumn |
(仅适用于 insert 和 update)设置生成键值在表中的列名,在某些数据库(像 PostgreSQL)中,当主键列不是表中的第一列的时候,是必须设置的。如果生成列不止一个,可以用逗号分隔多个属性名称。 |
MyBatis多表映射
多表映射概念
多表查询结果映射思路
开发中更多的是多表查询需求,这种情况我们如何让进行处理?MyBatis 思想是:数据库不可能永远是你所想或所需的那个样子。 我们希望每个数据库都具备良好的第三范式或 BCNF 范式,可惜它们并不都是那样。 如果能有一种数据库映射模式,完美适配所有的应用程序查询需求,那就太好了,而 ResultMap 就是 MyBatis 就是完美答案。
实体类设计方案
多表关系回顾:(双向查看)
- 一对一
- 一对多| 多对一
- 多对多
实体类设计关系(查询):(单向查看)
对一 :
实体类设计:对一关系下,类中只要包含单个对方对象类型属性即可!
1 | public class Customer { |
- 对多:
实体类设计:对多关系下,类中只要包含对方类型集合属性即可!
1 | public class Customer { |
多表结果实体类设计小技巧:
对一,属性中包含对方对象
对多,属性中包含对方对象集合
只有真实发生多表查询时,才需要设计和修改实体类,否则不提前设计和修改实体类!
无论多少张表联查,实体类设计都是两两考虑!
在查询映射的时候,只需要关注本次查询相关的属性!例如:查询订单和对应的客户,就不要关注客户中的订单集合!
多表映射案例准备
数据库:
实际开发时,一般在开发过程中,不给数据库表设置外键约束。原因是避免调试不方便。一般是功能开发完成,再加外键约束检查是否有bug。
对一映射
需求说明
根据ID查询订单,以及订单关联的用户的信息!
OrderMapper接口
1 | public interface OrderMapper { |
- OrderMapper.xml配置文件
1 | <!-- 创建resultMap实现“对一”关联关系映射 --> |
- Mybatis全局注册Mapper文件
1 | <!-- 注册Mapper配置文件:告诉Mybatis我们的Mapper配置文件的位置 --> |
junit测试程序
关键词
在“对一”关联关系中,我们的配置比较多,但是关键词就只有:association和javaType
对多映射
需求说明
查询客户和客户关联的订单信息!
CustomerMapper接口
1 | public interface CustomerMapper { |
- CustomerMapper.xml文件
1 | <!-- 配置resultMap实现从Customer到OrderList的“对多”关联关系 --> |
Mybatis全局注册Mapper文件
junit测试程序
关键词
在“对多”关联关系中,同样有很多配置,但是提炼出来最关键的就是:“collection”和“ofType”
多表映射总结
多表映射优化
| setting属性 | 属性含义 | 可选值 | 默认值 |
|---|---|---|---|
| autoMappingBehavior | 指定 MyBatis 应如何自动映射列到字段或属性。 NONE 表示关闭自动映射;PARTIAL 只会自动映射没有定义嵌套结果映射的字段。 FULL 会自动映射任何复杂的结果集(无论是否嵌套)。 | NONE, PARTIAL, FULL | PARTIAL |
我们可以将autoMappingBehavior设置为full,进行多表resultMap映射的时候,可以省略符合列和属性命名映射规则(列名=属性名,或者开启驼峰映射也可以自定映射)的result标签!
修改mybatis-config.xml:
1 | <!--开启resultMap自动映射 --> |
修改teacherMapper.xml
1 | <resultMap id="teacherMap" type="teacher"> |
多表映射总结
| 关联关系 | 配置项关键词 | 所在配置文件和具体位置 |
|---|---|---|
| 对一 | association标签/javaType属性/property属性 | Mapper配置文件中的resultMap标签内 |
| 对多 | collection标签/ofType属性/property属性 | Mapper配置文件中的resultMap标签内 |
MyBatis动态语句
动态语句需求和简介
经常遇到很多按照很多查询条件进行查询的情况,比如智联招聘的职位搜索等。其中经常出现很多条件不取值的情况,在后台应该如何完成最终的SQL语句呢?
动态 SQL 是 MyBatis 的强大特性之一。如果你使用过 JDBC 或其它类似的框架,你应该能理解根据不同条件拼接 SQL 语句有多痛苦,例如拼接时要确保不能忘记添加必要的空格,还要注意去掉列表最后一个列名的逗号。利用动态 SQL,可以彻底摆脱这种痛苦。
使用动态 SQL 并非一件易事,但借助可用于任何 SQL 映射语句中的强大的动态 SQL 语言,MyBatis 显著地提升了这一特性的易用性。
如果你之前用过 JSTL 或任何基于类 XML 语言的文本处理器,你对动态 SQL 元素可能会感觉似曾相识。在 MyBatis 之前的版本中,需要花时间了解大量的元素。借助功能强大的基于 OGNL 的表达式,MyBatis 3 替换了之前的大部分元素,大大精简了元素种类,现在要学习的元素种类比原来的一半还要少。
if和where标签
使用动态 SQL 最常见情景是根据条件包含 where / if 子句的一部分。比如:
1 | <!-- List<Employee> selectEmployeeByCondition(Employee employee); --> |
set标签
1 | <!-- void updateEmployeeDynamic(Employee employee) --> |
trim标签(了解)
使用trim标签控制条件部分两端是否包含某些字符
- prefix属性:指定要动态添加的前缀
- suffix属性:指定要动态添加的后缀
- prefixOverrides属性:指定要动态去掉的前缀,使用“|”分隔有可能的多个值
- suffixOverrides属性:指定要动态去掉的后缀,使用“|”分隔有可能的多个值
1 | <!-- List<Employee> selectEmployeeByConditionByTrim(Employee employee) --> |
choose/when/otherwise标签
在多个分支条件中,仅执行一个。
- 从上到下依次执行条件判断
- 遇到的第一个满足条件的分支会被采纳
- 被采纳分支后面的分支都将不被考虑
- 如果所有的when分支都不满足,那么就执行otherwise分支
1 | <!-- List<Employee> selectEmployeeByConditionByChoose(Employee employee) --> |
foreach标签
基本用法
用批量插入举例
1 | <!-- |
批量更新时需要注意
上面批量插入的例子本质上是一条SQL语句,而实现批量更新则需要多条SQL语句拼起来,用分号分开。也就是一次性发送多条SQL语句让数据库执行。此时需要在数据库连接信息的URL地址中设置:
1 | atguigu.dev.url=jdbc:mysql:///mybatis-example?allowMultiQueries=true |
对应的foreach标签如下:
1 | <!-- int updateEmployeeBatch(@Param("empList") List<Employee> empList) --> |
关于foreach标签的collection属性
如果没有给接口中List类型的参数使用@Param注解指定一个具体的名字,那么在collection属性中默认可以使用collection或list来引用这个list集合。这一点可以通过异常信息看出来:
1 | Parameter 'empList' not found. Available parameters are [arg0, collection, list] |
在实际开发中,为了避免隐晦的表达造成一定的误会,建议使用@Param注解明确声明变量的名称,然后在foreach标签的collection属性中按照@Param注解指定的名称来引用传入的参数。
sql片段
抽取重复的SQL片段
1 | <!-- 使用sql标签抽取重复出现的SQL片段 --> |
引用已抽取的SQL片段
1 | <!-- 使用include标签引用声明的SQL片段 --> |
MyBatis高级扩展
Mapper批量映射优化
需求
Mapper 配置文件很多时,在全局配置文件中一个一个注册太麻烦,希望有一个办法能够一劳永逸。
配置方式
Mybatis 允许在指定 Mapper 映射文件时,只指定其所在的包:
1 | <mappers> |
此时这个包下的所有 Mapper 配置文件将被自动加载、注册,比较方便。
- 资源创建要求
- Mapper 接口和 Mapper 配置文件名称一致
- Mapper 接口:EmployeeMapper.java
- Mapper 配置文件:EmployeeMapper.xml
- Mapper 配置文件放在 Mapper 接口所在的包内
- 可以将mapperxml文件放在mapper接口所在的包!
- 可以在sources下创建mapper接口包一致的文件夹结构存放mapperxml文件
插件和分页插件PageHelper
插件机制和PageHelper插件介绍
MyBatis 对插件进行了标准化的设计,并提供了一套可扩展的插件机制。插件可以在用于语句执行过程中进行拦截,并允许通过自定义处理程序来拦截和修改 SQL 语句、映射语句的结果等。
具体来说,MyBatis 的插件机制包括以下三个组件:
Interceptor(拦截器):定义一个拦截方法intercept,该方法在执行 SQL 语句、执行查询、查询结果的映射时会被调用。Invocation(调用):实际上是对被拦截的方法的封装,封装了Object target、Method method和Object[] args这三个字段。InterceptorChain(拦截器链):对所有的拦截器进行管理,包括将所有的 Interceptor 链接成一条链,并在执行 SQL 语句时按顺序调用。
插件的开发非常简单,只需要实现 Interceptor 接口,并使用注解 @Intercepts 来标注需要拦截的对象和方法,然后在 MyBatis 的配置文件中添加插件即可。
PageHelper 是 MyBatis 中比较著名的分页插件,它提供了多种分页方式(例如 MySQL 和 Oracle 分页方式),支持多种数据库,并且使用非常简单。下面就介绍一下 PageHelper 的使用方式。
PageHelper插件使用
- pom.xml引入依赖
1 | <dependency> |
mybatis-config.xml配置分页插件
在 MyBatis 的配置文件中添加 PageHelper 的插件:
1 | <plugins> |
其中,com.github.pagehelper.PageInterceptor 是 PageHelper 插件的名称,dialect 属性用于指定数据库类型(支持多种数据库)
页插件使用
在查询方法中使用分页:
1 |
|
逆向工程和MybatisX插件
ORM思维介绍
ORM(Object-Relational Mapping,对象-关系映射)是一种将数据库和面向对象编程语言中的对象之间进行转换的技术。它将对象和关系数据库的概念进行映射,最后我们就可以通过方法调用进行数据库操作!!
最终: 让我们可以使用面向对象思维进行数据库操作!!!
ORM 框架通常有半自动和全自动两种方式。
- 半自动 ORM 通常需要程序员手动编写 SQL 语句或者配置文件,将实体类和数据表进行映射,还需要手动将查询的结果集转换成实体对象。
- 全自动 ORM 则是将实体类和数据表进行自动映射,使用 API 进行数据库操作时,ORM 框架会自动执行 SQL 语句并将查询结果转换成实体对象,程序员无需再手动编写 SQL 语句和转换代码。
下面是半自动和全自动 ORM 框架的区别:
- 映射方式:半自动 ORM 框架需要程序员手动指定实体类和数据表之间的映射关系,通常使用 XML 文件或注解方式来指定;全自动 ORM 框架则可以自动进行实体类和数据表的映射,无需手动干预。
- 查询方式:半自动 ORM 框架通常需要程序员手动编写 SQL 语句并将查询结果集转换成实体对象;全自动 ORM 框架可以自动组装 SQL 语句、执行查询操作,并将查询结果转换成实体对象。
- 性能:由于半自动 ORM 框架需要手动编写 SQL 语句,因此程序员必须对 SQL 语句和数据库的底层知识有一定的了解,才能编写高效的 SQL 语句;而全自动 ORM 框架通过自动优化生成的 SQL 语句来提高性能,程序员无需进行优化。
- 学习成本:半自动 ORM 框架需要程序员手动编写 SQL 语句和映射配置,要求程序员具备较高的数据库和 SQL 知识;全自动 ORM 框架可以自动生成 SQL 语句和映射配置,程序员无需了解过多的数据库和 SQL 知识。
常见的半自动 ORM 框架包括 MyBatis 等;常见的全自动 ORM 框架包括 Hibernate、Spring Data JPA、MyBatis-Plus 等。
逆向工程
MyBatis 的逆向工程是一种自动化生成持久层代码和映射文件的工具,它可以根据数据库表结构和设置的参数生成对应的实体类、Mapper.xml 文件、Mapper 接口等代码文件,简化了开发者手动生成的过程。逆向工程使开发者可以快速地构建起 DAO 层,并快速上手进行业务开发。
MyBatis 的逆向工程有两种方式:通过 MyBatis Generator 插件实现和通过 Maven 插件实现。无论是哪种方式,逆向工程一般需要指定一些配置参数,例如数据库连接 URL、用户名、密码、要生成的表名、生成的文件路径等等。
总的来说,MyBatis 的逆向工程为程序员提供了一种方便快捷的方式,能够快速地生成持久层代码和映射文件,是半自动 ORM 思维像全自动发展的过程,提高程序员的开发效率。
**注意:逆向工程只能生成单表crud的操作,多表查询依然需要我们自己编写!**
逆向工程插件MyBatisX使用
MyBatisX 是一个 MyBatis 的代码生成插件,可以通过简单的配置和操作快速生成 MyBatis Mapper、pojo 类和 Mapper.xml 文件。下面是使用 MyBatisX 插件实现逆向工程的步骤:
- 安装插件:
- 使用 IntelliJ IDEA连接数据库
- 连接数据库
- 填写信息
- 展示库表
- 逆向工程使用
- 查看生成结果
- 逆向工程案例使用
1 | /** |
MyBatis总结
| 核心点 | 掌握目标 |
| mybatis基础 | 使用流程, 参数输入,#{} ${},参数输出 |
| mybatis多表 | 实体类设计,resultMap多表结果映射 |
| mybatis动态语句 | Mybatis动态语句概念, where , if , foreach标签 |
| mybatis扩展 | Mapper批量处理,分页插件,逆向工程 |
SpringMVC
版本:6.0.6
简化表述层开发框架
SpringMVC简介和体验
介绍
https://docs.spring.io/spring-framework/reference/web/webmvc.html
Spring Web MVC是基于Servlet API构建的原始Web框架,从一开始就包含在Spring Framework中。正式名称“Spring Web MVC”来自其源模块的名称( spring-webmvc ),但它通常被称为“Spring MVC”。
在控制层框架历经Strust、WebWork、Strust2等诸多产品的历代更迭之后,目前业界普遍选择了SpringMVC作为Java EE项目表述层开发的首选方案。之所以能做到这一点,是因为SpringMVC具备如下显著优势:
- Spring 家族原生产品,与IOC容器等基础设施无缝对接
- 表述层各细分领域需要解决的问题全方位覆盖,提供全面解决方案
- 代码清新简洁,大幅度提升开发效率
- 内部组件化程度高,可插拔式组件即插即用,想要什么功能配置相应组件即可
- 性能卓著,尤其适合现代大型、超大型互联网项目要求
原生Servlet API开发代码片段
1 | protected void doGet(HttpServletRequest request, HttpServletResponse response) |
基于SpringMVC开发代码片段
1 |
|
主要作用
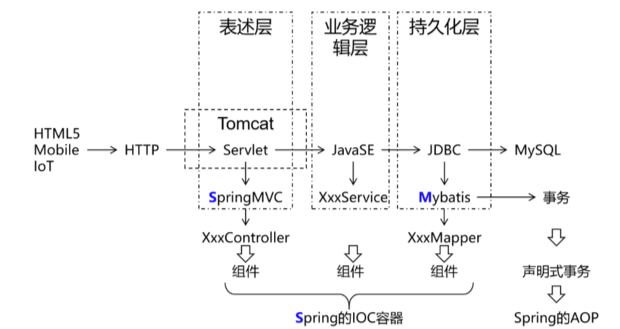
SSM框架构建起单体项目的技术栈需求!其中的SpringMVC负责表述层(控制层)实现简化!
SpringMVC的作用主要覆盖的是表述层,例如:
- 请求映射
- 数据输入
- 视图界面
- 请求分发
- 表单回显
- 会话控制
- 过滤拦截
- 异步交互
- 文件上传
- 文件下载
- 数据校验
- 类型转换
- 等等等
最终总结:
1. 简化前端参数接收( 形参列表 )
2. 简化后端数据响应(返回值)
3. 以及其他……
核心组件和调用流程理解
Spring MVC与许多其他Web框架一样,是围绕前端控制器模式设计的,其中中央 Servlet DispatcherServlet 做整体请求处理调度!
除了DispatcherServletSpringMVC还会提供其他特殊的组件协作完成请求处理和响应呈现。
SpringMVC涉及组件理解:
1. DispatcherServlet : SpringMVC提供,我们需要使用web.xml配置使其生效,它是整个流程处理的核心,所有请求都经过它的处理和分发![ CEO ]
2. HandlerMapping : SpringMVC提供,我们需要进行IoC配置使其加入IoC容器方可生效,它内部缓存handler(controller方法)和handler访问路径数据,被DispatcherServlet调用,用于查找路径对应的handler![秘书]
3. HandlerAdapter : SpringMVC提供,我们需要进行IoC配置使其加入IoC容器方可生效,它可以处理请求参数和处理响应数据数据,每次DispatcherServlet都是通过handlerAdapter间接调用handler,他是handler和DispatcherServlet之间的适配器![经理]
4. Handler : handler又称处理器,他是Controller类内部的方法简称,是由我们自己定义,用来接收参数,向后调用业务,最终返回响应结果![打工人]
5. ViewResovler : SpringMVC提供,我们需要进行IoC配置使其加入IoC容器方可生效!视图解析器主要作用简化模版视图页面查找的,但是需要注意,前后端分离项目,后端只返回JSON数据,不返回页面,那就不需要视图解析器!所以,视图解析器,相对其他的组件不是必须的![财务]
快速体验
- 体验场景需求
- 配置分析
- DispatcherServlet,设置处理所有请求!
- HandlerMapping,HandlerAdapter,Handler需要加入到IoC容器,供DS调用!
- Handler自己声明(Controller)需要配置到HandlerMapping中供DS查找!
- 准备项目
创建项目
springmvc-base-quick
注意:需要转成maven/web程序!!
导入依赖
1 | <properties> |
- Controller声明
1 |
|
Spring MVC核心组件配置类
声明springmvc涉及组件信息的配置类
1 | //TODO: SpringMVC对应组件的配置类 [声明SpringMVC需要的组件信息] |
SpringMVC环境搭建
对于使用基于 Java 的 Spring 配置的应用程序,建议这样做,如以下示例所示:
1 | //TODO: SpringMVC提供的接口,是替代web.xml的方案,更方便实现完全注解方式ssm处理! |
启动测试
注意: tomcat应该是10+版本!方可支持 Jakarta EE API!
SpringMVC接收数据
访问路径设置
@RequestMapping注解的作用就是将请求的 URL 地址和处理请求的方式(handler方法)关联起来,建立映射关系。
SpringMVC 接收到指定的请求,就会来找到在映射关系中对应的方法来处理这个请求。
精准路径匹配
在@RequestMapping注解指定 URL 地址时,不使用任何通配符,按照请求地址进行精确匹配。
1 |
|
模糊路径匹配
在@RequestMapping注解指定 URL 地址时,通过使用通配符,匹配多个类似的地址。
1 |
|
1 | 单层匹配和多层匹配: |
类和方法级别区别
@RequestMapping注解可以用于类级别和方法级别,它们之间的区别如下:- 设置到类级别:
@RequestMapping注解可以设置在控制器类上,用于映射整个控制器的通用请求路径。这样,如果控制器中的多个方法都需要映射同一请求路径,就不需要在每个方法上都添加映射路径。 - 设置到方法级别:
@RequestMapping注解也可以单独设置在控制器方法上,用于更细粒度地映射请求路径和处理方法。当多个方法处理同一个路径的不同操作时,可以使用方法级别的@RequestMapping注解进行更精细的映射。
- 设置到类级别:
附带请求方式限制
HTTP 协议定义了八种请求方式,在 SpringMVC 中封装到了下面这个枚举类:
1 | public enum RequestMethod { |
默认情况下:@RequestMapping(“/logout”) 任何请求方式都可以访问!
如果需要特定指定:
1 |
|
进阶注解
还有
@RequestMapping的 HTTP 方法特定快捷方式变体:@GetMapping@PostMapping@PutMapping@DeleteMapping@PatchMapping
1 |
|
注意:进阶注解只能添加到handler方法上,无法添加到类上!
常见配置问题
出现原因:多个 handler 方法映射了同一个地址,导致 SpringMVC 在接收到这个地址的请求时该找哪个 handler 方法处理。
There is already ‘demo03MappingMethodHandler’ bean method com.atguigu.mvc.handler.Demo03MappingMethodHandler#empGet() mapped.
接收参数(重点)
param 和 json参数比较
在 HTTP 请求中,我们可以选择不同的参数类型,如 param 类型和 JSON 类型。下面对这两种参数类型进行区别和对比:
参数编码:
param 类型的参数会被编码为 ASCII 码。例如,假设
name=john doe,则会被编码为name=john%20doe。而 JSON 类型的参数会被编码为 UTF-8。参数顺序:
param 类型的参数没有顺序限制。但是,JSON 类型的参数是有序的。JSON 采用键值对的形式进行传递,其中键值对是有序排列的。
数据类型:
param 类型的参数仅支持字符串类型、数值类型和布尔类型等简单数据类型。而 JSON 类型的参数则支持更复杂的数据类型,如数组、对象等。
嵌套性:
param 类型的参数不支持嵌套。但是,JSON 类型的参数支持嵌套,可以传递更为复杂的数据结构。
可读性:
param 类型的参数格式比 JSON 类型的参数更加简单、易读。但是,JSON 格式在传递嵌套数据结构时更加清晰易懂。
总的来说,param 类型的参数适用于单一的数据传递,而 JSON 类型的参数则更适用于更复杂的数据结构传递。根据具体的业务需求,需要选择合适的参数类型。在实际开发中,常见的做法是:在 GET 请求中采用 param 类型的参数,而在 POST 请求中采用 JSON 类型的参数传递。
param参数接收
- 直接接值
客户端请求
handler接收参数
只要形参数名和类型与传递参数相同,即可自动接收!
1 |
|
- @RequestParam注解
可以使用 `@RequestParam` 注释将 Servlet 请求参数(即查询参数或表单数据)绑定到控制器中的方法参数。
`@RequestParam`使用场景:
- 指定绑定的请求参数名
- 要求请求参数必须传递
- 为请求参数提供默认值
基本用法:
1 | /** |
默认情况下,使用此批注的方法参数是必需的,但您可以通过将 `@RequestParam` 批注的 `required` 标志设置为 `false`!
如果没有没有设置非必须,也没有传递参数会报错
将参数设置非必须,并且设置默认值:
1 |
|
- 特殊场景接值
一名多值
多选框,提交的数据的时候一个key对应多个值,我们可以使用集合进行接收!
1 | /** |
2. 实体接收
Spring MVC 是 Spring 框架提供的 Web 框架,它允许开发者使用实体对象来接收 HTTP 请求中的参数。通过这种方式,可以在方法内部直接使用对象的属性来访问请求参数,而不需要每个参数都写一遍。下面是一个使用实体对象接收参数的示例:
定义一个用于接收参数的实体类:
1 | public class User { |
在控制器中,使用实体对象接收,示例代码如下:
1 |
|
在上述代码中,将请求参数name和age映射到实体类属性上!要求属性名必须等于参数名!否则无法映射!
路径参数接收
路径传递参数是一种在 URL 路径中传递参数的方式。在 RESTful 的 Web 应用程序中,经常使用路径传递参数来表示资源的唯一标识符或更复杂的表示方式。而 Spring MVC 框架提供了 @PathVariable 注解来处理路径传递参数。
@PathVariable 注解允许将 URL 中的占位符映射到控制器方法中的参数。
例如,如果我们想将 /user/{id} 路径下的 {id} 映射到控制器方法的一个参数中,则可以使用 @PathVariable 注解来实现。
下面是一个使用 @PathVariable 注解处理路径传递参数的示例:
1 | /** |
json参数接收
前端传递 JSON 数据时,Spring MVC 框架可以使用 @RequestBody 注解来将 JSON 数据转换为 Java 对象。@RequestBody 注解表示当前方法参数的值应该从请求体中获取,并且需要指定 value 属性来指示请求体应该映射到哪个参数上。其使用方式和示例代码如下:
- 前端发送 JSON 数据的示例:(使用postman测试)
1 | { |
2. 定义一个用于接收 JSON 数据的 Java 类,例如:
1 | public class Person { |
- 在控制器中,使用
@RequestBody注解来接收 JSON 数据,并将其转换为 Java 对象,例如:
1 |
|
在上述代码中,`@RequestBody` 注解将请求体中的 JSON 数据映射到 `Person` 类型的 `person` 参数上,并将其作为一个对象来传递给 `addPerson()` 方法进行处理。
完善配置
问题:- 不支持json数据类型处理
- 没有json类型处理的工具(jackson)
解决:
springmvc handlerAdpater配置json转化器,配置类需要明确:
1 | //TODO: SpringMVC对应组件的配置类 [声明SpringMVC需要的组件信息] |
pom.xml 加入jackson依赖
1 | <dependency> |
@EnableWebMvc注解说明
@EnableWebMvc注解效果等同于在 XML 配置中,可以使用
<mvc:annotation-driven>元素!我们来解析<mvc:annotation-driven>对应的解析工作!让我们来查看下
<mvc:annotation-driven>具体的动作:handlerMapping加入到ioc容器;添加jackson转化器;handlerAdapter加入到ioc容器;具体添加jackson转化对象方法。
接收Cookie数据
可以使用 @CookieValue 注释将 HTTP Cookie 的值绑定到控制器中的方法参数。
考虑使用以下 cookie 的请求:
1 | JSESSIONID=415A4AC178C59DACE0B2C9CA727CDD84 |
下面的示例演示如何获取 cookie 值:
1 |
|
接收请求头数据
可以使用 @RequestHeader 批注将请求标头绑定到控制器中的方法参数。
请考虑以下带有标头的请求:
1 | Host localhost:8080 |
下面的示例获取 Accept-Encoding 和 Keep-Alive 标头的值:
1 |
|
原生Api对象操作
下表描述了支持的控制器方法参数
| Controller method argument 控制器方法参数 | Description |
|---|---|
jakarta.servlet.ServletRequest, jakarta.servlet.ServletResponse |
请求/响应对象 |
jakarta.servlet.http.HttpSession |
强制存在会话。因此,这样的参数永远不会为 null 。 |
java.io.InputStream, java.io.Reader |
用于访问由 Servlet API 公开的原始请求正文。 |
java.io.OutputStream, java.io.Writer |
用于访问由 Servlet API 公开的原始响应正文。 |
@PathVariable |
接收路径参数注解 |
@RequestParam |
用于访问 Servlet 请求参数,包括多部分文件。参数值将转换为声明的方法参数类型。 |
@RequestHeader |
用于访问请求标头。标头值将转换为声明的方法参数类型。 |
@CookieValue |
用于访问Cookie。Cookie 值将转换为声明的方法参数类型。 |
@RequestBody |
用于访问 HTTP 请求正文。正文内容通过使用 HttpMessageConverter 实现转换为声明的方法参数类型。 |
java.util.Map, org.springframework.ui.Model, org.springframework.ui.ModelMap |
共享域对象,并在视图呈现过程中向模板公开。 |
Errors, BindingResult |
验证和数据绑定中的错误信息获取对象! |
获取原生对象示例:
1 | /** |
共享域对象操作
属性(共享)域作用回顾
在 JavaWeb 中,共享域指的是在 Servlet 中存储数据,以便在同一 Web 应用程序的多个组件中进行共享和访问。常见的共享域有四种:ServletContext、HttpSession、HttpServletRequest、PageContext。
ServletContext共享域:ServletContext对象可以在整个 Web 应用程序中共享数据,是最大的共享域。一般可以用于保存整个 Web 应用程序的全局配置信息,以及所有用户都共享的数据。在ServletContext中保存的数据是线程安全的。HttpSession共享域:HttpSession对象可以在同一用户发出的多个请求之间共享数据,但只能在同一个会话中使用。比如,可以将用户登录状态保存在HttpSession中,让用户在多个页面间保持登录状态。HttpServletRequest共享域:HttpServletRequest对象可以在同一个请求的多个处理器方法之间共享数据。比如,可以将请求的参数和属性存储在HttpServletRequest中,让处理器方法之间可以访问这些数据。PageContext共享域:PageContext对象是在 JSP 页面Servlet 创建时自动创建的。它可以在 JSP 的各个作用域中共享数据,包括pageScope、requestScope、sessionScope、applicationScope等作用域。
共享域的作用是提供了方便实用的方式在同一 Web 应用程序的多个组件之间传递数据,并且可以将数据保存在不同的共享域中,根据需要进行选择和使用。
Request级别属性(共享)域
- 使用 Model 类型的形参
1 |
|
- 使用 ModelMap 类型的形参
1 |
|
- 使用 Map 类型的形参
1 |
|
- 使用原生 request 对象
1 |
|
- 使用 ModelAndView 对象
1 |
|
Session级别属性(共享)域
1 |
|
Application级别属性(共享)域
解释:springmvc会在初始化容器的时候,讲servletContext对象存储到ioc容器中!
1 |
|
SpringMVC响应数据
handler方法分析
理解handler方法的作用和组成:
1 | /** |
总结: 请求数据接收,我们都是通过handler的形参列表;前端数据响应,我们都是通过handler的return关键字快速处理!springmvc简化了参数接收和响应!
页面跳转控制
快速返回模板视图
开发模式回顾
在 Web 开发中,有两种主要的开发模式:前后端分离和混合开发。
前后端分离模式:[重点]
指将前端的界面和后端的业务逻辑通过接口分离开发的一种方式。开发人员使用不同的技术栈和框架,前端开发人员主要负责页面的呈现和用户交互,后端开发人员主要负责业务逻辑和数据存储。前后端通信通过 API 接口完成,数据格式一般使用 JSON 或 XML。前后端分离模式可以提高开发效率,同时也有助于代码重用和维护。
混合开发模式:
指将前端和后端的代码集成在同一个项目中,共享相同的技术栈和框架。这种模式在小型项目中比较常见,可以减少学习成本和部署难度。但是,在大型项目中,这种模式会导致代码耦合性很高,维护和升级难度较大。
对于混合开发,我们就需要使用动态页面技术,动态展示Java的共享域数据!!
jsp技术了解
JSP(JavaServer Pages)是一种动态网页开发技术,它是由 Sun 公司提出的一种基于 Java 技术的 Web 页面制作技术,可以在 HTML 文件中嵌入 Java 代码,使得生成动态内容的编写更加简单。
JSP 最主要的作用是生成动态页面。它允许将 Java 代码嵌入到 HTML 页面中,以便使用 Java 进行数据库查询、处理表单数据和生成 HTML 等动态内容。另外,JSP 还可以与 Servlet 结合使用,实现更加复杂的 Web 应用程序开发。
JSP 的主要特点包括:
- 简单:JSP 通过将 Java 代码嵌入到 HTML 页面中,使得生成动态内容的编写更加简单。
- 高效:JSP 首次运行时会被转换为 Servlet,然后编译为字节码,从而可以启用 Just-in-Time(JIT)编译器,实现更高效的运行。
- 多样化:JSP 支持多种标准标签库,包括 JSTL(JavaServer Pages 标准标签库)、EL(表达式语言)等,可以帮助开发人员更加方便的处理常见的 Web 开发需求。
总之,JSP 是一种简单高效、多样化的动态网页开发技术,它可以方便地生成动态页面和与 Servlet 结合使用,是 Java Web 开发中常用的技术之一。
准备jsp页面和依赖
pom.xml依赖
1 | <!-- jsp需要依赖! jstl--> |
jsp页面创建
建议位置:/WEB-INF/下,避免外部直接访问!
位置:/WEB-INF/views/home.jsp
1 | <%@ page contentType="text/html;charset=UTF-8" language="java" %> |
- 快速响应模版页面
- 配置jsp视图解析器
1
2
3
4
5
6
7
8
9
10
11
12
13
14//json数据处理,必须使用此注解,因为他会加入json处理器
//TODO: 进行controller扫描
//WebMvcConfigurer springMvc进行组件配置的规范,配置组件,提供各种方法! 前期可以实现
public class SpringMvcConfig implements WebMvcConfigurer {
//配置jsp对应的视图解析器
public void configureViewResolvers(ViewResolverRegistry registry) {
//快速配置jsp模板语言对应的
registry.jsp("/WEB-INF/views/",".jsp");
}
} - handler返回视图
- 配置jsp视图解析器
1 | /** |
转发和重定向
在 Spring MVC 中,Handler 方法返回值来实现快速转发,可以使用 redirect 或者 forward 关键字来实现重定向。
1 |
|
总结:
- 将方法的返回值,设置String类型
- 转发使用forward关键字,重定向使用redirect关键字
- 关键字: /路径
- 注意:如果是项目下的资源,转发和重定向都一样都是项目下路径!都不需要添加项目根路径!
返回JSON数据(重点)
前置准备
导入jackson依赖
@ResponseBody
方法上使用@ResponseBody
可以在方法上使用
@ResponseBody注解,用于将方法返回的对象序列化为 JSON 或 XML 格式的数据,并发送给客户端。在前后端分离的项目中使用!测试方法:
1 |
|
具体来说,@ResponseBody 注解可以用来标识方法或者方法返回值,表示方法的返回值是要直接返回给客户端的数据,而不是由视图解析器来解析并渲染生成响应体(viewResolver没用)。
类上使用@ResponseBody
如果类中每个方法上都标记了 @ResponseBody 注解,那么这些注解就可以提取到类上。
1 | //responseBody可以添加到类上,代表默认类中的所有方法都生效! |
@RestController
类上的 @ResponseBody 注解可以和 @Controller 注解合并为 @RestController 注解。所以使用了 @RestController 注解就相当于给类中的每个方法都加了 @ResponseBody 注解。
返回静态资源处理
静态资源概念
资源本身已经是可以直接拿到浏览器上使用的程度了,不需要在服务器端做任何运算、处理。典型的静态资源包括:
- 纯HTML文件
- 图片
- CSS文件
- JavaScript文件
- ……
静态资源访问和问题解决
1 | //json数据处理,必须使用此注解,因为他会加入json处理器 |
RESTFul风格设计和实战
RESTFul风格概述
RESTFul风格简介
RESTful(Representational State Transfer)是一种软件架构风格,用于设计网络应用程序和服务之间的通信。它是一种基于标准 HTTP 方法的简单和轻量级的通信协议,广泛应用于现代的Web服务开发。
通过遵循 RESTful 架构的设计原则,可以构建出易于理解、可扩展、松耦合和可重用的 Web 服务。RESTful API 的特点是简单、清晰,并且易于使用和理解,它们使用标准的 HTTP 方法和状态码进行通信,不需要额外的协议和中间件。
总而言之,RESTful 是一种基于 HTTP 和标准化的设计原则的软件架构风格,用于设计和实现可靠、可扩展和易于集成的 Web 服务和应用程序!
学习RESTful设计原则可以帮助我们更好去设计HTTP协议的API接口!!
RESTFul风格特点
- 每一个URI代表1种资源(URI 是名词);
- 客户端使用GET、POST、PUT、DELETE 4个表示操作方式的动词对服务端资源进行操作:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源;
- 资源的表现形式是XML或者JSON;
- 客户端与服务端之间的交互在请求之间是无状态的,从客户端到服务端的每个请求都必须包含理解请求所必需的信息。
RESTFul风格设计规范
HTTP协议请求方式要求
REST 风格主张在项目设计、开发过程中,具体的操作符合HTTP协议定义的请求方式的语义。
| 操作 | 请求方式 |
|---|---|
| 查询操作 | GET |
| 保存操作 | POST |
| 删除操作 | DELETE |
| 更新操作 | PUT |
URL路径风格要求
REST风格下每个资源都应该有一个唯一的标识符,例如一个 URI(统一资源标识符)或者一个 URL(统一资源定位符)。资源的标识符应该能明确地说明该资源的信息,同时也应该是可被理解和解释的!
使用URL+请求方式确定具体的动作,他也是一种标准的HTTP协议请求!
| 操作 | 传统风格 | REST 风格 |
|---|---|---|
| 保存 | /CRUD/saveEmp | URL 地址:/CRUD/emp 请求方式:POST |
| 删除 | /CRUD/removeEmp?empId=2 | URL 地址:/CRUD/emp/2 请求方式:DELETE |
| 更新 | /CRUD/updateEmp | URL 地址:/CRUD/emp 请求方式:PUT |
| 查询 | /CRUD/editEmp?empId=2 | URL 地址:/CRUD/emp/2 请求方式:GET |
总结
根据接口的具体动作,选择具体的HTTP协议请求方式
路径设计从原来携带动标识,改成名词,对应资源的唯一标识即可!
RESTFul风格好处
1. 含蓄,安全
使用问号键值对的方式给服务器传递数据太明显,容易被人利用来对系统进行破坏。使用 REST 风格携带数据不再需要明显的暴露数据的名称。
2. 风格统一
URL 地址整体格式统一,从前到后始终都使用斜杠划分各个单词,用简单一致的格式表达语义。
3. 无状态
在调用一个接口(访问、操作资源)的时候,可以不用考虑上下文,不用考虑当前状态,极大的降低了系统设计的复杂度。
4. 严谨,规范
严格按照 HTTP1.1 协议中定义的请求方式本身的语义进行操作。
5. 简洁,优雅
过去做增删改查操作需要设计4个不同的URL,现在一个就够了。
6. 丰富的语义
通过 URL 地址就可以知道资源之间的关系。它能够把一句话中的很多单词用斜杠连起来,反过来说就是可以在 URL 地址中用一句话来充分表达语义。
RESTFul风格实战
需求分析
- 数据结构: User {id 唯一标识,name 用户名,age 用户年龄}
- 功能分析
- 用户数据分页展示功能(条件:page 页数 默认1,size 每页数量 默认 10)
- 保存用户功能
- 根据用户id查询用户详情功能
- 根据用户id更新用户数据功能
- 根据用户id删除用户数据功能
- 多条件模糊查询用户功能(条件:keyword 模糊关键字,page 页数 默认1,size 每页数量 默认 10)
RESTFul风格接口设计
- 接口设计
| 功能 | 接口和请求方式 | 请求参数 | 返回值 |
| 分页查询 | GET /user | page=1&size=10 | { 响应数据 } |
| 用户添加 | POST /user | { user 数据 } | {响应数据} |
| 用户详情 | GET /user/1 | 路径参数 | {响应数据} |
| 用户更新 | PUT /user | { user 更新数据} | {响应数据} |
| 用户删除 | DELETE /user/1 | 路径参数 | {响应数据} |
| 条件模糊 | GET /user/search | page=1&size=10&keywork=关键字 | {响应数据} |
问题讨论
为什么查询用户详情,就使用路径传递参数,多条件模糊查询,就使用请求参数传递?
误区:restful风格下,不是所有请求参数都是路径传递!可以使用其他方式传递!
在 RESTful API 的设计中,路径和请求参数和请求体都是用来向服务器传递信息的方式。
- 对于查询用户详情,使用路径传递参数是因为这是一个单一资源的查询,即查询一条用户记录。使用路径参数可以明确指定所请求的资源,便于服务器定位并返回对应的资源,也符合 RESTful 风格的要求。
- 而对于多条件模糊查询,使用请求参数传递参数是因为这是一个资源集合的查询,即查询多条用户记录。使用请求参数可以通过组合不同参数来限制查询结果,路径参数的组合和排列可能会很多,不如使用请求参数更加灵活和简洁。
此外,还有一些通用的原则可以遵循:
- 路径参数应该用于指定资源的唯一标识或者 ID,而请求参数应该用于指定查询条件或者操作参数。
- 请求参数应该限制在 10 个以内,过多的请求参数可能导致接口难以维护和使用。
- 对于敏感信息,最好使用 POST 和请求体来传递参数。
后台接口实现
准备用户实体类,
准备用户Controller:
1 | /** |
SpringMVC其他扩展
全局异常处理机制
异常处理两种方式
开发过程中是不可避免地会出现各种异常情况的,例如网络连接异常、数据格式异常、空指针异常等等。异常的出现可能导致程序的运行出现问题,甚至直接导致程序崩溃。因此,在开发过程中,合理处理异常、避免异常产生、以及对异常进行有效的调试是非常重要的。
对于异常的处理,一般分为两种方式:
- 编程式异常处理:是指在代码中显式地编写处理异常的逻辑。它通常涉及到对异常类型的检测及其处理,例如使用 try-catch 块来捕获异常,然后在 catch 块中编写特定的处理代码,或者在 finally 块中执行一些清理操作。在编程式异常处理中,开发人员需要显式地进行异常处理,异常处理代码混杂在业务代码中,导致代码可读性较差。
- 声明式异常处理:则是将异常处理的逻辑从具体的业务逻辑中分离出来,通过配置等方式进行统一的管理和处理。在声明式异常处理中,开发人员只需要为方法或类标注相应的注解(如
@Throws或@ExceptionHandler),就可以处理特定类型的异常。相较于编程式异常处理,声明式异常处理可以使代码更加简洁、易于维护和扩展。
站在宏观角度来看待声明式事务处理:
整个项目从架构这个层面设计的异常处理的统一机制和规范。
一个项目中会包含很多个模块,各个模块需要分工完成。如果张三负责的模块按照 A 方案处理异常,李四负责的模块按照 B 方案处理异常……各个模块处理异常的思路、代码、命名细节都不一样,那么就会让整个项目非常混乱。
使用声明式异常处理,可以统一项目处理异常思路,项目更加清晰明了!
基于注解异常声明异常处理
声明异常处理控制器类
异常处理控制类,统一定义异常处理handler方法!
1 | /** |
声明异常处理hander方法
异常处理handler方法和普通的handler方法参数接收和响应都一致!
只不过异常处理handler方法要映射异常,发生对应的异常会调用!
普通的handler方法要使用@RequestMapping注解映射路径,发生对应的路径调用!
1 | /** |
配置文件扫描控制器类配置
确保异常处理控制类被扫描
1 | <!-- 扫描controller对应的包,将handler加入到ioc--> |
拦截器使用
拦截器概念
拦截器 Springmvc VS 过滤器 javaWeb:
- 相似点
- 拦截:必须先把请求拦住,才能执行后续操作
- 过滤:拦截器或过滤器存在的意义就是对请求进行统一处理
- 放行:对请求执行了必要操作后,放请求过去,让它访问原本想要访问的资源
- 不同点
- 工作平台不同
- 过滤器工作在 Servlet 容器中
- 拦截器工作在 SpringMVC 的基础上
- 拦截的范围
- 过滤器:能够拦截到的最大范围是整个 Web 应用
- 拦截器:能够拦截到的最大范围是整个 SpringMVC 负责的请求
- IOC 容器支持
- 过滤器:想得到 IOC 容器需要调用专门的工具方法,是间接的
- 拦截器:它自己就在 IOC 容器中,所以可以直接从 IOC 容器中装配组件,也就是可以直接得到 IOC 容器的支持
- 工作平台不同
选择:
功能需要如果用 SpringMVC 的拦截器能够实现,就不使用过滤器。
拦截器使用
- 创建拦截器类
1 | public class Process01Interceptor implements HandlerInterceptor { |
- 修改配置类添加拦截器
1 | //json数据处理,必须使用此注解,因为他会加入json处理器 |
- 配置详解
- 默认拦截全部
1 |
|
2. 精准配置
1 |
|
3. 排除配置
1 | //添加拦截器 |
- 多个拦截器执行顺序
- preHandle() 方法:SpringMVC 会把所有拦截器收集到一起,然后按照配置顺序调用各个 preHandle() 方法。
- postHandle() 方法:SpringMVC 会把所有拦截器收集到一起,然后按照配置相反的顺序调用各个 postHandle() 方法。
- afterCompletion() 方法:SpringMVC 会把所有拦截器收集到一起,然后按照配置相反的顺序调用各个 afterCompletion() 方法。
参数校验
在 Web 应用三层架构体系中,表述层负责接收浏览器提交的数据,业务逻辑层负责数据的处理。为了能够让业务逻辑层基于正确的数据进行处理,我们需要在表述层对数据进行检查,将错误的数据隔绝在业务逻辑层之外。
校验概述
JSR 303 是 Java 为 Bean 数据合法性校验提供的标准框架,它已经包含在 JavaEE 6.0 标准中。JSR 303 通过在 Bean 属性上标注类似于 @NotNull、@Max 等标准的注解指定校验规则,并通过标准的验证接口对Bean进行验证。
| 注解 | 规则 |
|---|---|
| @Null | 标注值必须为 null |
| @NotNull | 标注值不可为 null |
| @AssertTrue | 标注值必须为 true |
| @AssertFalse | 标注值必须为 false |
| @Min(value) | 标注值必须大于或等于 value |
| @Max(value) | 标注值必须小于或等于 value |
| @DecimalMin(value) | 标注值必须大于或等于 value |
| @DecimalMax(value) | 标注值必须小于或等于 value |
| @Size(max,min) | 标注值大小必须在 max 和 min 限定的范围内 |
| @Digits(integer,fratction) | 标注值值必须是一个数字,且必须在可接受的范围内 |
| @Past | 标注值只能用于日期型,且必须是过去的日期 |
| @Future | 标注值只能用于日期型,且必须是将来的日期 |
| @Pattern(value) | 标注值必须符合指定的正则表达式 |
JSR 303 只是一套标准,需要提供其实现才可以使用。Hibernate Validator 是 JSR 303 的一个参考实现,除支持所有标准的校验注解外,它还支持以下的扩展注解:
| 注解 | 规则 |
|---|---|
| 标注值必须是格式正确的 Email 地址 | |
| @Length | 标注值字符串大小必须在指定的范围内 |
| @NotEmpty | 标注值字符串不能是空字符串 |
| @Range | 标注值必须在指定的范围内 |
Spring 4.0 版本已经拥有自己独立的数据校验框架,同时支持 JSR 303 标准的校验框架。Spring 在进行数据绑定时,可同时调用校验框架完成数据校验工作。在SpringMVC 中,可直接通过注解驱动 @EnableWebMvc 的方式进行数据校验。Spring 的 LocalValidatorFactoryBean 既实现了 Spring 的 Validator 接口,也实现了 JSR 303 的 Validator 接口。只要在Spring容器中定义了一个LocalValidatorFactoryBean,即可将其注入到需要数据校验的 Bean中。Spring本身并没有提供JSR 303的实现,所以必须将JSR 303的实现者的jar包放到类路径下。
配置 @EnableWebMvc后,SpringMVC 会默认装配好一个 LocalValidatorFactoryBean,通过在处理方法的入参上标注 @Validated 注解即可让 SpringMVC 在完成数据绑定后执行数据校验的工作。
- 操作演示
- 导入依赖
1 | <!-- 校验注解 --> |
- 应用校验注解
1 | /** |
- handler标记和绑定错误收集
1 |
|
易混总结
@NotNull、@NotEmpty、@NotBlank 都是用于在数据校验中检查字段值是否为空的注解,但是它们的用法和校验规则有所不同。
@NotNull (包装类型不为null)
@NotNull 注解是 JSR 303 规范中定义的注解,当被标注的字段值为 null 时,会认为校验失败而抛出异常。该注解不能用于字符串类型的校验,若要对字符串进行校验,应该使用 @NotBlank 或 @NotEmpty 注解。
@NotEmpty (集合类型长度大于0)
@NotEmpty 注解同样是 JSR 303 规范中定义的注解,对于 CharSequence、Collection、Map 或者数组对象类型的属性进行校验,校验时会检查该属性是否为 Null 或者 size()==0,如果是的话就会校验失败。但是对于其他类型的属性,该注解无效。需要注意的是只校验空格前后的字符串,如果该字符串中间只有空格,不会被认为是空字符串,校验不会失败。
@NotBlank (字符串,不为null,切不为” “字符串)
@NotBlank 注解是 Hibernate Validator 附加的注解,对于字符串类型的属性进行校验,校验时会检查该属性是否为 Null 或 “” 或者只包含空格,如果是的话就会校验失败。需要注意的是,@NotBlank 注解只能用于字符串类型的校验。
总之,这三种注解都是用于校验字段值是否为空的注解,但是其校验规则和用法有所不同。在进行数据校验时,需要根据具体情况选择合适的注解进行校验。
SpringMVC总结
| 核心点 | 掌握目标 |
| springmvc框架 | 主要作用、核心组件、调用流程 |
| 简化参数接收 | 路径设计、参数接收、请求头接收、cookie接收 |
| 简化数据响应 | 模板页面、转发和重定向、JSON数据、静态资源 |
| restful风格设计 | 主要作用、具体规范、请求方式和请求参数选择 |
| 功能扩展 | 全局异常处理、拦截器、参数校验注解 |
SSM整合实战(略)
SpringBoot
版本:3.0.5
全新特性,快速整合掌握
SpringBoot3介绍
SpringBoot3简介
到目前为止,你已经学习了多种配置Spring程序的方式。但是无论使用XML、注解、Java配置类还是他们的混合用法,你都会觉得配置文件过于复杂和繁琐,让人头疼!
SpringBoot 帮我们简单、快速地创建一个独立的、生产级别的 Spring 应用(说明:SpringBoot底层是Spring),大多数 SpringBoot 应用只需要编写少量配置即可快速整合 Spring 平台以及第三方技术!
SpringBoot的主要目标是:
- 为所有 Spring 开发提供更快速、可广泛访问的入门体验。
- 开箱即用,设置合理的默认值,但是也可以根据需求进行适当的调整。
- 提供一系列大型项目通用的非功能性程序(如嵌入式服务器、安全性、指标、运行检查等)。
- 约定大于配置,基本不需要主动编写配置类、也不需要 XML 配置文件。
总结:简化开发,简化配置,简化整合,简化部署,简化监控,简化运维。
快速入门
场景:浏览器发送**/hello**请求,返回”Hello,Spring Boot 3!“
开发步骤
- 创建Maven工程
- 添加依赖(springboot父工程依赖 , web启动器依赖)
- 编写启动引导类(springboot项目运行的入口)
- 编写处理器Controller
- 启动项目
创建项目
添加依赖
3.1 添加父工程坐标
SpringBoot可以帮我们方便的管理项目依赖 , 在Spring Boot提供了一个名为spring-boot-starter-parent的工程,里面已经对各种常用依赖的版本进行了管理,我们的项目需要以这个项目为父工程,这样我们就不用操心依赖的版本问题了,需要什么依赖,直接引入坐标(不需要添加版本)即可!
1 | <!--所有springboot项目都必须继承自 spring-boot-starter-parent--> |
3.2 添加web启动器
为了让Spring Boot帮我们完成各种自动配置,我们必须引入Spring Boot提供的**自动配置依赖**,我们称为**启动器**。因为我们是web项目,这里我们引入web启动器,在 pom.xml 文件中加入如下依赖:
1 | <dependencies> |
创建启动类
创建package:com.atguigu
创建启动类:MainApplication
1 | package com.atguigu; |
编写处理器Controller
创建package:com.atguigu.controller
创建类:HelloController
注意: IoC和DI注解需要在启动类的同包或者子包下方可生效!无需指定,约束俗称。
1 | package com.atguigu.controller; |
- 启动测试
入门总结
为什么依赖不需要写版本?
- 每个boot项目都有一个父项目
spring-boot-starter-parent - parent的父项目是
spring-boot-dependencies - 父项目 版本仲裁中心,把所有常见的jar的依赖版本都声明好了。
- 比如:
mysql-connector-j
- 每个boot项目都有一个父项目
启动器(Starter)是何方神圣?
Spring Boot提供了一种叫做Starter的概念,它是一组预定义的依赖项集合,旨在简化Spring应用程序的配置和构建过程。Starter包含了一组相关的依赖项,以便在启动应用程序时自动引入所需的库、配置和功能。
主要作用如下:
- 简化依赖管理:Spring Boot Starter通过捆绑和管理一组相关的依赖项,减少了手动解析和配置依赖项的工作。只需引入一个相关的Starter依赖,即可获取应用程序所需的全部依赖。
- 自动配置:Spring Boot Starter在应用程序启动时自动配置所需的组件和功能。通过根据类路径和其他设置的自动检测,Starter可以自动配置Spring Bean、数据源、消息传递等常见组件,从而使应用程序的配置变得简单和维护成本降低。
- 提供约定优于配置:Spring Boot Starter遵循“约定优于配置”的原则,通过提供一组默认设置和约定,减少了手动配置的需要。它定义了标准的配置文件命名约定、默认属性值、日志配置等,使得开发者可以更专注于业务逻辑而不是繁琐的配置细节。
- 快速启动和开发应用程序:Spring Boot Starter使得从零开始构建一个完整的Spring Boot应用程序变得容易。它提供了主要领域(如Web开发、数据访问、安全性、消息传递等)的Starter,帮助开发者快速搭建一个具备特定功能的应用程序原型。
- 模块化和可扩展性:Spring Boot Starter的组织结构使得应用程序的不同模块可以进行分离和解耦。每个模块可以有自己的Starter和依赖项,使得应用程序的不同部分可以按需进行开发和扩展。
Spring Boot提供了许多预定义的Starter,例如spring-boot-starter-web用于构建Web应用程序,spring-boot-starter-data-jpa用于使用JPA进行数据库访问,spring-boot-starter-security用于安全认证和授权等等。
使用Starter非常简单,只需要在项目的构建文件(例如Maven的pom.xml)中添加所需的Starter依赖,Spring Boot会自动处理依赖管理和配置。
通过使用Starter,开发人员可以方便地引入和配置应用程序所需的功能,避免了手动添加大量的依赖项和编写冗长的配置文件的繁琐过程。同时,Starter也提供了一致的依赖项版本管理,确保依赖项之间的兼容性和稳定性。
spring boot提供的全部启动器地址:
命名规范:
- 官方提供的场景:命名为:
spring-boot-starter-* - 第三方提供场景:命名为:
*-spring-boot-starter
@SpringBootApplication注解的功效?
@SpringBootApplication添加到启动类上,是一个组合注解,他的功效有具体的子注解实现!
1 |
|
@SpringBootApplication注解是Spring Boot框架中的核心注解,它的主要作用是简化和加速Spring Boot应用程序的配置和启动过程。
具体而言,@SpringBootApplication注解起到以下几个主要作用:
1. 自动配置:@SpringBootApplication注解包含了@EnableAutoConfiguration注解,用于启用Spring Boot的自动配置机制。自动配置会根据应用程序的依赖项和类路径,自动配置各种常见的Spring配置和功能,减少开发者的手动配置工作。它通过智能地分析类路径、加载配置和条件判断,为应用程序提供适当的默认配置。
2. 组件扫描:@SpringBootApplication注解包含了@ComponentScan注解,用于自动扫描并加载应用程序中的组件,例如控制器(Controllers)、服务(Services)、存储库(Repositories)等。它默认会扫描@SpringBootApplication注解所在类的包及其子包中的组件,并将它们纳入Spring Boot应用程序的上下文中,使它们可被自动注入和使用。
3. 声明配置类:@SpringBootApplication注解本身就是一个组合注解,它包含了@Configuration注解,将被标注的类声明为配置类。配置类可以包含Spring框架相关的配置、Bean定义,以及其他的自定义配置。通过@SpringBootApplication注解,开发者可以将配置类与启动类合并在一起,使得配置和启动可以同时发生。
总的来说,@SpringBootApplication注解的主要作用是简化Spring Boot应用程序的配置和启动过程。它自动配置应用程序、扫描并加载组件,并将配置和启动类合二为一,简化了开发者的工作量,提高了开发效率。
SpringBoot3配置文件
统一配置管理概述
SpringBoot工程下,进行统一的配置管理,你想设置的任何参数(端口号、项目根路径、数据库连接信息等等)都集中到一个固定位置和命名的配置文件(application.properties或application.yml)中!
配置文件应该放置在Spring Boot工程的src/main/resources目录下。这是因为src/main/resources目录是Spring Boot默认的类路径(classpath),配置文件会被自动加载并可供应用程序访问。
功能配置参数说明:
细节总结:
- 集中式管理配置。统一在一个文件完成程序功能参数设置和自定义参数声明 。
- 位置:resources文件夹下,必须命名application 后缀 .properties / .yaml / .yml 。
- 如果同时存在application.properties | application.yml(.yaml) , properties的优先级更高。
- 配置基本都有默认值。
属性配置文件使用
配置文件
在 resource 文件夹下面新建 application.properties 配置文件
1 | # application.properties 为统一配置文件 |
- 读取配置文件
1 | package com.atguigu.properties; |
3. 测试效果
在controller注入,输出进行测试
1 |
|
YAML配置文件使用
yaml格式介绍
YAML(YAML Ain’t Markup Language)是一种基于层次结构的数据序列化格式,旨在提供一种易读、人类友好的数据表示方式。
与
.properties文件相比,YAML格式有以下优势:- 层次结构:YAML文件使用缩进和冒号来表示层次结构,使得数据之间的关系更加清晰和直观。这样可以更容易理解和维护复杂的配置,特别适用于深层次嵌套的配置情况。
- 自我描述性:YAML文件具有自我描述性,字段和值之间使用冒号分隔,并使用缩进表示层级关系。这使得配置文件更易于阅读和理解,并且可以减少冗余的标点符号和引号。
- 注释支持:YAML格式支持注释,可以在配置文件中添加说明性的注释,使配置更具可读性和可维护性。相比之下,
.properties文件不支持注释,无法提供类似的解释和说明。 - 多行文本:YAML格式支持多行文本的表示,可以更方便地表示长文本或数据块。相比之下,
.properties文件需要使用转义符或将长文本拆分为多行。 - 类型支持:YAML格式天然支持复杂的数据类型,如列表、映射等。这使得在配置文件中表示嵌套结构或数据集合更加容易,而不需要进行额外的解析或转换。
- 更好的可读性:由于YAML格式的特点,它更容易被人类读懂和解释。它减少了配置文件中需要的特殊字符和语法,让配置更加清晰明了,从而减少了错误和歧义。
综上所述,YAML格式相对于
.properties文件具有更好的层次结构表示、自我描述性、注释支持、多行文本表示、复杂数据类型支持和更好的可读性。这些特点使YAML成为一种有力的配置文件格式,尤其适用于复杂的配置需求和人类可读的场景。然而,选择使用YAML还是.properties取决于实际需求和团队的偏好,简单的配置可以使用.properties,而复杂的配置可以选择YAML以获得更多的灵活性和可读性yaml语法说明
- 数据结构用树形结构呈现,通过缩进来表示层级,
- 连续的项目(集合)通过减号 ” - ” 来表示
- 键值结构里面的key/value对用冒号 ” : ” 来分隔。
- YAML配置文件的扩展名是yaml 或 yml
- 例如:
1 | # YAML配置文件示例 |
- 配置文件
1 | spring: |
读取配置文件
读取方式和properties一致
测试效果
在controller注入,输出进行测试
批量配置文件注入
@ConfigurationProperties是SpringBoot提供的重要注解, 他可以将一些配置属性批量注入到bean对象。
创建类,添加属性和注解
在类上通过@ConfigurationProperties注解声明该类要读取属性配置
prefix=”spring.jdbc.datasource” 读取属性文件中前缀为spring.jdbc.datasource的值。前缀和属性名称和配置文件中的key必须要保持一致才可以注入成功
1 | package com.atguigu.properties; |
多环境配置和使用
需求
在Spring Boot中,可以使用多环境配置来根据不同的运行环境(如开发、测试、生产)加载不同的配置。SpringBoot支持多环境配置让应用程序在不同的环境中使用不同的配置参数,例如数据库连接信息、日志级别、缓存配置等。
以下是实现Spring Boot多环境配置的常见方法:
- 属性文件分离:将应用程序的配置参数分离到不同的属性文件中,每个环境对应一个属性文件。例如,可以创建
application-dev.properties、application-prod.properties和application-test.properties等文件。在这些文件中,可以定义各自环境的配置参数,如数据库连接信息、端口号等。然后,在application.properties中通过spring.profiles.active属性指定当前使用的环境。Spring Boot会根据该属性来加载对应环境的属性文件,覆盖默认的配置。 - YAML配置文件:与属性文件类似,可以将配置参数分离到不同的YAML文件中,每个环境对应一个文件。例如,可以创建
application-dev.yml、application-prod.yml和application-test.yml等文件。在这些文件中,可以使用YAML语法定义各自环境的配置参数。同样,通过spring.profiles.active属性指定当前的环境,Spring Boot会加载相应的YAML文件。 - 命令行参数(动态):可以通过命令行参数来指定当前的环境。例如,可以使用
--spring.profiles.active=dev来指定使用开发环境的配置。
通过上述方法,Spring Boot会根据当前指定的环境来加载相应的配置文件或参数,从而实现多环境配置。这样可以简化在不同环境之间的配置切换,并且确保应用程序在不同环境中具有正确的配置。
- 属性文件分离:将应用程序的配置参数分离到不同的属性文件中,每个环境对应一个属性文件。例如,可以创建
多环境配置(基于方式b实践)
创建开发、测试、生产三个环境的配置文件
application-dev.yml(开发)
1 | spring: |
application-test.yml(测试)
1 | spring: |
application-prod.yml(生产)
1 | spring: |
- 环境激活
1 | spring: |
测试效果
注意 :
如果设置了spring.profiles.active,并且和application有重叠属性,以active设置优先。
如果设置了spring.profiles.active,和application无重叠属性,application设置依然生效!
SpringBoot3整合SpringMVC
实现过程
- 创建程序
- 引入依赖
- 创建启动类
- 创建实体类
- 编写Controller
- 访问测试
web相关配置
位置:application.yml
1 | # web相关的配置 |
当涉及Spring Boot的Web应用程序配置时,以下是五个重要的配置参数:
server.port: 指定应用程序的HTTP服务器端口号。默认情况下,Spring Boot使用8080作为默认端口。您可以通过在配置文件中设置server.port来更改端口号。server.servlet.context-path: 设置应用程序的上下文路径。这是应用程序在URL中的基本路径。默认情况下,上下文路径为空。您可以通过在配置文件中设置server.servlet.context-path属性来指定自定义的上下文路径。spring.mvc.view.prefix和spring.mvc.view.suffix: 这两个属性用于配置视图解析器的前缀和后缀。视图解析器用于解析控制器返回的视图名称,并将其映射到实际的视图页面。spring.mvc.view.prefix定义视图的前缀,spring.mvc.view.suffix定义视图的后缀。spring.resources.static-locations: 配置静态资源的位置。静态资源可以是CSS、JavaScript、图像等。默认情况下,Spring Boot会将静态资源放在classpath:/static目录下。您可以通过在配置文件中设置spring.resources.static-locations属性来自定义静态资源的位置。spring.http.encoding.charset和spring.http.encoding.enabled: 这两个属性用于配置HTTP请求和响应的字符编码。spring.http.encoding.charset定义字符编码的名称(例如UTF-8),spring.http.encoding.enabled用于启用或禁用字符编码的自动配置。
这些是在Spring Boot的配置文件中与Web应用程序相关的一些重要配置参数。根据您的需求,您可以在配置文件中设置这些参数来定制和配置您的Web应用程序
静态资源处理
在WEB开发中我们需要引入一些静态资源 , 例如 : HTML , CSS , JS , 图片等 , 如果是普通的项目静态资源可以放在项目的webapp目录下。现在使用Spring Boot做开发 , 项目中没有webapp目录 , 我们的项目是一个jar工程,那么就没有webapp,我们的静态资源该放哪里呢?
默认路径
在springboot中就定义了静态资源的默认查找路径:
1 | package org.springframework.boot.autoconfigure.web; |
默认的静态资源路径为:
· classpath:/META-INF/resources/
· classpath:/resources/
· classpath:/static/
· classpath:/public/
我们只要静态资源放在这些目录中任何一个,SpringMVC都会帮我们处理。 我们习惯会把静态资源放在classpath:/static/ 目录下。在resources目录下创建index.html文件
- 覆盖路径
1 | # web相关的配置 |
自定义拦截器(SpringMVC配置)
- 拦截器声明
1 | package com.atguigu.interceptor; |
拦截器配置
正常使用配置类,只要保证,配置类要在启动类的同包或者子包方可生效!
1 | package com.atguigu.config; |
- 拦截器效果测试
SpringBoot3整合Druid数据源
- 创建程序
- 引入依赖
- 启动类
- 配置文件编写
> 添加druid连接池的基本配置
1 | spring: |
编写Controller
启动测试
问题解决
通过源码分析,druid-spring-boot-3-starter目前最新版本是1.2.18,虽然适配了SpringBoot3,但缺少自动装配的配置文件,需要手动在resources目录下创建META-INF/spring/org.springframework.boot.autoconfigure.AutoConfiguration.imports,文件内容如下!
1 | com.alibaba.druid.spring.boot3.autoconfigure.DruidDataSourceAutoConfigure |
SpringBoot3整合Mybatis
MyBatis整合步骤
- 导入依赖:在您的Spring Boot项目的构建文件(如pom.xml)中添加MyBatis和数据库驱动的相关依赖。例如,如果使用MySQL数据库,您需要添加MyBatis和MySQL驱动的依赖。
- 配置数据源:在
application.properties或application.yml中配置数据库连接信息,包括数据库URL、用户名、密码、mybatis的功能配置等。 - 创建实体类:创建与数据库表对应的实体类。
- 创建Mapper接口:创建与数据库表交互的Mapper接口。
- 创建Mapper接口SQL实现: 可以使用mapperxml文件或者注解方式
- 创建程序启动类
- 注解扫描:在Spring Boot的主应用类上添加
@MapperScan注解,用于扫描和注册Mapper接口。 - 使用Mapper接口:在需要使用数据库操作的地方,通过依赖注入或直接实例化Mapper接口,并调用其中的方法进行数据库操作。
Mybatis整合实践
- 创建项目
- 导入依赖
- 配置文件
1 | server: |
实体类准备
Mapper接口准备
Mapper接口实现(XML)
位置:resources/mapper/UserMapper.xml
1 | <?xml version="1.0" encoding="UTF-8" ?> |
- 编写三层架构代码
- 启动类和接口扫描
1 | //mapper接口扫描配置 |
- 启动测试
声明式事务整合配置
注:SpringBoot项目会自动配置一个 DataSourceTransactionManager,所以我们只需在方法(或者类)加上 @Transactional 注解,就自动纳入 Spring 的事务管理了
1 |
|
AOP整合配置
依赖导入:
1 | <dependency> |
直接使用aop注解即可:
1 |
|
SpringBoot3项目打包和运行
添加打包插件
在Spring Boot项目中添加
spring-boot-maven-plugin插件是为了支持将项目打包成可执行的可运行jar包。如果不添加spring-boot-maven-plugin插件配置,使用常规的java -jar命令来运行打包后的Spring Boot项目是无法找到应用程序的入口点,因此导致无法运行。
1 | <!-- SpringBoot应用打包插件--> |
执行打包
在idea点击package进行打包
可以在编译的target文件中查看jar包
命令启动和参数说明
java -jar命令用于在Java环境中执行可执行的JAR文件。下面是关于java -jar命令的说明:
1 | 命令格式:java -jar [选项] [参数] <jar文件名> |
-D<name>=<value>:设置系统属性,可以通过System.getProperty()方法在应用程序中获取该属性值。例如:java -jar -Dserver.port=8080 myapp.jar。-X:设置JVM参数,例如内存大小、垃圾回收策略等。常用的选项包括:-Xmx<size>:设置JVM的最大堆内存大小,例如-Xmx512m表示设置最大堆内存为512MB。-Xms<size>:设置JVM的初始堆内存大小,例如-Xms256m表示设置初始堆内存为256MB。
-Dspring.profiles.active=<profile>:指定Spring Boot的激活配置文件,可以通过application-<profile>.properties或application-<profile>.yml文件来加载相应的配置。例如:java -jar -Dspring.profiles.active=dev myapp.jar。
注意: -D 参数必须要在jar之前!否者不生效!
Mybatis-Plus
版本:3.5.3.1
全自动or框架,效率更高
MyBatis-Plus快速入门
简介
MyBatis-Plus (opens new window)(简称 MP)是一个 MyBatis (opens new window) 的增强工具,在 MyBatis 的基础上只做增强不做改变,为简化开发、提高效率而生。
特性:
- 无侵入:只做增强不做改变,引入它不会对现有工程产生影响,如丝般顺滑
- 损耗小:启动即会自动注入基本 CURD,性能基本无损耗,直接面向对象操作
- 强大的 CRUD 操作:内置通用 Mapper、通用 Service,仅仅通过少量配置即可实现单表大部分 CRUD 操作,更有强大的条件构造器,满足各类使用需求
- 支持 Lambda 形式调用:通过 Lambda 表达式,方便的编写各类查询条件,无需再担心字段写错
- 支持主键自动生成:支持多达 4 种主键策略(内含分布式唯一 ID 生成器 - Sequence),可自由配置,完美解决主键问题
- 支持 ActiveRecord 模式:支持 ActiveRecord 形式调用,实体类只需继承 Model 类即可进行强大的 CRUD 操作
- 支持自定义全局通用操作:支持全局通用方法注入( Write once, use anywhere )
- 内置代码生成器:采用代码或者 Maven 插件可快速生成 Mapper 、 Model 、 Service 、 Controller 层代码,支持模板引擎,更有超多自定义配置等您来使用
- 内置分页插件:基于 MyBatis 物理分页,开发者无需关心具体操作,配置好插件之后,写分页等同于普通 List 查询
- 分页插件支持多种数据库:支持 MySQL、MariaDB、Oracle、DB2、H2、HSQL、SQLite、Postgre、SQLServer 等多种数据库
- 内置性能分析插件:可输出 SQL 语句以及其执行时间,建议开发测试时启用该功能,能快速揪出慢查询
- 内置全局拦截插件:提供全表 delete 、 update 操作智能分析阻断,也可自定义拦截规则,预防误操作
支持数据库:
- MySQL,Oracle,DB2,H2,HSQL,SQLite,PostgreSQL,SQLServer,Phoenix,Gauss ,ClickHouse,Sybase,OceanBase,Firebird,Cubrid,Goldilocks,csiidb,informix,TDengine,redshift
- 达梦数据库,虚谷数据库,人大金仓数据库,南大通用(华库)数据库,南大通用数据库,神通数据库,瀚高数据库,优炫数据库
mybatis-plus总结:
自动生成单表的CRUD功能
提供丰富的条件拼接方式
全自动ORM类型持久层框架
快速入门
准备数据库脚本
现有一张
User表,其表结构如下:
| id | name | age | |
|---|---|---|---|
| 1 | Jone | 18 | test1@baomidou.com |
| 2 | Jack | 20 | test2@baomidou.com |
| 3 | Tom | 28 | test3@baomidou.com |
| 4 | Sandy | 21 | test4@baomidou.com |
| 5 | Billie | 24 | test5@baomidou.com |
1 | DROP TABLE IF EXISTS user; |
准备boot工程
导入依赖
配置文件和启动类
完善连接池配置:
文件夹:META-INF.spring
文件名:
org.springframework.boot.autoconfigure.AutoConfiguration.imports
内容:com.alibaba.druid.spring.boot3.autoconfigure.DruidDataSourceAutoConfigure
application.yaml
功能编码
编写实体类
User.java(此处使用了 Lombok 简化代码)测试和使用
添加测试类,进行功能测试:
1 | //springboot下测试环境注解 |
小结
通过以上几个简单的步骤,我们就实现了 User 表的 CRUD 功能,甚至连 XML 文件都不用编写!
从以上步骤中,我们可以看到集成
MyBatis-Plus非常的简单,只需要引入 starter 工程,并配置 mapper 扫描路径即可。
MyBatis-Plus核心功能
基于Mapper接口CRUD
通用 CRUD 封装BaseMapper (opens new window)接口,
Mybatis-Plus启动时自动解析实体表关系映射转换为Mybatis内部对象注入容器! 内部包含常见的单表操作!
Insert方法
1 | // 插入一条记录 |
Delete方法
1 | // 根据 entity 条件,删除记录 |
| 类型 | 参数名 | 描述 |
|---|---|---|
| Wrapper |
wrapper | 实体对象封装操作类(可以为 null) |
| Collection<? extends Serializable> | idList | 主键 ID 列表(不能为 null 以及 empty) |
| Serializable | id | 主键 ID |
| Map<String, Object> | columnMap | 表字段 map 对象 |
Update方法
1 | // 根据 whereWrapper 条件,更新记录 |
| 类型 | 参数名 | 描述 |
|---|---|---|
| T | entity | 实体对象 (set 条件值,可为 null) |
| Wrapper |
updateWrapper | 实体对象封装操作类(可以为 null,里面的 entity 用于生成 where 语句) |
Select方法
1 | // 根据 ID 查询 |
参数说明
| 类型 | 参数名 | 描述 |
|---|---|---|
| Serializable | id | 主键 ID |
| Wrapper |
queryWrapper | 实体对象封装操作类(可以为 null) |
| Collection<? extends Serializable> | idList | 主键 ID 列表(不能为 null 以及 empty) |
| Map<String, Object> | columnMap | 表字段 map 对象 |
| IPage |
page | 分页查询条件(可以为 RowBounds.DEFAULT) |
自定义和多表映射
mybatis-plus的默认mapperxml位置
1 | mybatis-plus: # mybatis-plus的配置 |
自定义mapper方法:
1 | public interface UserMapper extends BaseMapper<User> { |
基于Service接口CRUD
通用 Service CRUD 封装IService (opens new window)接口,进一步封装 CRUD 采用 get 查询单行 remove 删除 list 查询集合 page 分页 前缀命名方式区分 Mapper 层避免混淆,
对比Mapper接口CRUD区别:
- service添加了批量方法
- service层的方法自动添加事务
使用Iservice接口方式
接口继承IService接口
1 | public interface UserService extends IService<User> { |
类继承ServiceImpl实现类
1 |
|
CRUD方法介绍
1 | 保存: |
分页查询实现
- 导入分页插件
1 |
|
- 使用分页查询
1 |
|
- 自定义的mapper方法使用分页
方法
1 | //传入参数携带Ipage接口 |
接口实现
1 | <select id="selectPageVo" resultType="xxx.xxx.xxx.User"> |
测试
1 |
|
条件构造器使用
条件构造器作用
实例代码:
1 | QueryWrapper<User> queryWrapper = new QueryWrapper<>(); |
使用MyBatis-Plus的条件构造器,你可以构建灵活、高效的查询条件,而不需要手动编写复杂的 SQL 语句。它提供了许多方法来支持各种条件操作符,并且可以通过链式调用来组合多个条件。这样可以简化查询的编写过程,并提高开发效率。
条件构造器继承结构
条件构造器类结构:
Wrapper : 条件构造抽象类,最顶端父类
- AbstractWrapper : 用于查询条件封装,生成 sql 的 where 条件
- QueryWrapper : 查询/删除条件封装
- UpdateWrapper : 修改条件封装
- AbstractLambdaWrapper : 使用Lambda 语法
- LambdaQueryWrapper :用于Lambda语法使用的查询Wrapper
- LambdaUpdateWrapper : Lambda 更新封装Wrapper
基于QueryWrapper 组装条件
组装查询条件:
1 |
|
组装排序条件:
1 |
|
组装删除条件:
1 |
|
and和or关键字使用(修改):
1 |
|
指定列映射查询:
1 |
|
condition判断组织条件:
1 |
|
基于 UpdateWrapper组装条件
使用queryWrapper:
1 |
|
注意:使用queryWrapper + 实体类形式可以实现修改,但是无法将列值修改为null值!
使用updateWrapper:
1 |
|
使用updateWrapper可以随意设置列的值!!
基于LambdaQueryWrapper组装条件
- LambdaQueryWrapper对比QueryWrapper优势
QueryWrapper 示例代码:
1 | QueryWrapper<User> queryWrapper = new QueryWrapper<>(); |
LambdaQueryWrapper 示例代码:
1 | LambdaQueryWrapper<User> lambdaQueryWrapper = new LambdaQueryWrapper<>(); |
从上面的代码对比可以看出,相比于 QueryWrapper,LambdaQueryWrapper 使用了实体类的属性引用(例如 User::getName、User::getAge),而不是字符串来表示字段名,这提高了代码的可读性和可维护性。
- lambda表达式回顾
Lambda 表达式是 Java 8 引入的一种函数式编程特性,它提供了一种更简洁、更直观的方式来表示匿名函数或函数式接口的实现。Lambda 表达式可以用于简化代码,提高代码的可读性和可维护性。
Lambda 表达式的语法可以分为以下几个部分:
参数列表: 参数列表用小括号
()括起来,可以指定零个或多个参数。如果没有参数,可以省略小括号;如果只有一个参数,可以省略小括号。示例:
(a, b),x ->,() ->箭头符号: 箭头符号
->分割参数列表和 Lambda 表达式的主体部分。示例:
->Lambda 表达式的主体: Lambda 表达式的主体部分可以是一个表达式或一个代码块。如果是一个表达式,可以省略 return 关键字;如果是多条语句的代码块,需要使用大括号
{}括起来,并且需要明确指定 return 关键字。示例:
- 单个表达式:
x -> x * x - 代码块:
(x, y) -> { int sum = x + y; return sum; }
- 单个表达式:
Lambda 表达式的语法可以更具体地描述如下:
1 | // 使用 Lambda 表达式实现一个接口的方法 |
3. 方法引用回顾:
方法引用是 Java 8 中引入的一种语法特性,它提供了一种简洁的方式来直接引用已有的方法或构造函数。方法引用可以替代 Lambda 表达式,使代码更简洁、更易读。
Java 8 支持以下几种方法引用的形式:
- 静态方法引用: 引用静态方法,语法为
类名::静态方法名。 - 实例方法引用: 引用实例方法,语法为
实例对象::实例方法名。 - 对象方法引用: 引用特定对象的实例方法,语法为
类名::实例方法名。 - 构造函数引用: 引用构造函数,语法为
类名::new。
演示代码:
1 | import java.util.Arrays; |
4. lambdaQueryWrapper使用案例:
1 |
|
基于LambdaUpdateWrapper组装条件
使用案例:
1 |
|
核心注解使用
理解和介绍
MyBatis-Plus是一个基于MyBatis框架的增强工具,提供了一系列简化和增强的功能,用于加快开发人员在使用MyBatis进行数据库访问时的效率。
MyBatis-Plus提供了一种基于注解的方式来定义和映射数据库操作,其中的注解起到了重要作用。
理解:
1 | public interface UserMapper extends BaseMapper<User> { |
此接口对应的方法为什么会自动触发 user表的crud呢?
默认情况下, 根据指定的<实体类>的名称对应数据库表名,属性名对应数据库的列名!
但是不是所有数据库的信息和实体类都完全映射!
例如: 表名 t_user → 实体类 User 这时候就不对应了!
自定义映射关系就可以使用mybatis-plus提供的注解即可!
- @TableName注解
- 描述:表名注解,标识实体类对应的表
- 使用位置:实体类
1 | //对应数据库表名 |
特殊情况:如果表名和实体类名相同(忽略大小写)可以省略该注解!
其他解决方案:全局设置前缀 ([https://www.baomidou.com/pages/56bac0/#基本配置](https://www.baomidou.com/pages/56bac0/#基本配置))
1 | mybatis-plus: # mybatis-plus的配置 |
- @TableId 注解
- 描述:主键注解
- 使用位置:实体类主键字段
1 |
|
| 属性 | 类型 | 必须指定 | 默认值 | 描述 |
|---|---|---|---|---|
| value | String | 否 | “” | 主键字段名 |
| type | Enum | 否 | IdType.NONE | 指定主键类型 |
[IdType](https://github.com/baomidou/mybatis-plus/blob/3.0/mybatis-plus-annotation/src/main/java/com/baomidou/mybatisplus/annotation/IdType.java)属性可选值:
| 值 | 描述 |
|---|---|
| AUTO | 数据库 ID 自增 (mysql配置主键自增长) |
| ASSIGN_ID(默认) | 分配 ID(主键类型为 Number(Long )或 String)(since 3.3.0),使用接口IdentifierGenerator的方法nextId(默认实现类为DefaultIdentifierGenerator雪花算法) |
全局配置修改主键策略:
1 | mybatis-plus: |
在以下场景下,添加`@TableId`注解是必要的:
1. 实体类的字段与数据库表的主键字段不同名:如果实体类中的字段与数据库表的主键字段不一致,需要使用`@TableId`注解来指定实体类中表示主键的字段。
2. 主键生成策略不是默认策略:如果需要使用除了默认主键生成策略以外的策略,也需要添加`@TableId`注解,并通过`value`属性指定生成策略。
雪花算法使用场景
雪花算法(Snowflake Algorithm)是一种用于生成唯一ID的算法。它由Twitter公司提出,用于解决分布式系统中生成全局唯一ID的需求。
在传统的自增ID生成方式中,使用单点数据库生成ID会成为系统的瓶颈,而雪花算法通过在分布式系统中生成唯一ID,避免了单点故障和性能瓶颈的问题。
雪花算法生成的ID是一个64位的整数,由以下几个部分组成:
- 时间戳:41位,精确到毫秒级,可以使用69年。
- 节点ID:10位,用于标识分布式系统中的不同节点。
- 序列号:12位,表示在同一毫秒内生成的不同ID的序号。
通过将这三个部分组合在一起,雪花算法可以在分布式系统中生成全局唯一的ID,并保证ID的生成顺序性。
雪花算法的工作方式如下:
- 当前时间戳从某一固定的起始时间开始计算,可以用于计算ID的时间部分。
- 节点ID是分布式系统中每个节点的唯一标识,可以通过配置或自动分配的方式获得。
- 序列号用于记录在同一毫秒内生成的不同ID的序号,从0开始自增,最多支持4096个ID生成。
需要注意的是,雪花算法依赖于系统的时钟,需要确保系统时钟的准确性和单调性,否则可能会导致生成的ID不唯一或不符合预期的顺序。
雪花算法是一种简单但有效的生成唯一ID的算法,广泛应用于分布式系统中,如微服务架构、分布式数据库、分布式锁等场景,以满足全局唯一标识的需求。
你需要记住的: 雪花算法生成的数字,需要使用Long 或者 String类型主键!!
@TableField
描述:字段注解(非主键)
1 |
|
MyBatis-Plus会自动开启驼峰命名风格映射!!!
MyBatis-Plus高级扩展
逻辑删除实现
概念:
逻辑删除,可以方便地实现对数据库记录的逻辑删除而不是物理删除。逻辑删除是指通过更改记录的状态或添加标记字段来模拟删除操作,从而保留了删除前的数据,便于后续的数据分析和恢复。
- 物理删除:真实删除,将对应数据从数据库中删除,之后查询不到此条被删除的数据
- 逻辑删除:假删除,将对应数据中代表是否被删除字段的状态修改为“被删除状态”,之后在数据库中仍旧能看到此条数据记录
逻辑删除实现:
- 数据库和实体类添加逻辑删除字段
表添加逻辑删除字段
可以是一个布尔类型、整数类型或枚举类型。
1 | ALTER TABLE USER ADD deleted INT DEFAULT 0 ; # int 类型 1 逻辑删除 0 未逻辑删除 |
2. 实体类添加逻辑删除属性
1 | @Data |
- 指定逻辑删除字段和属性值
- 单一指定
1 | @Data |
2. 全局指定
1 | mybatis-plus: |
演示逻辑删除操作
逻辑删除以后,没有真正的删除语句,删除改为修改语句!
删除代码:
1 | //逻辑删除 |
执行效果:
JDBC Connection [com.alibaba.druid.proxy.jdbc.ConnectionProxyImpl@5871a482] will not be managed by Spring
==> Preparing: UPDATE user SET deleted=1 WHERE id=? AND deleted=0
==> Parameters: 5(Integer)
<== Updates: 1
4. 测试查询数据
1 |
|
乐观锁实现
悲观锁和乐观锁场景和介绍
**并发问题场景演示:**
**解决思路: **
乐观锁和悲观锁是在并发编程中用于处理并发访问和资源竞争的两种不同的锁机制!!
悲观锁:
悲观锁的基本思想是,在整个数据访问过程中,将共享资源锁定,以确保其他线程或进程不能同时访问和修改该资源。悲观锁的核心思想是”先保护,再修改”。在悲观锁的应用中,线程在访问共享资源之前会获取到锁,并在整个操作过程中保持锁的状态,阻塞其他线程的访问。只有当前线程完成操作后,才会释放锁,让其他线程继续操作资源。这种锁机制可以确保资源独占性和数据的一致性,但是在高并发环境下,悲观锁的效率相对较低。
乐观锁:
乐观锁的基本思想是,认为并发冲突的概率较低,因此不需要提前加锁,而是在数据更新阶段进行冲突检测和处理。乐观锁的核心思想是”先修改,后校验”。在乐观锁的应用中,线程在读取共享资源时不会加锁,而是记录特定的版本信息。当线程准备更新资源时,会先检查该资源的版本信息是否与之前读取的版本信息一致,如果一致则执行更新操作,否则说明有其他线程修改了该资源,需要进行相应的冲突处理。乐观锁通过避免加锁操作,提高了系统的并发性能和吞吐量,但是在并发冲突较为频繁的情况下,乐观锁会导致较多的冲突处理和重试操作。
理解点: 悲观锁和乐观锁是两种解决并发数据问题的思路,不是具体技术!!!
**具体技术和方案:**
1. 乐观锁实现方案和技术:
- 版本号/时间戳:为数据添加一个版本号或时间戳字段,每次更新数据时,比较当前版本号或时间戳与期望值是否一致,若一致则更新成功,否则表示数据已被修改,需要进行冲突处理。
- CAS(Compare-and-Swap):使用原子操作比较当前值与旧值是否一致,若一致则进行更新操作,否则重新尝试。
- 无锁数据结构:采用无锁数据结构,如无锁队列、无锁哈希表等,通过使用原子操作实现并发安全。
2. 悲观锁实现方案和技术:
- 锁机制:使用传统的锁机制,如互斥锁(Mutex Lock)或读写锁(Read-Write Lock)来保证对共享资源的独占访问。
- 数据库锁:在数据库层面使用行级锁或表级锁来控制并发访问。
- 信号量(Semaphore):使用信号量来限制对资源的并发访问。
**介绍版本号乐观锁技术的实现流程:**
- 每条数据添加一个版本号字段version
- 取出记录时,获取当前 version
- 更新时,检查获取版本号是不是数据库当前最新版本号
- 如果是[证明没有人修改数据], 执行更新, set 数据更新 , version = version+ 1
- 如果 version 不对[证明有人已经修改了],我们现在的其他记录就是失效数据!就更新失败
使用mybatis-plus数据使用乐观锁
1. 添加版本号更新插件
1 |
|
2. 乐观锁字段添加@Version注解
注意: 数据库也需要添加version字段
1 | ALTER TABLE USER ADD VERSION INT DEFAULT 1 ; # int 类型 乐观锁字段 |
- 支持的数据类型只有:int,Integer,long,Long,Date,Timestamp,LocalDateTime
- 仅支持 `updateById(id)` 与 `update(entity, wrapper)` 方法
1 |
|
3. 正常更新使用即可
1 | //演示乐观锁生效场景 |
防全表更新和删除实现
针对 update 和 delete 语句 作用: 阻止恶意的全表更新删除
添加防止全表更新和删除拦截器
1 |
|
测试全部更新或者删除
1 |
|
MyBatis-Plus代码生成器(MyBatisX插件)
Mybatisx插件逆向工程
MyBatis-Plus为我们提供了强大的mapper和service模板,能够大大的提高开发效率
但是在真正开发过程中,MyBatis-Plus并不能为我们解决所有问题,例如一些复杂的SQL,多表联查,我们就需要自己去编写代码和SQL语句,我们该如何快速的解决这个问题呢,这个时候可以使用MyBatisX插件
MyBatisX一款基于 IDEA 的快速开发插件,为效率而生。
MyBatisX快速代码生成
使用mybatisX插件,自动生成sql语句实现
https://baomidou.com/pages/ba5b24/#功能
微头条实战
Original link: http://example.com/2023/08/29/offer-SSM/
Copyright Notice: 转载请注明出处.