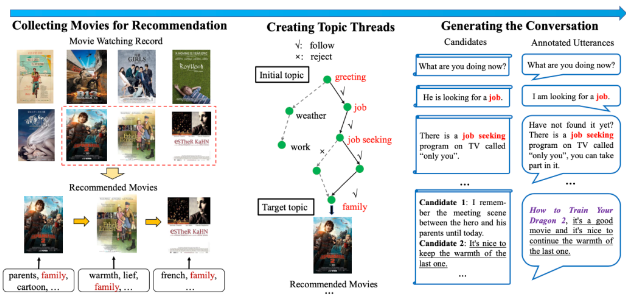
Java基础 Java程序编写和执行流程
编写。 .java结尾的源文件
编译。 对源文件编译成.class, “javac xxx.java”
运行。 “java 字节码文件名”
企业真题(一) 1.一个”.java”源文件中是否可以包括多个类?有什么限制(明*数据) 是!
一个源文件中可以声明多个类,但是最多只能有一个类使用public进行声明。
2.Java 的优势(阿**巴)
跨平台型
安全性高
简单性
高性能
面向对象性
健壮性
3.常用的几个命令行操作都有哪些?(至少4个)(北京数字**) 略
4.Java 中是否存在内存溢出、内存泄漏?如何解决?举例说明(拼*多) 存在!
不能举例。
5. 如何看待Java是一门半编译半解释型的语言(携*) 关键字 特点:关键字都是小写(class,void,static,public)
标识符 命名规则:
由 26 个英文字母大小写,0-9 ,_或 $ 组成
数字不可以开头。
不可以使用关键字和保留字,但能包含关键字和保留字。
Java 中严格区分大小写,长度无限制。
标识符不能包含空格。
包名:多单词组成时所有字母都小写:xxxyyyzzz。
类名、接口名:多单词组成时,所有单词的首字母大写:XxxYyyZzz
变量名、方法名:多单词组成时,第一个单词首字母小写,第二个单词开始每个单
常量名:所有字母都大写。多单词时每个单词用下划线连接:XXX_YYY_ZZZ
变量 注意:
Java 中每个变量必须先声明,后使用。
使用变量名来访问这块区域的数据。
变量的作用域:其定义所在的一对{ }内。
变量只有在其作用域内才有效。出了作用域,变量不可以再被调用。
同一个作用域内,不能定义重名的变量。
基本数据类型 整数类型:byte、short、int、long
定义 long 类型的变量,赋值时需要以”l”或”L”作为后缀。
Java 程序中变量通常声明为 int 型,除非不足以表示较大的数,才使用 long。
Java 的整型常量默认为 int 型。
浮点类型:float、double
float:尾数可以精确到 7 位有效数字
double:精度是 float 的两倍
定义 float 类型的变量,赋值时需要以”f”或”F”作为后缀。
Java 的浮点型常量默认为 double 型。
并不是所有的小数都能可以精确的用二进制浮点数表示。二进制浮点数不能精确的表
浮点类型 float、double 的数据不适合在不容许舍入误差的金融计算领域。如果需要精确数字计算或保留指定位数的精度,需要使用 BigDecimal 类。
字符类型:char
形式 1:使用单引号(‘ ‘)括起来的单个字符。
形式 2:直接使用 Unicode 值来表示字符型常量:‘\uXXXX’。其中,
形式 3:Java 中还允许使用转义字符‘\’来将其后的字符转变为特殊字符
布尔类型:boolean
boolean 类型用来判断逻辑条件,一般用于流程控制语句中
boolean 类型数据只有两个值:true、false,无其它;不可以使用 0 或非 0 的整数替代 false 和 true
基本数据类型变量间运算规则 自动类型提升 规则:将取值范围小(或容量小)的类型自动提升为取值范围大(或容量大)的类型 。
当存储范围小的数据类型与存储范围大的数据类型变量一起混合运算时,会按照其中最大的类型运算
当 byte,short,char 数据类型的变量进行算术运算时,按照 int 类型处理。
强制类型转换 规则:将取值范围大(或容量大)的类型强制转换成取值范围小(或容量小)的类型。
当把存储范围大的值(常量值、变量的值、表达式计算的结果值)强制转
double d = 1.2;
int num = (int)d;//损失精度
int i = 200;
byte b = (byte)i;//溢出
声明 long 类型变量时,可以出现省略后缀的情况。float 则不同。
基本数据类型与 String 的运算 String 不是基本数据类型,属于引用数据类型
任意八种基本数据类型的数据与 String 类型只能进行连接“+”运算,且结果
String 类型不能通过强制类型()转换,转为其他的类型;借助包装类的方法
常识:进制的认识
熟悉:二进制(以0B、0b开头)、十进制、八进制(以0开头)、十六进制(以0x或0X开头)的声明方式。
二进制的理解
正数:原码、反码、补码三码合一。
负数:原码、反码、补码不相同。了解三者之间的关系。
计算机的底层是以补码的方式存储数据的。
熟悉:二进制与十进制之间的转换
了解:二进制与八进制、十六进制间的转换
运算符 算术运算符
+ - + - * / % (前)++ (后)++ (前)-- (后)-- +
赋值运算符 = +=、 -=、*=、 /=、%=
比较运算符 == != > < >= <= instanceof
逻辑运算符
& && | || ! ^
说明:
区分:& 和 &&
2、执行过程:
位运算符(了解)
<< >> >>> & | ^ ~
说明:
① << >> >>> & | ^ ~ :针对数值类型的变量或常量进行运算,运算的结果也是数值
面试题:高效的方式计算2 * 8 ? (2 << 3 或 8 << 1)
条件运算符
(条件表达式)? 表达式1 : 表达式2
说明:
④ 开发中,凡是可以使用条件运算符的位置,都可以改写为if-else。
建议,在二者都能使用的情况下,推荐使用条件运算符。因为执行效率稍高。
企业真题(二) 1. 高效的方式计算2 * 8的值 (文**辉、轮*科技) 使用 <<
2. &和&&的区别?(恒*电子、*度) 1、相同点:两个符号表达的都是”且”的关系。只有当符号左右两边的类型值均为true时,结果才为true。
3. Java中的基本类型有哪些?String 是最基本的数据类型吗?(恒*电子) 8种基本数据类型。(略)
String不是,属于引用数据类型。
4. Java中的基本数据类型包括哪些?(*米) 1 2 类似问题: > Java的基础数据类型有哪些?String是吗?(贝壳)
略
5. Java开发中计算金额时使用什么数据类型?(5*到家) 不能使用float或double,因为精度不高。
使用BigDecimal类替换,可以实现任意精度的数据的运算。
6. char型变量中能不能存储一个中文汉字,为什么?(*通快递) 可以的。char c1 = ‘中’;
char c2 = ‘a’。
因为char使用的是unicode字符集,包含了世界范围的所有的字符。
7. 代码分析(君*科技、新*陆) 8. int i=0; i=i++执行这两句化后变量 i 的值为(*软) 0。
9. 如何将两个变量的值互换(北京*彩、中外*译咨询) 1 2 3 4 5 6 String s1 = "abc" ;String s2 = "123" ;String temp = s1;s1 = s2; s2 = temp;
10. boolean 占几个字节(阿**巴) 1 2 3 4 5 6 7 编译时不谈占几个字节。 但是JVM在给boolean类型分配内存空间时,boolean类型的变量占据一个槽位(slot,等于4个字节)。 细节:true:1 false:0 >拓展:在内存中,byte\short\char\boolean\int\float : 占用1个slot double\long :占用2个slot
11. 为什么Java中0.1 + 0.2结果不是0.3?(字*跳动) 在代码中测试0.1 + 0.2,你会惊讶的发现,结果不是0.3,而是0.3000……4。这是为什么?
几乎所有现代的编程语言都会遇到上述问题,包括 JavaScript、Ruby、Python、Swift 和 Go 等。引发这个问题的原因是,它们都采用了IEEE 754标准。
IEEE是指“电气与电子工程师协会”,其在1985年发布了一个IEEE 754计算标准,根据这个标准,小数的二进制表达能够有最大的精度上限提升。但无论如何,物理边界是突破不了的,它仍然不能实现“每一个十进制小数,都对应一个二进制小数”。正因如此,产生了0.1 + 0.2不等于0.3的问题。
具体的:
整数变为二进制,能够做到“每个十进制整数都有对应的二进制数” ,比如数字3,二进制就是11;再比如,数字43就是二进制101011,这个毫无争议。
对于小数,并不能做到“每个小数都有对应的二进制数字” 。举例来说,二进制小数0.0001表示十进制数0.0625 (至于它是如何计算的,不用深究);二进制小数0.0010表示十进制数0.125;二进制小数0.0011表示十进制数0.1875。看,对于四位的二进制小数,二进制小数虽然是连贯的,但是十进制小数却不是连贯的。比如,你无法用四位二进制小数的形式表示0.125 ~ 0.1875之间的十进制小数。
所以在编程中,遇见小数判断相等情况,比如开发银行、交易等系统,可以采用四舍五入或者“同乘同除”等方式进行验证,避免上述问题。
分支结构 if-else 1 2 3 4 5 if (条件表达式) { 语句块1 ; }else { 语句块2 ; }
switch-case
1 2 3 4 5 6 7 8 9 10 11 12 13 switch (表达式){ case 常量1 : case 常量2 : ... default : }
循环结构 for
凡是循环结构,都有4个要素:①初始化条件 ②循环条件(是boolean类型) ③ 循环体 ④ 迭代条件
应用场景:有明确的遍历的次数。 for(int i = 1;i <= 100;i++)
while
do-while
break和continue
break在开发中常用;而continue较少使用
笔试题:break和continue的区别。
Math类的random()
random()调用以后,会返回一个[0.0,1.0)范围的double型的随机数
需求:获取一个[a,b]范围的随机整数?
企业真题(三) 1. break和continue的作用(智*图) 略
2. if分支语句和switch分支语句的异同之处(智*图)
if-else语句优势
if语句的条件是一个布尔类型值,if条件表达式为true则进入分支,可以用于范围的判断,也可以用于等值的判断,使用范围更广。
switch语句的条件是一个常量值(byte,short,int,char,枚举,String),只能判断某个变量或表达式的结果是否等于某个常量值,使用场景较狭窄。
switch语句优势
当条件是判断某个变量或表达式是否等于某个固定的常量值时,使用if和switch都可以,习惯上使用switch更多。因为效率稍高。当条件是区间范围的判断时,只能使用if语句。
使用switch可以利用穿透性,同时执行多个分支,而if…else没有穿透性。
3. 什么时候用语句if,什么时候选用语句switch(灵伴*来科技) 同上
4. switch语句中忘写break会发生什么(北京*蓝) case穿透
5. Java支持哪些类型循环(上海*睿)
for;while;do-while
增强for (或foreach),放到集合中讲解
6. while和do while循环的区别(国*科技研究院)
IDEA的认识
IDEA(集成功能强大、符合人体工程学(设置人性化))
Eclipse
企业真题(四) 1. 开发中你接触过的开发工具都有哪些? IDEA
2. 谈谈你对Eclipse和IDEA使用上的感受? Eclipse不够人性化。
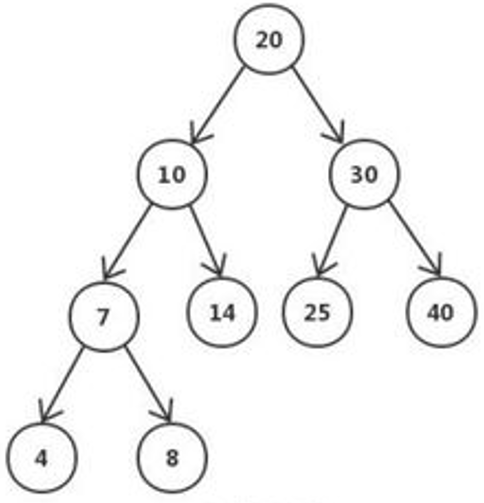
数组 数组的概述
数组,就可以理解为多个相同数据的组合。
是程序中的容器:数组、集合框架(List、Set、Map)
数组存储的数据的特点:依次紧密排列的、有序的、可以重复的
此时的数组、集合框架都是在内存中对多个数据的存储。
数组的其它特点:一旦初始化,其长度就是确定的、不可更改的。
数组名中引用的是这块连续空间的首地址。
一维数组的使用(重要) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 > 数组的声明和初始化 int[] arr = new int[10]; String[] arr1 = new String[]{"Tom","Jerry"}; 注意:Java 语言中声明数组时不能指定其长度(数组中元素的个数)。 例如:int a[5]; //非法 > 调用数组的指定元素:使用角标、索引、index >index从0开始!因为第一个元素距离数组首地址间隔 0 个单元格。 > 数组的属性:length,表示数组的长度 > 数组的遍历 > 数组元素的默认初始化值 对于基本数据类型而言,默认初始化值各有不同。 对于引用数据类型而言,默认初始化值为 null(注意与 0 不同!) > 一维数组的内存解析(难) 前提:在main()中声明变量:int[] arr = new int[]{1,2,3}; > 虚拟机栈:main()作为一个栈帧,压入栈空间中。在main()栈帧中,存储着arr变量。arr记录着数组实体的首地址值。 > 堆:数组实体存储在堆空间中。
二维数组的使用(难点)
二维数组:一维数组的元素,又是一个一维数组,则构成了二维数组。
1 2 3 4 5 6 > 数组的声明和初始化 > 调用数组的指定元素 > 数组的属性:length,表示数组的长度 > 数组的遍历 > 数组元素的默认初始化值 > 二维数组的内存解析(难)
数组的常用算法(重要)
数值型数组的特征值的计算:最大值、最小值、总和、平均值等
数组元素的赋值。比如:杨辉三角;彩票随机生成数(6位;1-30;不能重复);回形数
数组的复制、赋值
数组的反转
数组的扩容、缩容
数组的查找
数组的排序
Arrays工具类的使用
熟悉一下内部的常用的方法
toString() / sort() / binarySearch()
数组中的常见异常
ArrayIndexOutOfBoundsException
NullPointerException
企业真题(五) 1. 数组有没有length()这个方法? String有没有length()这个方法?(*蓝) 数组没有length(),是length属性。
String有length()
2. 有数组int[] arr,用Java代码将数组元素顺序颠倒(闪*购) 略
3. 为什么数组要从0开始编号,而不是1(中*支付) 数组的索引,表示了数组元素距离首地址的偏离量。因为第1个元素的地址与首地址相同,所以偏移量就是0。所以从0开始。
4. 数组有什么排序的方式,手写一下(平*保险) 冒泡。
快排。(讲完递归方法以后,大家就可以练习一下)
5. 常见排序算法,说下快排过程,时间复杂度?(5*到家) 见课件。
快排:O(nlogn)
6. 二分算法实现数组的查找(神舟*天软件) 略
7. 怎么求数组的最大子序列和(携*) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class ArrDemo { public static void main (String[] args) { int [] arr = new int []{1 , -2 , 3 , 10 , -4 , 7 , 2 , -5 }; int i = getGreatestSum(arr); System.out.println(i); } public static int getGreatestSum (int [] arr) { int greatestSum = 0 ; if (arr == null || arr.length == 0 ){ return 0 ; } int temp = greatestSum; for (int i = 0 ;i < arr.length;i++){ temp += arr[i]; if (temp < 0 ){ temp = 0 ; } if (temp > greatestSum){ greatestSum = temp; } } if (greatestSum == 0 ){ greatestSum = arr[0 ]; for (int i = 1 ;i < arr.length;i++){ if (greatestSum < arr[i]){ greatestSum = arr[i]; } } } return greatestSum; } }
8. Arrays 类的排序方法是什么?如何实现排序的?(阿*、阿*校招) 略
面向对象-基础 面向过程 vs 面向对象(了解)
不管是面向过程、面向对象,都是程序设计的思路。
面向过程:以函数为基本单位,适合解决简单问题。比如:开车
面向对象:以类为基本单位,适合解决复杂问题。比如:造车
类、对象
类:抽象的,概念上的定义
对象:具体的,类的一个一个的实例。
面向对象完成具体功能的操作的三步流程(非常重要)
1 2 3 步骤1:创建类,并设计类的内部成员(属性、方法) 步骤2:创建类的对象。比如:Phone p1 = new Phone(); 步骤3:通过对象,调用其内部声明的属性或方法,完成相关的功能
对象的内存解析
创建类的一个对象;创建类的多个对象;方法的调用的内存解析
Java中内存结构的划分
Java中内存结构划分为:虚拟机栈、堆、方法区;程序计数器、本地方法栈
虚拟机栈:以栈帧为基本单位,有入栈和出栈操作;每个栈帧入栈操作对应一个方法的执行;方法内的局部变量会存储在栈帧中。
堆空间:new 出来的结构(数组、对象):① 数组,数组的元素在堆中 ② 对象的成员变量在堆中。
方法区:加载的类的模板结构。
类的成员之一:属性(或成员变量)
成员变量 vs 局部变量
变量声明的格式相同: 数据类型 变量名 = 初始化值
变量必须先声明、后初始化、再使用。
变量都有其对应的作用域。只在其作用域内是有效的
声明位置和方式 (1)实例变量:在类中方法外 (2)局部变量:在方法体
在内存中存储的位置不同 (1)实例变量:堆 (2)局部变量:栈
生命周期 (1)实例变量:和对象的生命周期一样,随着对象的创建而存
作用域 (1)实例变量:通过对象就可以使用,本类中直接调用,其他类中
修饰符(后面来讲) (1)实例变量:
默认值 (1)实例变量:有默认值 (2)局部变量:没有,必须手动初始
属性 <=> 成员变量 <=>field <=> 字段、域
类的成员之二:方法
方法的声明:权限修饰符 返回值类型 方法名(形参列表){ // 方法体}
return关键字的使用
再谈方法 方法的重载(overload)
方法的重载的要求:“两同一不同” 同类同名参数不同
调用方法时,如何确定调用的是某个指定的方法呢?① 方法名 ② 形参列表
可变个数形参的方法 JDK 5.0 中提供了 Varargs(variable number of arguments)机制
方法的参数传递机制:值传递(重点、难点) 1 2 > 如果形参是基本数据类型的变量,则将实参保存的数据值赋给形参。 > 如果形参是引用数据类型的变量,则将实参保存的地址值赋给形参。
递归方法
递归方法构成了隐式的循环
对比:相较于循环结构,递归方法效率稍低,内存占用偏高。
递归调用会占用大量的系统堆栈,内存耗用多,在递归调用层次多时速度要比循环慢的多,所以在使用递归时要慎重。
在要求高性能的情况下尽量避免使用递归,递归调用既花时间又耗内存。考虑使用循环迭代
对象数组
String[] ;Person[] ; Customer[]
package、import关键字的使用
package:指明声明的类所属的包。
import:当前类中,如果使用其它包下的类(除java.lang包),原则上就需要导入。
java.lang—-包含一些 Java 语言的核心类,如 String、Math、Integer、System 和 Thread,提供常用功能
java.net—-包含执行与网络相关的操作的
java.io —-包含能提供多种输入/输出功能的类。
java.util—-包含一些实用工具类,如定义系统特性、接口的集合框架类、使用与日期日历相关的函数。
java.text—-包含了一些 java 格式化相关的类
java.sql—-包含了 java 进行 JDBC 数据库编程的相关类/接口
java.awt—-包含了构成抽象窗口工具集(abstract window toolkits)的多个类,这些类被用来构建和管理应用程序的图形用户界面(GUI)
oop的特征之一:封装性 1 2 Java规定了4种权限修饰,分别是:private、缺省、protected、public。 我们可以使用4种权限修饰来修饰类及类的内部成员。当这些成员被调用时,体现可见性的大小。
举例:
1 2 3 > 场景1:私有化(private)类的属性,提供公共(public)的get和set方法,对此属性进行获取或修改 > 场景2:将类中不需要对外暴露的方法,设置为private > 场景3:单例模式中构造器private的了,避免在类的外部创建实例。(放到static关键字后讲)
上理论:程序设计的原则之一
1 2 3 4 5 理论上: -`高内聚`:类的内部数据操作细节自己完成,不允许外部干涉; (Java程序通常以类的形态呈现,相关的功能封装到方法中。) -`低耦合`:仅暴露少量的方法给外部使用,尽量方便外部调用。 (给相关的类、方法设置权限,把该隐藏的隐藏起来,该暴露的暴露出去)
注意:
类的成员之三:构造器
如何定义:权限修饰符 类名(形参列表){}
构造器的作用:① 搭配上new,用来创建对象 ② 初始化对象的成员变量
三个小知识 类的实例变量的赋值过程(重要)
在类的属性中,可以有哪些位置给属性赋值?
④ 通过”对象.方法”的方式赋值;
这些位置执行的先后顺序是怎样?
JavaBean 所谓JavaBean,是指符合如下标准的Java类:
类是公共的
有一个无参的公共的构造器
有属性,且有对应的get、set方法
UML类图 熟悉。
企业真题(六) 2.1 类与对象 1. 面向对象,面向过程的理解?(平*金服、英**达) 略。
2. Java 的引用类型有哪几种(阿*校招) 类、数组、接口;枚举、注解、记录
3. 类和对象的区别(凡*科技、上*银行) 略。
4. 面向对象,你解释一下,项目中哪些地方用到面向对象?(燕*金融) “万事万物皆对象”。
2.2 Java内存结构 1. Java虚拟机中内存划分为哪些区域,详细介绍一下(神**岳、数*互融) 略。
2. 对象存在Java内存的哪块区域里面?(阿*) 堆空间。
2.3 权限修饰符(封装性) 1. private 、缺省、protected、public的表格化作用区域(爱*信、拓*思、中*瑞飞) 略
2. main方法的public能不能换成private?为什么?(凡*科技、顺*) 能。但是改以后就不能作为程序的入口了,就只是一个普通的方法。
2.4 构造器 1. 构造方法和普通方法的区别(凡*科技、软*动力、中*软) 编写代码的角度:没有共同点。声明格式、作用都不同。
字节码文件的角度:构造器会以<init>()方法的形态呈现,用以初始化对象。
2. 构造器Constructor是否可被overload?(鸿*网络) 可以。
3. 无参构造器和有参构造器的的作用和应用(北京楚*龙) 略
2.5 属性及属性赋值顺序 1. 成员变量与局部变量的区别(艾*软件) 6个点。
2. 变量赋值和构造方法加载的优先级问题(凡*科技、博*软件) 变量显式赋值先于构造器中的赋值。
如何证明?我看的字节码文件。
面向对象-进阶 this关键字的使用
this调用的结构:属性、方法;构造器
this调用属性或方法时,理解为:当前对象或当前正在创建的对象。
1 2 3 4 5 6 7 8 public void setName (String name) { this .name = name; } public Person (String name) { this (); this .name = name; }
this():调用本类的无参构造器。
this(形参列表)的方式,表示调用当前类中其他的重载的构造器。
面向对象的特征二:继承性
继承性的好处
继承的出现减少了代码冗余,提高了代码的复用性。
继承的出现,更有利于功能的扩展。
继承的出现让类与类之间产生了 is-a 的关系,为多态的使用提供了前提。继承描述事物之间的所属关系,这种关系是:is-a 的关系。可见,父类更通用、更一般,子类更具体。
注意:不要仅为了获取其他类中某个功能而去继承
Java中继承性的特点
局限性:类的单继承性。后续我们通过类实现接口的方式,解决单继承的局限性。
支持多层继承,一个父类可以声明多个子类。
基础:class A extends B{}
理解:子类就获取了父类中声明的全部的属性、方法。可能受封装性的影响,不能直接调用。
方法的重写(override / overwrite) @Override 使用说明:
子类重写的方法必须和父类被重写的方法具有相同的方法名称、参数列表。
子类重写的方法的返回值类型不能大于父类被重写的方法的返回值类型。(例如:
子类重写的方法使用的访问权限不能小于父类被重写的方法的访问权限。(public > protected > 缺省 > private)注意:① 父类私有方法不能重写 ② 跨包的父类缺省的方法也不能重写
子类方法抛出的异常不能大于父类被重写方法的异常
此外,子类与父类中同名同参数的方法必须同时声明为非 static 的(即为重写),
面试题:方法的重载与重写的区别?
方法的重载:“两同一不同”
方法的重写:
前提:类的继承关系
子类对父类中同名同参数方法的覆盖、覆写。
super关键字的使用
super可以调用的结构:属性、方法;构造器
super:父类的
super调用父类的属性、方法:
如果子父类中出现了同名的属性,此时使用super.的方式,表明调用的是父类中声明的属性。
子类重写了父类的方法。如果子类的任何一个方法中需要调用父类被重写的方法时,需要使用super.
super调用构造器:
子类继承父类时,不会继承父类的构造器。只能通过“super(形参列表)”的方
在子类的构造器中,首行要么使用了”this(形参列表)”,要么使用了”super(形参列表)”。
如果在子类构造器的首行既没有显示调用”this(形参列表)”,也没有显式调用
一个类中声明有 n 个构造器,最多有 n-1 个构造器中使用了”this(形参列表)”,则剩下的那个一定使用”super(形参列表)”
(熟悉)子类对象实例化的全过程
结果上来说:体现为继承性
过程上来说:子类调用构造器创建对象时,一定会直接或间接的调用其父类的构造器,以及父类的父类的构造器,…,直到调用到Object()的构造器。
面向对象的特征三:多态性
广义上的理解:子类对象的多态性、方法的重写;方法的重载
狭义上的理解:子类对象的多态性。
格式:Object obj = new String(“hello”); Person p = new Man();
多态的好处:减少了大量的重载的方法的定义;开闭原则
举例:public boolean equals(Object obj)
多态,无处不在!讲了抽象类、接口以后,会有更好的理解。
弊端:一个引用类型变量如果声明为父类的类型,但实际引用的是子类对象,那么该变量就不能再访问子类中添加的属性和方法。
多态的使用:虚拟方法调用。“编译看左边,运行看右边”。属性不存在多态性。
多态的逆过程:向下转型,使用强转符()。
为了避免出现强转时的ClassCastException,建议()之前使用instanceOf进行判断。
向下转型:(子类类型)父类变量
Person p2 = new Man(); Man m1 = (Man)p2
建议在向下转型之前,使用instanceof进行判断,避免出现类型转换异常
格式:a instanceof A :判断对象a是否是类A的实例
Object类的使用
根父类,默认的父类,java.lang.Object
equals()
只能比较引用类型,Object 类源码中 equals()的作用与“==”相同:比较是否指向同一个对象。对类 File、String、Date 及包装类(Wrapper Class)来说,是比较类型及内容而不考虑引用的是否是同一个对象;在这些类中重写了 Object 类的 equals()方法。
重写和不重写的区别
面试题: == 和 equals() 1 2 3 4 1. == 既可以比较基本类型也可以比较引用类型。对于基本类型就是比较值,对于引用类型就是比较内存地址 2. equals 的话,它是属于 java.lang.Object 类里面的方法,如果该方法没有被重写过默认也是==;我们可以看到 String 等类的 equals 方法是被重写过的,而且 String 类在日常开发中用的比较多,久而久之,形成了 equals 是比较值的错误观点。 3. 具体要看自定义类里有没有重写 Object 的 equals 方法来判断。 通常情况下,重写 equals 方法,会比较类中的相应属性是否都相等。
toString()的使用
Object中toString()调用后,返回当前对象所属的类和地址值。
开发中常常重写toString(),用于返回当前对象的属性信息。
clone() 深拷贝
finalize() 当GC要回收此对象时,调用该方法(从JDK9开始过时),可能导致内部出现循环引用,导致此对象不能被回收
getClass() \ hashCode() \ notify() \ notifyAll() \ wait()
企业真题(七) 2.1 继承性 1. 父类哪些成员可以被继承,属性可以被继承吗?可以或者不可以,请举下例子。(北京明**信) 父类的属性、方法可以被继承。构造器可以被子类调用。
2.2 重写 1. 什么是Override,与Overload的区别(顺*、软**力、明*数据、阳*科技、中*软) 略
2. Overload的方法是否可以改变返回值的类型?(新*陆) 和返回值类型无关。
public void method(int i){}
public int method(int j,int k){}
3. 构造器Constructor是否可被override?(鸿*网络、深圳德**技、航**普) 不能!构造器可以重载
4. 为什么要有重载,我随便命名一个别的函数名不行吗?谈谈你是怎么理解的。(腾*) 见名知意。
2.3 super关键字 1. super和this的区别(蚂**服) 把两个关键字各自的特点说清楚。
2. this、super关键字分别代表什么?以及他们各自的使用场景和作用。(北京楚*龙) 略
2.4 多态 1. 谈谈你对多态的理解(三*重工、江*智能、银*数据、君*科技) 1 2 3 4 类似问法: > Java中实现多态的机制是什么(国*电网) > 什么是多态?(上*银行) > Java中的多态是什么意思?(贝*)
理解、格式、好处、弊端。
2. 多态new出来的对象跟不多态new出来的对象区别在哪?(万*智能) Person p = new Man(); //虚方法调用。屏蔽了子类Man类特有的属性和方法。
Man m = new Man();
3. 说说你认为多态在代码中的体现(楚*龙) 无处不在!
略
2.5 Object类 1. ==与equals的区别(拓*思) 1 2 类似问法: > 两个对象A和B,A==B,A.equals(B)有什么区别(华油**普)
略
2. 重写equals方法要注意什么?(安**网络科技)
明确判定两个对象实体equals()的标准。是否需要所有的属性参与。
对象的属性,又是自定义的类型,此属性也需要重写equals()
3. Java中所有类的父类是什么?他都有什么方法?(阿*校招) 1 2 相关问题: > Object类有哪些方法?(恒*电子)
面向对象-高级 关键字:static
单例模式(或单子模式)
经典的设计模式有23种
解决的问题:在整个软件系统中,只存在当前类的唯一实例。
实现方式:饿汉式、懒汉式、枚举类等
对比饿汉式和懒汉式
饿汉式:“立即加载”,线程安全的。
懒汉式:”延迟加载”,线程不安全。
需要会手写饿汉式和懒汉式
饿汉式: 1 2 3 4 5 6 7 8 9 10 11 12 class Singleton { private Singleton () { } private static Singleton single = new Singleton (); public static Singleton getInstance () { return single; } }
懒汉式: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 class Singleton { private Singleton () { } private static Singleton single; public static Singleton getInstance () { if (single == null ) { single = new Singleton (); } return single; } }
优点和应用场景
理解main()方法 由于 JVM 需要调用类的 main()方法,所以该方法的访问权限必须是 public,又
public static void main(String[] args){}
理解1:作为程序的入口;普通的静态方法
理解2:如何使用main()与控制台进行数据的交互。
命令行:java 类名 “Tom” “Jerry” “123”
类的成员之四:代码块 1 2 3 4 5 [修饰符] class 类{ static {静态代码块 } }
分类:静态代码块、非静态代码块
使用频率上来讲:用的比较少。
静态代码块:
可以有输出语句。
可以对类的属性、类的声明进行初始化操作。
不可以对非静态的属性初始化。即:不可以调用非静态的属性和方法。
若有多个静态的代码块,那么按照从上到下的顺序依次执行。
静态代码块的执行要先于非静态代码块。
静态代码块随着类的加载而加载,且只执行一次。 1 2 3 4 5 6 7 8 9 private static String country;private String name;{ System.out.println("非静态代码块,country = " + country); } static {country = "中国" ; System.out.println("静态代码块" ); }
非静态代码块:随着对象的创建而执行
总结:对象的实例变量可以赋值的位置及先后顺序
① 默认初始化
④ 有了对象以后,通过”对象.属性”或”对象.方法”的方法进行赋值
执行的先后顺序:
关键字:final
用来修饰:类、方法、变量(成员变量、局部变量)
类:不能被继承,没有子类。提高安全性,提高程序的可读性。
方法:不能被子类重写。
变量:是一个“常量”,一旦赋值不能修改。即常量,常量名建议使用大写字母。如果某个成员变量用 final 修饰后,没有 set 方法,并且必须初始化(可以显式赋值、或在初始化块赋值、实例变量还可以在构造器中赋值)
关键字:abstract
抽象的
用来修饰:类、方法
类:抽象类:不能实例化。
方法:抽象方法:没有方法体,必须由子类实现此方法。
使用说明:
抽象类不能创建对象,如果创建,编译无法通过而报错。只能创建其非抽象子类的对
抽象类是用来被继承的,抽象类的子类必须重写父类的抽象方法,并提供方法
抽象类中,也有构造方法,是供子类创建对象时,初始化父类成员变量使用的。
抽象类中,不一定包含抽象方法,但是有抽象方法的类必定是抽象类。
抽象类的子类,必须重写抽象父类中所有的抽象方法,否则,编译无法通过而报错。
注意事项:
不能用 abstract 修饰变量、代码块、构造器;
不能用 abstract 修饰私有方法、静态方法、final 的方法、final 的类。
关键字:interface
interface:接口,用来定义一组规范、一种标准。
1 2 3 4 5 6 7 8 9 [修饰符] interface 接口名{ }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public interface USB3 { long MAX_SPEED = 500 *1024 *1024 ; void in () ; void out () ; default void start () { System.out.println("开始" ); } default void stop () { System.out.println("结束" ); } static void show () { System.out.println("USB 3.0 可以同步全速地进行读写操作" ); } }
掌握:接口中可以声明的结构。
属性:使用public static final修饰
方法:jdk8之前:只能声明抽象方法,使用public abstract修饰
jdk8中:声明static方法、default方法。
jdk9中:声明private方法。
类实现接口(implements):接口不能创建对象,但是可以被类实现(implements ,类似于被继承)。类与接口的关系为实现关系,即类实现接口,该类可以称为接口的实现类。实现的动作类似继承,格式相仿,只是关键字不同,实现使用 implements 关键字。
接口的多实现(implements):在继承体系中,一个类只能继承一个父类。而对于接口而言,一个类是可以实现多个接口的,这叫做接口的多实现。并且,一个类能继承一个父类,同时实现多个接口。
接口的多继承(extends):一个接口能继承另一个或者多个接口。
JDK8 中相关冲突问题:
默认方法冲突问题:
常量冲突问题:
类的成员之五:内部类 1 2 3 4 > 成员内部类的理解 > 如何创建成员内部类的实例 > 如何在成员内部类中调用外部类的结构 > 局部内部类的基本使用(关注:如何在方法内创建匿名局部内部类的对象)
枚举类:enum
枚举类的实现:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 class Season {private final String SEASONNAME;private final String SEASONDESC;private Season (String seasonName,String seasonDesc) {this .SEASONNAME = seasonName;this .SEASONDESC = seasonDesc;} public static final Season SPRING = new Season ("春天" , "春暖花开" );public static final Season SUMMER = new Season ("夏天" , "夏日炎炎" );public static final Season AUTUMN = new Season ("秋天" , "秋高气爽" );public static final Season WINTER = new Season ("冬天" , "白雪皑皑" );@Override public String toString () {return "Season{" +"SEASONNAME='" + SEASONNAME + '\'' +", SEASONDESC='" + SEASONDESC + '\'' +'}' ;} }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 public enum SeasonEnum {SPRING("春天" ,"春风又绿江南岸" ), SUMMER("夏天" ,"映日荷花别样红" ), AUTUMN("秋天" ,"秋水共长天一色" ), WINTER("冬天" ,"窗含西岭千秋雪" ); private final String seasonName;private final String seasonDesc;private SeasonEnum (String seasonName, String seasonDesc) {this .seasonName = seasonName;this .seasonDesc = seasonDesc;} public String getSeasonName () {return seasonName;} public String getSeasonDesc () {return seasonDesc;} }
enum 中常用方法:
static 枚举类型[] values():返回枚举类型的对象数组。该方法可以很方便地遍历所有的枚举值,是一个静态方法
static 枚举类型 valueOf(String name):可以把一个字符串转为对应的枚举类对象。要求字符串必须是枚举类对象的“名字”。如不是,会有运行时异常:IllegalArgumentException。
String name():得到当前枚举常量的名称。建议优先使用 toString()。
int ordinal():返回当前枚举常量的次序号,默认从 0 开始
实现接口的枚举类 1 2 3 4 5 6 7 8 9 enum A implements 接口 1 ,接口 2 {常量名 1 (参数){ }, 常量名 2 (参数){ }, }
掌握:使用enum关键字定义枚举类即可。
注解:Annotation
框架 = 注解 + 反射 + 设计模式
Java基础阶段:简单。@Override(限定重写父类方法,该注解只能用于方法) 、 @Deprecated(用于表示所修饰的元素(类,方法等)已过时)、@SuppressWarnings(抑制编译器警告)
元注解:对现有的注解进行解释说明。
@Target:表明可以用来修饰的结构
@Retation:表明生命周期
如何自定义注解。 1 2 3 4 [元注解] [修饰符] @interface 注解名{ [成员列表] }
JUnit 单元测试
包装类的使用
掌握:基本数据类型对应的包装类都有哪些?
掌握:基本数据类型、包装类、String三者之间的转换
基本数据类型 <-> 包装类:自动装箱、自动拆箱(从 JDK5.0 开始)
基本数据类型、包装类 <-> String
String的valueOf(xxx)
包装类的parseXxx(String str)
包装类的其它 API
数据类型的最大最小值:Integer.MAX_VALUE 和 Integer.MIN_VALUE; Long.MAX_VALUE 和 Long.MIN_VALUE; Double.MAX_VALUE 和 Double.MIN_VALUE
字符转大小写:Character.toUpperCase(‘x’); Character.toLowerCase(‘X’);
整数转进制:Integer.toBinaryString(int i); Integer.toHexString(int i); Integer.toOctalString(int i)
比较的方法:Double.compare(double d1, double d2);Integer.compare(int x, int y)
面试题: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public void method1 () { Integer i = new Integer (1 ); Integer j = new Integer (1 ); System.out.println(i == j); Integer m = 1 ; Integer n = 1 ; System.out.println(m == n); Integer x = 128 ; Integer y = 128 ; System.out.println(x == y); } Object o1 = true ? new Integer (1 ) : new Double (2.0 );System.out.println(o1);
企业真题(八) 2.1 static关键字 1. 静态变量和实例变量的区别?(保*丰、*软国际、*软华*、北京明**信) 1 2 类似问题: > 说明静态变量和实例变量之间的区别和使用场景(上海*动)
略
2. 静态属性和静态方法是否可以被继承?是否可以被重写?以及原因?(*度) 1 2 类似问题: > 在java中,可以重载一个static方法吗?可以覆盖一个static方法吗?(Vi*o)
静态方法不能被重写。不存在多态性。
3. 是否可以从一个static方法内部发出对非static方法的调用?(同*顺) 只能通过对象来对非静态方法的调用。
4. 被static修饰的成员(类、方法、成员变量)能否再使用private进行修饰?(联*优势) 完全可以。除了代码块。
2.2 设计模式 1. 知道哪些设计模式?(*通快递、蚂**服) 单例模式、模板方法、享元设计模式
2. 开发中都用到了那些设计模式?用在什么场合? (久*国际物流) 略
2.3 main() 1. main()方法的public能不能换成private,为什么(凡*科技、顺*) 可以改。但是改完以后就不是程序入口了。
2. main()方法中是否可以调用非静态方法?(浩*科技) 只能通过对象来对非静态方法的调用。
2.4 代码块 1. 类的组成和属性赋值执行顺序?(航*拓普) 1 2 类似问题: > Java中类的变量初始化的顺序?(*壳)
略。
2. 静态代码块,普通代码块,构造方法,从类加载开始的执行顺序?(恒*电子) 1 2 3 4 类似问题: > 类加载成员变量、静态代码块、构造器的加载顺序(*科软、软**力、同*顺) > static代码块(静态代码块)是否在类的构造函数之前被执行(联*优势)
静态代码块 –> 普通代码块 –> 构造器
2.5 final关键字 1. 描述一下对final理解(华**博普) 略
2. 判断题:使用final修饰一个变量时,是引用不能改变,引用指向的对象可以改变?(*米) 引用不能改变。
引用指向的对象实体中的属性,如果没有使用final修饰,则可以改变。
3. 判断题:final不能用于修饰构造方法?(联*优势) 是的。
4. final或static final 修饰成员变量,能不能进行++操作?(佳*贸易) 不能。
2.6 抽象类与接口 1. 什么是抽象类?如何识别一个抽象类?(易*支付) 使用abstract修饰。
2. 为什么不能用abstract修饰属性、私有方法、构造器、静态方法、final的方法?(止**善) 略。 为了语言的自洽。
3. 接口与抽象类的区别?(字*跳动、阿*校招、*度校招、**计算机技术及应用研究所、航*拓普、纬*、招**晟、汇*云通、数信**科技、北京永*鼎力、上海*连科技) 略。
4. 接口是否可继承接口?抽象类是否可实现(implements)接口?抽象类是否可继承实现类(concrete class)?(航*拓普、*蝶、深圳德*科技) 1 2 类似问题: > 接口A可以继承接口B吗?接口A可以实现接口B吗?(久*国际物流)
是;是;是;
5. 接口可以有自己属性吗?(华*中盛) 可以。必须是public static final的
6. 访问接口的默认方法如何使用(上海*思) 使用实现类的对象进行调用。而且实现还可以重写此默认方法。
2.7 内部类 1. 内部类有哪几种?(华油**普、来*科技) 略。
2. 内部类的特点说一下(招通**) 1 2 3 类似问题: > 说一下内部类的好处(北京楚*龙) > 使用过内部类编程吗,有什么作用(软**力)
8.匿名类说一下(阿*校招、上海立*网络) 略
2.8 枚举类 1. 枚举可以继承吗?(顺*) 使用enum定义的,其父类就是Enum类,就不要再继承其他的类了。
2.9 包装类 1. Java基本类型与包装类的区别(凡*科技) 略。
2.10 综合 1. 谈谈你对面向对象的理解(君*科技、航*拓普、…)
面向对象的两个要素:类、对象 —> 面向对象编程。“万事万物皆对象”。
面向对象的三大特征
接口,与类并列的结构,作为一个补充:类可以实现多个接口。
2. 面向对象的特征有哪些方面? (北京楚*龙、深圳德*科技、直*科技、米*奇网络、航*拓普) 1 2 类似问题: > 面向对象核心是什么?(平**服)
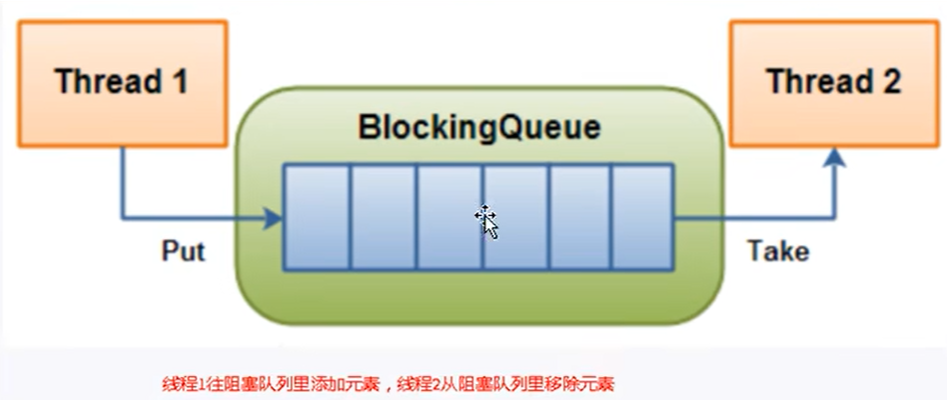
异常处理 异常的概述 1 2 3 4 5 6 7 8 9 10 11 12 1. 什么是异常? 指的是程序在执行过程中,出现的非正常情况,如果不处理最终会导致JVM的非正常停止。 2. 异常的抛出机制 Java中把不同的异常用不同的类表示,一旦发生某种异常,就`创建该异常类型的对象`,并且抛出(throw)。 然后程序员可以捕获(catch)到这个异常对象,并处理;如果没有捕获(catch)这个异常对象,那么这个异常 对象将会导致程序终止。 3. 如何对待异常 对于程序出现的异常,一般有两种解决方法:一是遇到错误就终止程序的运行。另一种方法是程序员在编写程序时, 就充分考虑到各种可能发生的异常和错误,极力预防和避免。实在无法避免的,要编写相应的代码进行异常的检测、 以及`异常的处理`,保证代码的`健壮性`。
异常的体系结构及常见的异常 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 java.lang.Throwable:异常体系的根父类 • public void printStackTrace():打印异常的详细信息。 包含了异常的类型、异常的原因、异常出现的位置、在开发和调试阶段都得使用printStackTrace。 • public String getMessage():获取发生异常的原因。 |---java.lang.Error:错误。Java虚拟机无法解决的严重问题。如:JVM系统内部错误、资源耗尽等严重情况。 一般不编写针对性的代码进行处理。 |---- StackOverflowError(栈内存溢出)和 OutOfMemoryError(堆内存溢出,简称OOM) |---java.lang.Exception:异常。我们可以编写针对性的代码进行处理。 |----编译时异常:(受检异常)在执行javac.exe命令时,出现的异常。 |----- ClassNotFoundException |----- FileNotFoundException |----- IOException |----运行时异常:(非受检异常)在执行java.exe命令时,出现的异常。 |---- ArrayIndexOutOfBoundsException |---- NullPointerException |---- ClassCastException |---- NumberFormatException |---- InputMismatchException |---- ArithmeticException
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 【面试题】说说你在开发中常见的异常都有哪些? 开发1-2年: |----编译时异常:(受检异常)在执行javac.exe命令时,出现的异常。 |----- ClassNotFoundException |----- FileNotFoundException |----- IOException |----运行时异常:(非受检异常)在执行java.exe命令时,出现的异常。 |---- ArrayIndexOutOfBoundsException |---- NullPointerException |---- ClassCastException |---- NumberFormatException |---- InputMismatchException |---- ArithmeticException 开发3年以上: OOM。
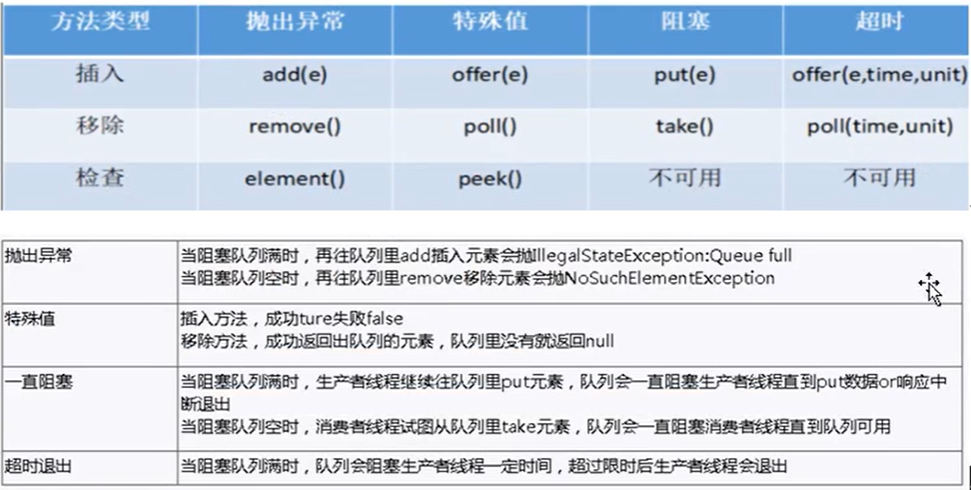
异常处理的方式 1 2 3 4 5 6 7 8 9 过程1:“抛” >"自动抛" : 程序在执行的过程当中,一旦出现异常,就会在出现异常的代码处,自动生成对应异常类的对象,并将此对象抛出。 >"手动抛" :程序在执行的过程当中,不满足指定条件的情况下,我们主动的使用"throw + 异常类的对象"方式抛出异常对象。 过程2:“抓” 狭义上讲:try-catch的方式捕获异常,并处理。 广义上讲:把“抓”理解为“处理”。则此时对应着异常处理的两种方式:① try-catch-finally ② throws
try-catch-finally 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 1. 基本结构: try{ ...... //可能产生异常的代码 } catch( 异常类型1 e ){ ...... //当产生异常类型1型异常时的处置措施 } catch( 异常类型2 e ){ ...... //当产生异常类型2型异常时的处置措施 } finally{ ...... //无论是否发生异常,都无条件执行的语句 } 2. 使用细节: > 将可能出现异常的代码声明在try语句中。一旦代码出现异常,就会自动生成一个对应异常类的对象。并将此对象抛出。 > 针对于try中抛出的异常类的对象,使用之后的catch语句进行匹配。一旦匹配上,就进入catch语句块进行处理。 一旦处理接触,代码就可继续向下执行。 > 如果声明了多个catch结构,不同的异常类型在不存在子父类关系的情况下,谁声明在上面,谁声明在下面都可以。 如果多个异常类型满足子父类的关系,则必须将子类声明在父类结构的上面。否则,报错。 > catch中异常处理的方式: ① 自己编写输出的语句。 ② printStackTrace():打印异常的详细信息。 (推荐) ③ getMessage():获取发生异常的原因。 > try中声明的变量,出了try结构之后,就不可以进行调用了。 > try-catch结构是可以嵌套使用的。
1 2 3 4 5 6 7 8 9 10 11 12 13 3. finally的使用说明: 3.1 finally的理解 > 我们将一定要被执行的代码声明在finally结构中。 > 更深刻的理解:无论try中或catch中是否存在仍未被处理的异常,无论try中或catch中是否存在return语句等,finally 中声明的语句都一定要被执行。 > finally语句和catch语句是可选的,但finally不能单独使用。 3.2 什么样的代码我们一定要声明在finally中呢? > 我们在开发中,有一些资源(比如:输入流、输出流,数据库连接、Socket连接等资源),在使用完以后,必须显式的进行 关闭操作,否则,GC不会自动的回收这些资源。进而导致内存的泄漏。 为了保证这些资源在使用完以后,不管是否出现了未被处理的异常的情况下,这些资源能被关闭。我们必须将这些操作声明 在finally中!
throws 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 1. 格式:在方法的声明处,使用"throws 异常类型1,异常类型2,..." 2. 举例: public void test() throws 异常类型1,异常类型2,.. { //可能存在编译时异常 } 3. 是否真正处理了异常? > 从编译是否能通过的角度看,看成是给出了异常万一要是出现时候的解决方案。此方案就是,继续向上抛出(throws)。 > 但是,此throws的方式,仅是将可能出现的异常抛给了此方法的调用者。此调用者仍然需要考虑如何处理相关异常。 从这个角度来看,throws的方式不算是真正意义上处理了异常。 4. 方法的重写的要求:(针对于编译时异常来说的) 子类重写的方法抛出的异常类型可以与父类被重写的方法抛出的异常类型相同,或是父类被重写的方法抛出的异常类型的子类。
开发中的经验之谈:
1 2 3 4 5 6 7 开发中,如何选择异常处理的两种方式?(重要、经验之谈) - 如果程序代码中,涉及到资源的调用(流、数据库连接、网络连接等),则必须考虑使用try-catch-finally来处理, 保证不出现内存泄漏。 - 如果父类被重写的方法没有throws异常类型,则子类重写的方法中如果出现异常,只能考虑使用try-catch-finally 进行处理,不能throws。 - 开发中,方法a中依次调用了方法b,c,d等方法,方法b,c,d之间是递进关系。此时,如果方法b,c,d中有异常, 我们通常选择使用throws,而方法a中通常选择使用try-catch-finally。
手动throw异常对象 1 在方法内部,满足指定条件的情况下,使用"throw 异常类的对象"的方式抛出。
如何自定义异常类 1 2 3 ① 继承于现有的异常体系。通常继承于RuntimeException \ Exception ② 通常提供几个重载的构造器 ③ 提供一个全局常量,声明为:static final long serialVersionUID;
1 2 3 为什么需要自定义异常类? 我们其实更关心的是,通过异常的名称就能直接判断此异常出现的原因。既然如此,我们就有必要在实际开发场景中, 不满足我们指定的条件时,指明我们自己特有的异常类。通过此异常类的名称,就能判断出具体出现的问题。
企业真题(九) 2.1 异常概述 1. Java的异常体系简单介绍下(网*) 1 2 3 包含问题: > 4.异常的顶级接口是什么(软**力) > 异常类的继承关系,exception下都有哪些类?(上海*冉信息)
略
2. Java异常处理机制(*科软) 两种处理方案:try-catch-finally ;throws
3. 异常的两种类型,Error和Exception的区别(上海冠*新创、北京中**译、*度) 略
4. 运行时异常与一般异常有何异同?(华*思为) 运行时异常:RuntimeException
编译可以通过。在运行时可能抛出。出现的概率高一些;一般针对于运行时异常,都不处理。
一般异常:Exception
编译不能通过。要求必须在编译之前,考虑异常的处理。不处理编译不通过。
5. 说几个你常见到的异常(华油**普) 1 2 3 类似问题: > 请列出Java中常见的几种异常?(百*园) > 给我一个你最常见到的runtime exception。(*蝶)
略
2.2 try-catch-finally 1. 说说final、finally、finalize的区别(北京中**译、艾*软件、拓*思、*科软) 1 2 类似问题: > 1. finally和final的区别(*科软)
略。
2. 如果不使用try-catch,程序出现异常会如何?(上海冠*新创科技) 对于当前方法来讲,如果不使用try-catch,则在出现异常对象以后会抛出此对象。如果没有处理方案,就会终止程序的执行。
3. try … catch捕捉的是什么异常?(北京亿*东方) Exception。非Error
4. 如果执行finally代码块之前方法返回了结果或者jvm退出了,这时finally块中的代码还会执行吗?(恒*电子) 特别的:System.exit(0);
5. 在try语句中有return语句,最后写finally语句,finally语句中的code会不会执行?何时执行?如果执行是在return前还是后(拓*思、华**为) 略
6. 捕获异常在catch块里一定会进入finally吗?catch里能return吗?catch里return还会进finally吗?在try里return是什么情况?(*蓝) 略
2.3 throw与throws 1. throw和throws的区别?(北京亿**方、北京新*阳光) 角度1:”形”,即使用的格式
1 2 throw:使用在方法内部,“throw 异常类的对象” throws:使用在方法的声明处,"throws 异常类1,异常类2,..."
角度2:”角色”或作用不同。
1 2 3 4 5 6 上游排污,下游治污。 过程1:“抛” >throw 过程2:“抓” > try-catch ; throws
2. 子类重写父类抛出异常的方法,能否抛出比父类更高级别的异常类(顺*) 不能!
2.4 自定义异常 1. 如何自定义一个异常?(*软国际) 略
多线程 几个概念 1 2 3 4 5 6 7 程序(program):为完成特定任务,用某种语言编写的`一组指令的集合`。即指一段静态的代码。 进程(process):程序的一次执行过程,或是正在内存中运行的应用程序。程序是静态的,进程是动态的。 进程作为操作系统调度和分配资源的最小单位。 线程(thread):进程可进一步细化为线程,是程序内部的一条执行路径。 线程作为CPU调度和执行的最小单位
1 2 3 4 线程调度策略 分时调度:所有线程`轮流使用` CPU 的使用权,并且平均分配每个线程占用 CPU 的时间。 抢占式调度:让`优先级高`的线程以`较大的概率`优先使用 CPU。如果线程的优先级相同,那么会随机选择一个(线程随机性),Java使用的为抢占式调度。
1 2 3 4 5 6 7 > 单核CPU与多核CPU • 单核 CPU,在一个时间单元内,只能执行一个线程的任务。 > 并行与并发 • 并行(parallel):指两个或多个事件在同一时刻发生(同时发生)。指在同一时刻,有多条指令在多个 CPU 上同时执行。比如:多个人同时做不同的事。 • 并发(concurrency):指两个或多个事件在同一个时间段内发生。即在一段时间 内,有多条指令在单个 CPU 上快速轮换、交替执行,使得在宏观上具有多个进程同时执行的效果。
2. 如何创建多线程(重点) Java 语言的 JVM 允许程序运行多个线程,使用 java.lang.Thread 类代表线程,所有的线程对象都必须是 Thread 类或其子类的实例。
方式1:继承Thread类
每个线程都是通过某个特定 Thread 对象的 run()方法来完成操作的,因此
通过该 Thread 对象的 start()方法来启动这个线程,而非直接调用 run()
要想实现多线程,必须在主线程中创建新的线程对象。
方式2:实现Runnable接口
Java 有单继承的限制,当我们无法继承 Thread 类时,那么该如何做呢?在核心1 2 3 4 5 6 MyRunnable mr = new MyRunnable ();Thread t = new Thread (mr, "长江" );
使用匿名内部类对象来实现线程的创建和启动 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 new Thread ("新的线程!" ){ @Override public void run () { for (int i = 0 ; i < 10 ; i++) { System.out.println(getName()+":正在执行!" +i); } } }.start(); new Thread (new Runnable (){ @Override public void run () { for (int i = 0 ; i < 10 ; i++) { System.out.println(Thread.currentThread().getName()+":" + i); } } }).start();
方式3:实现Callable接口 (jdk5.0新增)
与使用 Runnable 相比, Callable 功能更强大些
相比 run()方法,可以有返回值
方法可以抛出异常
支持泛型的返回值(需要借助 FutureTask 类,获取返回结果)
Future 接口(了解)
可以对具体 Runnable、Callable 任务的执行结果进行取消、查询是否完成、获取结果等。
FutureTask 是 Futrue 接口的唯一的实现类
FutureTask 同时实现了 Runnable, Future 接口。它既可以作为Runnable 被线程执行,又可以作为 Future 得到 Callable 的返回值
缺点:在获取分线程执行结果的时候,当前线程(或是主线程)受阻塞,效率较低。
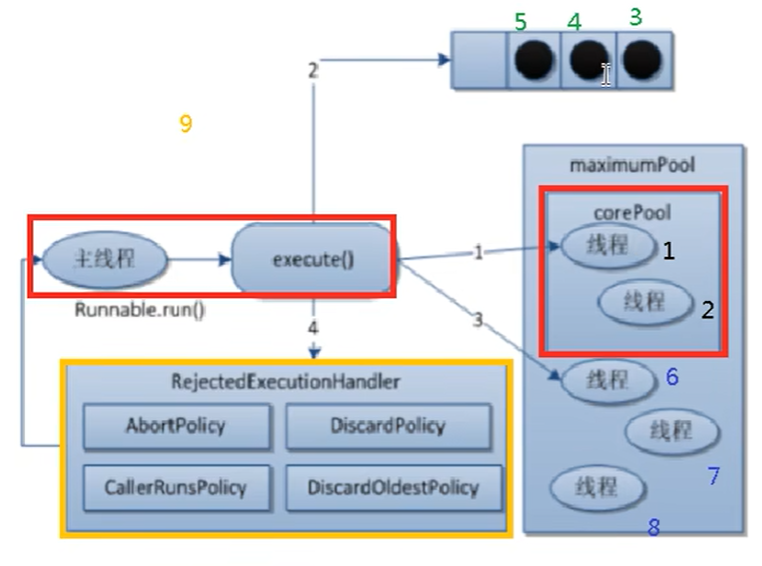
方式4:使用线程池(jdk5.0新增) 1 2 3 4 5 6 7 8 9 10 • ExecutorService:真正的线程池接口。常见子类 ThreadPoolExecutor – void execute (Runnable command) :执行任务/命令,没有返回值,一般用来执行 Runnable – <T> Future<T> submit (Callable<T> task) :执行任务,有返回值,一般又来执行 Callable – void shutdown () :关闭连接池 • Executors:一个线程池的工厂类,通过此类的静态工厂方法可以创建多种类型的线程池对象。 – Executors.newCachedThreadPool():创建一个可根据需要创建新线程的线程池 – Executors.newFixedThreadPool(int nThreads); 创建一个可重用固定线程数的线程池 – Executors.newSingleThreadExecutor() :创建一个只有一个线程的线程池 – Executors.newScheduledThreadPool(int corePoolSize):创建一个线程池,它可安排在给定延迟后运行命令或者定期地执行。
3. Thread类的常用方法、线程的生命周期 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 熟悉常用的构造器和方法: 1. 线程中的构造器 - public Thread() :分配一个新的线程对象。 - public Thread(String name) :分配一个指定名字的新的线程对象。 - public Thread(Runnable target) :指定创建线程的目标对象,它实现了Runnable接口中的run方法 - public Thread(Runnable target,String name) :分配一个带有指定目标新的线程对象并指定名字。 2.线程中的常用方法: > start():①启动线程 ②调用线程的run() > run():将线程要执行的操作,声明在run()中。 > currentThread():获取当前执行代码对应的线程 > getName(): 获取线程名 > setName(): 设置线程名 > sleep(long millis):静态方法,调用时,可以使得当前线程睡眠指定的毫秒数 > yield():静态方法,一旦执行此方法,就释放CPU的执行权,让系统的线程调度器重新调度一次 > join(): 在线程a中通过线程b调用join(),意味着线程a进入阻塞状态,直到线程b执行结束,线程a才结束阻塞状态,继续执行。 > isAlive():判断当前线程是否存活 3. 线程的优先级: getPriority():获取线程的优先级 setPriority():设置线程的优先级。范围[1,10] Thread类内部声明的三个常量: - MAX_PRIORITY(10):最高优先级 - MIN _PRIORITY (1):最低优先级 - NORM_PRIORITY (5):普通优先级,默认情况下main线程具有普通优先级。
线程的生命周期:
jdk5.0之前:
线程的生命周期有五种状态:新建(New)、就绪(Runnable)、运行(Running)、阻塞(Blocked)、死亡(Dead)
jdk5.0及之后:Thread类中定义了一个内部类State
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public enum State { NEW, RUNNABLE, BLOCKED, WAITING, TIMED_WAITING, TERMINATED; }
4. 如何解决线程安全问题(重点、难点)
的资源实行互斥访问
1 2 3 synchronized (同步锁){需要同步操作的代码 }
同步方法:synchronized 关键字直接修饰方法,表示同一时刻只有一个线程能1 2 3 4 public synchronized void method () {可能会产生线程安全问题的代码 }
- 重点关注两个事:共享数据及操作共享数据的代码;同步监视器(保证唯一性)
1 2 在实现Runnable接口的方式中,同步监视器可以考虑使用:this。 在继承Thread类的方式中,同步监视器要慎用this,可以考虑使用:当前类.class。
1 2 非静态的同步方法,默认同步监视器是this 静态的同步方法,默认同步监视器是当前类本身。
jdk5.0新增:Lock接口及其实现类。(保证多个线程共用同一个Lock的实例)
public void lock() :加同步锁。
public void unlock() :释放同步锁。
synchronized 与 Lock 的对比
Lock 是显式锁(手动开启和关闭锁,别忘记关闭锁),synchronized 是隐式锁,出了
Lock 只有代码块锁,synchronized 有代码块锁和方法锁
使用 Lock 锁,JVM 将花费较少的时间来调度线程,性能更好。并且具有更好的扩展性
(了解)Lock 锁可以对读不加锁,对写加锁,synchronized 不可以
(了解)Lock 锁可以有多种获取锁的方式,可以从 sleep 的线程中抢到锁,
5. 同步机制相关的问题
懒汉式的线程安全的写法1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 public class LazyOne {private static LazyOne instance;private LazyOne () {}public static synchronized LazyOne getInstance1 () {if (instance == null ){instance = new LazyOne (); } return instance;} public static LazyOne getInstance2 () {synchronized (LazyOne.class) {if (instance == null ) {instance = new LazyOne (); } return instance;} } public static LazyOne getInstance3 () {if (instance == null ){synchronized (LazyOne.class) {try {Thread.sleep(10 ); } catch (InterruptedException e) { e.printStackTrace(); } if (instance == null ){instance = new LazyOne (); } } } return instance;} }
同步机制会带来的问题:死锁
死锁产生的条件及规避方式
6. 线程间的通信
在同步机制下,考虑线程间的通信
wait() 、notify() 、notifyAll() 都需要使用在同步代码块或同步方法中。
高频笔试题:wait() / sleep()
企业真题(十) 2.1 线程概述 1. 什么是线程(*云网络) 略
2. 线程和进程有什么区别(*团、腾*、*云网络、神**岳、言*有物、直*科技) 进程:对应一个运行中的程序。
线程:运行中的进程的一条或多条执行路径。
3. 多线程使用场景(嘉*医疗)
手机app应用的图片的下载
迅雷的下载
Tomcat服务器上web应用,多个客户端发起请求,Tomcat针对多个请求开辟多个线程处理
2.2 如何实现多线程 1. 如何在Java中出实现多线程?(阿*校招、当*置业、鸿*网络、奥*医药、*科软、慧*、上海驿*软件、海*科) 1 2 3 类似问题: > 创建多线程用Runnable还是Thread(北京中*瑞飞) > 多线程有几种实现方法,都是什么?(锐*(上海)企业管理咨询)
四种。
2. Thread类中的start()和run()有什么区别?(北京中油**、爱*信、神*泰岳、直*科技,*软国际,上海*学网络) start():① 开启线程 ② 调用线程的run()
3. 启动一个线程是用run()还是start()?(*度) start()
4. Java中Runnable和Callable有什么不同?(平*金服、银*数据、好*在、亿*征信、花儿**网络) 1 2 3 4 5 6 与之前的方式的对比:与Runnable方式的对比的好处 > call()可以有返回值,更灵活 > call()可以使用throws的方式处理异常,更灵活 > Callable使用了泛型参数,可以指明具体的call()的返回值类型,更灵活 有缺点吗?如果在主线程中需要获取分线程call()的返回值,则此时的主线程是阻塞状态的。
5. 什么是线程池,为什么要使用它?(上海明*物联网科技) 1 2 3 4 此方式的好处: > 提高了程序执行的效率。(因为线程已经提前创建好了) > 提高了资源的复用率。(因为执行完的线程并未销毁,而是可以继续执行其他的任务) > 可以设置相关的参数,对线程池中的线程的使用进行管理
2.3 常用方法、生命周期 1. sleep() 和 yield()区别?(神*泰岳) sleep():一旦调用,就进入“阻塞”(或TIMED_WAITING状态)
yield():释放cpu的执行权,处在RUNNABLE的状态
2. 线程创建中的方法、属性情况?(招通**、数*互融) 略
3. 线程的生命周期?(中国**电子商务中心、*科软、慧*) 略
4. 线程的基本状态以及状态之间的关系?(直*科技) 1 2 3 4 类似问题: > 线程有哪些状态?如何让线程进入阻塞?(华*中*,*兴) > 线程有几个状态,就绪和阻塞有什么不同。(美*) > Java的线程都有哪几种状态(字*跳动、*东、*手)
略
5. stop()和suspend()方法为何不推荐使用?(上海驿*软件) stop():一旦执行,线程就结束了,导致run()有未执行结束的代码。stop()会导致释放同步监视器,导致线程安全问题。
suspend():与resume()搭配使用,导致死锁。
6. Java 线程优先级是怎么定义的?(软*动力) 三个常量。[1,10]
2.4 线程安全与同步机制 1. 你如何理解线程安全的?线程安全问题是如何造成的?(*软国际) 1 2 3 4 类似问题: > 线程安全说一下?(奥*医药) > 对线程安全的理解(*度校招) > 什么是线程安全?(银*数据)
略
2. 多线程共用一个数据变量需要注意什么?(史*夫软件) 线程安全问题
3. 多线程保证线程安全一般有几种方式?(来*科技、北京*信天*) 1 2 3 4 5 6 7 8 9 类似问题: > 如何解决其线程安全问题,并且说明为什么这样子去解决?(北京联合**) > 请说出你所知道的线程同步的方法。(天*伟业) > 哪些方法实现线程安全?(阿*) > 同步有几种实现方法,都是什么? (锐*企业管理咨询) > 你在实际编码过程中如何避免线程安全问题?(*软国际) > 如何让线程同步?(*手) > 多线程下有什么同步措施(阿*校招) > 同步有几种实现方法,都是什么?(海*科)
4. 用什么关键字修饰同步方法?(上海驿*软件) synchronized
5. synchronized加在静态方法和普通方法区别(来*科技) 同步监视器不同。静态:当前类本身 非静态:this
6. Java中synchronized和ReentrantLock有什么不同(三*重工) 1 2 3 4 类似问题: > 多线程安全机制中 synchronized和lock的区别(中*国际、*美、鸿*网络) > 怎么实现线程安全,各个实现方法有什么区别?(美*、字*跳动) > synchronized 和 lock 区别(阿*、*壳)
1 2 3 synchronized不管是同步代码块还是同步方法,都需要在结束一对{}之后,释放对同步监视器的调用。 Lock是通过两个方法控制需要被同步的代码,更灵活一些。 Lock作为接口,提供了多种实现类,适合更多更复杂的场景,效率更高。
7. 当一个线程进入一个对象的一个synchronized方法后,其它线程是否可进入此对象的其它方法?(鸿*网络) 需要看其他方法是否使用synchronized修饰,同步监视器的this是否是同一个。
只有当使用了synchronized,且this是同一个的情况下,就不能访问了。
8. 线程同步与阻塞的关系?同步一定阻塞吗?阻塞一定同步吗?(阿*校招、西安*创佳*) 同步一定阻塞;阻塞不一定同步。
2.5 死锁 1. 什么是死锁,产生死锁的原因及必要条件(腾*、阿*) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 1. 如何看待死锁? 不同的线程分别占用对方需要的同步资源不放弃,都在等待对方放弃自己需要的同步资源,就形成了线程的死锁。 我们编写程序时,要避免出现死锁。 2. 诱发死锁的原因? - 互斥条件 - 占用且等待 - 不可抢夺(或不可抢占) - 循环等待 以上4个条件,同时出现就会触发死锁。 3. 如何避免死锁? 针对条件1:互斥条件基本上无法被破坏。因为线程需要通过互斥解决安全问题。 针对条件2:可以考虑一次性申请所有所需的资源,这样就不存在等待的问题。 针对条件3:占用部分资源的线程在进一步申请其他资源时,如果申请不到,就主动释放掉已经占用的资源。 针对条件4:可以将资源改为线性顺序。申请资源时,先申请序号较小的,这样避免循环等待问题。
2. 如何避免死锁?(阿*、北京*蓝、*手) 见上。
2.6 线程通信 1. Java中notify()和notifyAll()有什么区别(汇*天下) 1 2 3 notify():一旦执行此方法,就会唤醒被wait()的线程中优先级最高的那一个线程。(如果被wait()的多个线程的优先级相同,则 随机唤醒一个)。被唤醒的线程从当初被wait的位置继续执行。 notifyAll():一旦执行此方法,就会唤醒所有被wait的线程。
2. 为什么wait()和notify()方法要在同步块中调用(北京*智) 因为调用者必须是同步监视器。
3. 多线程:生产者,消费者代码(同步、wait、notifly编程)(猫*娱乐) 1 2 3 4 类似问题: > 如何写代码来解决生产者消费者问题(上海明*物联网) > 多线程中生产者和消费者如何保证同步(*为) > 消费者生产者,写写伪代码(字*)
略
4. wait()和sleep()有什么区别?调用这两个函数后,线程状态分别作何改变?(字*、*东) 1 2 3 4 类似问题: > 线程中sleep()和wait()有什么区别?(外派*度) > Java线程阻塞调用 wait 函数和 sleep 区别和联系(阿*) > wait和sleep的区别,他们两个谁会释放锁(软*动力、*创)
1 2 3 4 5 6 7 8 9 10 11 相同点:一旦执行,当前线程都会进入阻塞状态 不同点: > 声明的位置:wait():声明在Object类中 sleep():声明在Thread类中,静态的 > 使用的场景不同:wait():只能使用在同步代码块或同步方法中 sleep():可以在任何需要使用的场景 > 使用在同步代码块或同步方法中:wait():一旦执行,会释放同步监视器 sleep():一旦执行,不会释放同步监视器 > 结束阻塞的方式:wait(): 到达指定时间自动结束阻塞 或 通过被notify唤醒,结束阻塞 sleep(): 到达指定时间自动结束阻塞
2.7 单例模式(线程安全) 1. 手写一个单例模式(Singleton),还要安全的(*通快递、君*科技) 饿汉式;安全的懒汉式;内部类;
2. 手写一个懒汉式的单例模式&解决其线程安全问题,并且说明为什么这样子去解决(5*) 1 2 类似问题: > 手写一个懒汉式的单例模式(北京联合**)
同上。
常用类与基础API String类 java.lang.String,字符串是常量,用双引号引起来表示。它们的值在创建之后不能更改
String的声明:final修饰、实现了Comparable接口
String的不可变性
当对字符串变量重新赋值时,需要重新指定一个字符串常量的位置进行赋值,不能在原有的位置修改
当对现有的字符串进行拼接或replace()操作时,需要重新开辟空间保存操作后的字符串,不能在原有的位置修改
String的两种定义方式:① 字面量的定义方式 String s = “hello” ② new 的方式:String s = new String(“hello”);
String的内存解析:字符串常量池、堆内存的使用
String s = new String(“hello”);在内存中创建的对象的个数。→ 创建了两个对象
String的连接操作:+
常量 + 常量:结果仍然存储在字符串常量池中,返回此字面量地址,此时的常量可能是字面量,也可能是final修饰的变量 、变量 + 常量 or 变量 + 变量:都会通过new的方式创建一个新的字符串,返回堆空间中此字符串对象的地址、concat(String otherString):调用完都返回一个新new的对象
String intern():返回的是字符串常量池中字面量的地址
熟悉String的构造器、与其他结构之间的转换
字符串 –> 基本数据类型、包装类 public static int parseInt(String s)
基本数据类型、包装类 –> 字符串 public String valueOf(int n)
字符串 –> 字符数组 public char[] toCharArray():将字符串中的全部字符存放在一个字符数组中的方法。public void getChars(int srcBegin, int srcEnd, char[] dst, int dstBegin):提供了将指定索引范围内的字符串存放到数组中的方法
字符数组 –> 字符串 String 类的构造器
编码和解码
编码:字符、字符串 –> 字节、字节数组。对应着编码集
解码:字节、字节数组 –> 字符、字符串。对应着解码集 在utf-8字符集中,一个汉字占用3个字节,一个字母1个字节,在gbk字符集中,一个汉字占用2个字节,一个字母1个字节 均向下兼容ASCII码
规则:解码集必须使用当初编码时使用的编码集。只要不一致,就可能出现乱码!
String常用方法
boolean isEmpty():字符串是否为空
int length():返回字符串的长度
String concat(xx):拼接
boolean equals(Object obj):比较字符串是否相等,区分大小写
boolean equalsIgnoreCase(Object obj):比较字符串是否相等,不区分大小写
int compareTo(String other):比较字符串大小,区分大小写,按照 Unicode 编码值比较大小
int compareToIgnoreCase(String other):比较字符串大小,不区分大小写
String toLowerCase():将字符串中大写字母转为小写
String toUpperCase():将字符串中小写字母转为大写
String trim():去掉字符串前后空白符
public String intern():结果在常量池中共享
boolean contains(xx):是否包含 xx
int indexOf(xx):从前往后找当前字符串中 xx,即如果有返回第一次出现的下标,要是没有返回-1
int indexOf(String str, int fromIndex):返回指定子字符串在此字符串中第一次出现处的索引,从指定的索引开始
int lastIndexOf(xx):从后往前找当前字符串中 xx,即如果有返回最后一次出现的下标,要是没有返回-1
int lastIndexOf(String str, int fromIndex):返回指定子字符串在此字符串中最后一次出现处的索引,从指定的索引开始反向搜索。
String substring(int beginIndex) :返回一个新的字符串,它是此字符串
String substring(int beginIndex, int endIndex) :返回一个新字符串,它是此字符串从 beginIndex 开始截取到 endIndex(不包含)的一个子字符串。
char charAt(index):返回index位置的字符
char[] toCharArray(): 将此字符串转换为一个新的字符数组返回
static String valueOf(char[] data) :返回指定数组中表示该字符序列的 String
static String valueOf(char[] data, int offset, int count) : 返回指定数组中表示该字符序列的 String
static String copyValueOf(char[] data): 返回指定数组中表示该字符序列的 String
static String copyValueOf(char[] data, int offset, int count):返回指定数组中表示该字符序列的 String
boolean startsWith(xx):测试此字符串是否以指定的前缀开始
boolean startsWith(String prefix, int toffset):测试此字符串从指定索引开始的子字符串是否以指定前缀开始
boolean endsWith(xx):测试此字符串是否以指定的后缀结束
String replace(char oldChar, char newChar):返回一个新的字符串,它是
String replace(CharSequence target, CharSequence replacement):
String replaceAll(String regex, String replacement):使用给定的replacement 替换此字符串所有匹配给定的正则表达式的子字符串。
String replaceFirst(String regex, String replacement):使用给定的 replacement 替换此字符串匹配给定的正则表达式的第一个子字符串。
String相关的算法问题。
模拟一个 trim 方法,去除字符串两端的空格。
将一个字符串进行反转。将字符串中指定部分进行反转。比如“abcdefg”反转为”abfedcg”
获取一个字符串在另一个字符串中出现的次数。 比如:获取“ ab”在“abkkcadkabkebfkabkskab” 中出现的次数
获取两个字符串中最大相同子串。比如: str1 = “abcwerthelloyuiodef”;str2 = “cvhellobnm” 提示:将短的那个串进行长度依次递减的子串与较长的串比较。
对字符串中字符进行自然顺序排序。 提示: 1)字符串变成字符数组。 2)对数组排序,选择,冒泡,Arrays.sort(); 3)将排序后的数组变成字符串。
StringBuffer、StringBuilder类 因为 String 对象是不可变对象,虽然可以共享常量对象,但是对于频繁字符串的修改和拼接操作,效率极低,空间消耗也比较高。因此,JDK 又在 java.lang包提供了可变字符序列 StringBuffer 和 StringBuilder 类型。
[面试题]String、StringBuffer、StringBuilder的区别
String:不可变的字符序列;底层使用char[] (jdk8及之前),底层使用byte[] (jdk9及之后)
知道什么场景下使用StringBuffer、StringBuilder
如果开发中需要频繁的针对于字符串进行增、删、改等操作,建议使用StringBuffer或StringBuilder替换String.
StringBuffer和StringBuilder中的常用方法
执行效率:StringBuilder > StringBuffer > String(从高到低)
jdk8之前的日期、时间API
System的currentTimeMillis()
两个Date的使用
java.util.Date:getTime(),toString(),很多过时的方法
java.sql.Date
java.text.SimpleDateFormat,SimpleDateFormat类是一个不与语言环境有关的方式来格式化和解析日期的具体类
Calendar日历类的使用,使用 Calendar.getInstance()方法获取 Calendar 实例
public int get(int field):返回给定日历字段的值
public void set(int field,int value) :将给定的日历字段设置为指定的值
public void add(int field,int amount):根据日历的规则,为给定的日历字段添加或者减去指定的时间量
public final Date getTime():将 Calendar 转成 Date 对象
public final void setTime(Date date):使用指定的 Date 对象重置 Calendar的时间
jdk8中新的日期、时间API 之前API面临的问题:
可变性:像日期和时间这样的类应该是不可变的。
偏移性:Date 中的年份是从 1900 开始的,而月份都从 0 开始。
格式化:格式化只对 Date 有用,Calendar 则不行。
此外,它们也不是线程安全的;不能处理闰秒等。
LocalDate、LocalTime、LocalDateTime –>类似于Calendar
Instant –>类似于Date
DateTimeFormatter —>类似于SimpleDateFormat
比较器(重点)
涉及到java.lang.Comparable,实现 Comparable 的类必须实现 compareTo(Object obj)方法,两个对象即通过
实现 Comparable 接口的对象列表(和数组)可以通过 Collections.sort 或Arrays.sort 进行自动排序。实现此接口的对象可以用作有序映射中的键或有序集合中的元素,无需指定比较器。
Comparable 的典型实现:
String:按照字符串中字符的 Unicode 值进行比较
Character:按照字符的 Unicode 值来进行比较
数值类型对应的包装类以及 BigInteger、BigDecimal:按照它们对应的数值大小进行比较
Boolean:true 对应的包装类实例大于 false 对应的包装类实例
Date、Time 等:后面的日期时间比前面的日期时间大
定制排序
当元素的类型没有实现 java.lang.Comparable 接口而又不方便修改代码(例如:一些第三方的类,你只有.class 文件,没有源文件)
如果一个类,实现了 Comparable 接口,也指定了两个对象的比较大小的规则,但是此时此刻我不想按照它预定义的方法比较大小,但是我又不能随意修改,因为会影响其他地方的使用,怎么办?
涉及到java.util.Comparator
重写 compare(Object o1,Object o2)方法,比较 o1 和 o2 的大小:如果方法返回正整数,则表示 o1 大于 o2;如果返回 0,表示相等;返回负整数,表示 o1 小于 o2。
可以将 Comparator 传递给 sort 方法(如 Collections.sort 或 Arrays.sort),从而允许在排序顺序上实现精确控制。
其它API java.lang.System 类
System类代表系统,系统级的很多属性和控制方法都放置在该类的内部。该类位于java.lang包。
由于该类的构造器是private的,所以无法创建该类的对象。其内部的成员变量和成员方法都是static的,所以也可以很方便的进行调用。
成员变量 Scanner scan = new Scanner(System.in);
System类内部包含in、out和err三个成员变量,分别代表标准输入流(键盘输入),标准输出流(显示器)和标准错误输出流(显示器)。
成员方法
native long currentTimeMillis():
void exit(int status):
void gc():
String getProperty(String key):
java.lang.Runtime类 每个 Java 应用程序都有一个 Runtime 类实例,使应用程序能够与其运行的环境相连接。
public static Runtime getRuntime(): 返回与当前 Java 应用程序相关的运行时对象。应用程序不能创建自己的 Runtime 类实例。
public long totalMemory():返回 Java 虚拟机中初始化时的内存总量。此方法返回的值可能随时间的推移而变化,这取决于主机环境。默认为物理电脑内存的1/64。
public long maxMemory():返回 Java 虚拟机中最大程度能使用的内存总量。默认为物理电脑内存的1/4。
public long freeMemory():回 Java 虚拟机中的空闲内存量。调用 gc 方法可能导致 freeMemory 返回值的增加。
和数学相关的类
java.lang.Math 类包含用于执行基本数学运算的方法,如初等指数、对数、平方根和三角函数。类似这样的工具类,其所有方法均为静态方法,并且不会创建对象,调用起来非常简单。
public static double abs(double a) :返回 double 值的绝对值。
1 2 double d1 = Math.abs(-5 ); double d2 = Math.abs(5 );
public static double ceil(double a) :返回大于等于参数的最小的整数。
1 2 3 double d1 = Math.ceil(3.3 ); double d2 = Math.ceil(-3.3 ); double d3 = Math.ceil(5.1 );
public static double floor(double a) :返回小于等于参数最大的整数。
1 2 3 double d1 = Math.floor(3.3 ); double d2 = Math.floor(-3.3 ); double d3 = Math.floor(5.1 );
public static long round(double a) :返回最接近参数的 long。(相当于四舍五入方法)
1 2 3 4 long d1 = Math.round(5.5 ); long d2 = Math.round(5.4 ); long d3 = Math.round(-3.3 ); long d4 = Math.round(-3.8 );
public static double pow(double a,double b):返回a的b幂次方法
public static double sqrt(double a):返回a的平方根
public static double random():返回[0,1)的随机值public static final double PI:返回圆周率
public static double max(double x, double y):返回x,y中的最大值
public static double min(double x, double y):返回x,y中的最小值
其它:acos,asin,atan,cos,sin,tan 三角函数
1 2 3 4 double result = Math.pow(2 ,31 );double sqrt = Math.sqrt(256 );double rand = Math.random();double pi = Math.PI;
java.math包
Integer类作为int的包装类,能存储的最大整型值为2^31-1,Long类也是有限的,最大为2^63-1。如果要表示再大的整数,不管是基本数据类型还是他们的包装类都无能为力,更不用说进行运算了。
java.math包的BigInteger可以表示不可变的任意精度的整数。BigInteger 提供所有 Java 的基本整数操作符的对应物,并提供 java.lang.Math 的所有相关方法。另外,BigInteger 还提供以下运算:模算术、GCD 计算、质数测试、素数生成、位操作以及一些其他操作。
构造器
BigInteger(String val):根据字符串构建BigInteger对象
方法
public BigInteger abs():返回此 BigInteger 的绝对值的 BigInteger。
BigInteger add(BigInteger val) :返回其值为 (this + val) 的 BigInteger
BigInteger subtract(BigInteger val) :返回其值为 (this - val) 的 BigInteger
BigInteger multiply(BigInteger val) :返回其值为 (this * val) 的 BigInteger
BigInteger divide(BigInteger val) :返回其值为 (this / val) 的 BigInteger。整数相除只保留整数部分。
BigInteger remainder(BigInteger val) :返回其值为 (this % val) 的 BigInteger。
BigInteger[] divideAndRemainder(BigInteger val):返回包含 (this / val) 后跟 (this % val) 的两个 BigInteger 的数组。
BigInteger pow(int exponent) :返回其值为 (this^exponent) 的 BigInteger。
BigDecimal
java.util.Random
boolean nextBoolean():返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 boolean 值。
void nextBytes(byte[] bytes):生成随机字节并将其置于用户提供的 byte 数组中。
double nextDouble():返回下一个伪随机数,它是取自此随机数生成器序列的、在 0.0 和 1.0 之间均匀分布的 double 值。
float nextFloat():返回下一个伪随机数,它是取自此随机数生成器序列的、在 0.0 和 1.0 之间均匀分布的 float 值。
double nextGaussian():返回下一个伪随机数,它是取自此随机数生成器序列的、呈高斯(“正态”)分布的 double 值,其平均值是 0.0,标准差是 1.0。
int nextInt():返回下一个伪随机数,它是此随机数生成器的序列中均匀分布的 int 值。
int nextInt(int n):返回一个伪随机数,它是取自此随机数生成器序列的、在 0(包括)和指定值(不包括)之间均匀分布的 int 值。
long nextLong():返回下一个伪随机数,它是取自此随机数生成器序列的均匀分布的 long 值。
企业真题(十一) 2.1 String 1. 以下两种方式创建的String对象有什么不同?(*团) 1 2 3 String str = new String ("test" );String str = "test" ;
略
2. String s = new String(“xyz”);创建了几个String Object? (新*陆) 两个
3. String a=”abc” String b=”a”+”bc” 问a==b?(网*邮箱) 是!
4. String 中 “+” 怎样实现?(阿*) 常量 + 常量 :略
变量 + 常量 、变量+变量:创建一个StringBuilder的实例,通过append()添加字符串,最后调用toString()返回一个字符串。(toString()内部new 一个String的实例)
5. Java中String是不是final的?(凡*科技) 1 2 3 4 类似问题: > String被哪些类继承?(网*邮箱) > 是否可以继承String类?(湖南*利软件) > String 是否可以继承?(阿*)
是
6. String为啥不可变,在内存中的具体形态?(阿*) 规定不可变。
String:提供字符串常量池。
7. String 可以在 switch中使用吗?(上海*睿) 可以。从jdk7开始可以使用
8. String中有哪些方法?列举几个(闪*购) 。。。
9. subString()到底做了什么?(银*数据) String str = “hello”;
String subStr = str.subString(1,3); //底层是new的方式返回一个subStr,实体内容是”el”
2.2 String、StringBuffer、StringBuilder 1. Java中操作字符串有哪些类?他们之间有什么区别。(南*电网) 1 2 3 4 类似问题: > String 和 StringBuffer区别?(亿*国际、天*隆、*团) > StringBuilder和StrignBuffer的区别?(平*金服) > StringBuilder和StringBuffer的区别以及实现?(*为)
1 2 3 > String:不可变的字符序列;底层使用char[] (jdk8及之前),底层使用byte[] (jdk9及之后) > StringBuffer:可变的字符序列;JDK1.0声明,线程安全的,效率低;底层使用char[] (jdk8及之前),底层使用byte[] (jdk9及之后) > StringBuilder:可变的字符序列;JDK5.0声明,线程不安全的,效率高;底层使用char[] (jdk8及之前),底层使用byte[] (jdk9及之后)
2. String的线程安全问题(闪*购) 线程不安全的
3. StringBuilder和StringBuffer的线程安全问题(润*软件) 略
2.3 Comparator与Comparable 1. 简单说说 Comparable 和 Comparator 的区别和场景?(软**力) 略
2. Comparable 接口和 Comparator 接口实现比较(阿*) 略
集合框架 数组存储数据方面的特点和弊端 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 数组存储多个数据方面的特点: > 数组一旦初始化,其长度就是确定的。 > 数组中的多个元素是依次紧密排列的,有序的,可重复的 > (优点) 数组一旦初始化完成,其元素的类型就是确定的。不是此类型的元素,就不能添加到此数组中。 int[] arr = new int[10]; arr[0] = 1; arr[1] = "AA";//编译报错 Object[] arr1 = new Object[10]; arr1[0] = new String(); arr1[1] = new Date(); > (优点)元素的类型既可以是基本数据类型,也可以是引用数据类型。 数组存储多个数据方面的弊端: > 数组一旦初始化,其长度就不可变了。 > 数组中存储数据特点的单一性。对于无序的、不可重复的场景的多个数据就无能为力了。 > 数组中可用的方法、属性都极少。具体的需求,都需要自己来组织相关的代码逻辑。 > 针对于数组中元素的删除、插入操作,性能较差。
Java集合框架体系(java.util包下) 1 2 3 4 5 6 7 8 9 10 java.util.Collection:存储一个一个的数据 |-----子接口:List:存储有序的、可重复的数据 ("动态"数组) |---- ArrayList(主要实现类)、LinkedList、Vector |-----子接口:Set:存储无序的、不可重复的数据(高中学习的集合) |---- HashSet(主要实现类)、LinkedHashSet、TreeSet java.util.Map:存储一对一对的数据(key-value键值对,(x1,y1)、(x2,y2) --> y=f(x),类似于高中的函数) |---- HashMap(主要实现类)、LinkedHashMap、TreeMap、Hashtable、Properties
1 2 3 4 5 学习的程度把握: 层次1:针对于具体特点的多个数据,知道选择相应的适合的接口的主要实现类,会实例化,会调用常用的方法。 层次2:区分接口中不同的实现类的区别。 ***************** 层次3:① 针对于常用的实现类,需要熟悉底层的源码 ② 熟悉常见的数据结构 (第14章讲)
Collection的常用方法 常用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 add(Object obj) addAll(Collection coll) clear() isEmpty() size() contains(Object obj) containsAll(Collection coll) retainAll(Collection coll) remove(Object obj) removeAll(Collection coll) hashCode() equals() toArray() ************** iterator() ---> 引出了迭代器接口
1 2 向Collection中添加元素的要求: > 要求元素所属的类一定要重写equals()!
1 2 3 集合与数组的相互转换: 集合 ---> 数组:toArray() 数组 ---> 集合:调用Arrays的静态方法asList(Object ... objs),返回一个List
迭代器接口
设计模式的一种
迭代器不负责数据的存储;负责对集合类的遍历
1 2 3 4 5 6 7 1. 如何获取迭代器(Iterator)对象?Iterator iterator = coll.iterator();2. 如何实现遍历(代码实现)while (iterator.hasNext()){ System.out.println(iterator.next()); }
增强for循环(foreach循环)的使用(jdk5.0新特性) 1 2 3 for (要遍历的集合或数组元素的类型 临时变量 : 要遍历的集合或数组变量){ 操作临时变量的输出 }
针对于集合来讲,增强for循环的底层仍然使用的是迭代器。
Collection的子接口:List List接口中存储数据的特点:用于存储有序的、可以重复的数据。—> 使用List替代数组,”动态”数组
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 小结: 增 add(Object obj) addAll(Collection coll) 删 remove(Object obj) remove(int index) 改 set(int index, Object ele) 查 get(int index) 插 add(int index, Object ele) addAll(int index, Collection eles) 长度 size() 遍历 iterator() :使用迭代器进行遍历 增强for 循环 一般的for 循环
1 2 3 4 5 6 7 8 9 List及其实现类特点 java.util.Collection:存储一个一个的数据 |-----子接口:List:存储有序的、可重复的数据 ("动态"数组) |---- ArrayList:List的主要实现类;线程不安全的、效率高;底层使用Object[]数组存储 在添加数据、查找数据时,效率较高;在插入、删除数据时,效率较低 |---- LinkedList:底层使用双向链表的方式进行存储;在对集合中的数据进行频繁的删除、插入操作时,建议 使用此类在插入、删除数据时,效率较高;在添加数据、查找数据时,效率较低; |---- Vector:List的古老实现类;线程安全的、效率低;底层使用Object[]数组存储 [面试题] ArrayList、Vector的区别? ArrayList、LinkedList的区别?
Collection的子接口:Set
Set中的常用的方法都是Collection中声明的方法,没有新增的方法
常见的实现类的对比
1 2 3 4 5 6 java.util.Collection:存储一个一个的数据 |-----子接口:Set:存储无序的、不可重复的数据(高中学习的集合) |---- HashSet:主要实现类;底层使用的是HashMap,即使用数组+单向链表+红黑树结构进行存储。(jdk8中) |---- LinkedHashSet:是HashSet的子类;在现有的数组+单向链表+红黑树结构的基础上,又添加了 一组双向链表,用于记录添加元素的先后顺序。即:我们可以按照添加元素的顺序实现遍历。便于频繁的查询操作。 |---- TreeSet:底层使用红黑树存储。可以按照添加的元素的指定的属性的大小顺序进行遍历。
1 2 3 4 5 6 7 8 >无序性: != 随机性。 添加元素的顺序和遍历元素的顺序不一致,是不是就是无序性呢? No! 到底什么是无序性?与添加的元素的位置有关,不像ArrayList一样是依次紧密排列的。 这里是根据添加的元素的哈希值,计算的其在数组中的存储位置。此位置不是依次排列的,表现为无序性。 >不可重复性:添加到Set中的元素是不能相同的。 比较的标准,需要判断hashCode()得到的哈希值以及equals()得到的boolean型的结果。 哈希值相同且equals()返回true,则认为元素是相同的。
1 2 3 添加到HashSet/LinkedHashSet中元素的要求: >要求元素所在的类要重写两个方法:equals() 和 hashCode()。 >同时,要求equals() 和 hashCode()要保持一致性!我们只需要在IDEA中自动生成两个方法的重写即可,即能保证两个方法的一致性。
TreeSet的使用
底层的数据结构:红黑树
添加数据后的特点:可以按照添加的元素的指定的属性的大小顺序进行遍历。
向TreeSet中添加的元素的要求:
要求添加到TreeSet中的元素必须是同一个类型的对象,否则会ClassCastException.
判断数据是否相同的标准
不再是考虑hashCode()和equals()方法了,也就意味着添加到TreeSet中的元素所在的类不需要重写hashCode()和equals()方法了
Map接口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 增: put(Object key,Object value) putAll(Map m) 删: Object remove(Object key) 改: put(Object key,Object value) putAll(Map m) 查: Object get(Object key) 长度: size() 遍历: 遍历key集:Set keySet() 遍历value集:Collection values() 遍历entry集:Set entrySet()
1 2 3 4 5 6 7 8 9 java.util.Map:存储一对一对的数据(key-value键值对,(x1,y1)、(x2,y2) --> y=f(x),类似于高中的函数) |---- HashMap:主要实现类;线程不安全的,效率高;可以添加null的key和value值;底层使用数组+单向链表+红黑树结构存储(jdk8) |---- LinkedHashMap:是HashMap的子类;在HashMap使用的数据结构的基础上,增加了一对双向链表,用于记录添加的元素的先后顺序,进而我们在遍历元素时,就可以按照添加的顺序显示。开发中,对于频繁的遍历操作,建议使用此类。 |---- TreeMap:底层使用红黑树存储;可以按照添加的key-value中的key元素的指定的属性的大小顺序进行遍历。需要考虑使用①自然排序 ②定制排序。 |---- Hashtable:古老实现类;线程安全的,效率低;不可以添加null的key或value值;底层使用数组+单向链表结构存储(jdk8) |---- Properties:其key和value都是String类型。常用来处理属性文件。 [面试题] 区别HashMap和Hashtable、区别HashMap和LinkedHashMap、HashMap的底层实现(① new HashMap() ② put(key,value))
1 2 3 4 5 HashMap中元素的特点: > HashMap中的所有的key彼此之间是不可重复的、无序的。所有的key就构成一个Set集合。--->key所在的类要重写hashCode()和equals() > HashMap中的所有的value彼此之间是可重复的、无序的。所有的value就构成一个Collection集合。--->value所在的类要重写equals() > HashMap中的一个key-value,就构成了一个entry。 > HashMap中的所有的entry彼此之间是不可重复的、无序的。所有的entry就构成了一个Set集合。
Collections工具类的使用 1 2 3 区分Collection 和 Collections Collection:集合框架中的用于存储一个一个元素的接口,又分为List和Set等子接口。 Collections:用于操作集合框架的一个工具类。此时的集合框架包括:Set、List、Map
Collections中的常用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 排序操作: - reverse(List):反转 List 中元素的顺序 - shuffle(List):对 List 集合元素进行随机排序 - sort(List):根据元素的自然顺序对指定 List 集合元素按升序排序 - sort(List,Comparator):根据指定的 Comparator 产生的顺序对 List 集合元素进行排序 - swap(List,int, int):将指定 list 集合中的 i 处元素和 j 处元素进行交换 查找 - Object max(Collection):根据元素的自然顺序,返回给定集合中的最大元素 - Object max(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最大元素 - Object min(Collection):根据元素的自然顺序,返回给定集合中的最小元素 - Object min(Collection,Comparator):根据 Comparator 指定的顺序,返回给定集合中的最小元素 - int binarySearch(List list,T key)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且必须是可比较大小的,即支持自然排序的。而且集合也事先必须是有序的,否则结果不确定。 - int binarySearch(List list,T key,Comparator c)在List集合中查找某个元素的下标,但是List的元素必须是T或T的子类对象,而且集合也事先必须是按照c比较器规则进行排序过的,否则结果不确定。 - int frequency(Collection c,Object o):返回指定集合中指定元素的出现次数 复制、替换 - void copy(List dest,List src):将src中的内容复制到dest中 - boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替换 List 对象的所有旧值 - 提供了多个unmodifiableXxx()方法,该方法返回指定 Xxx的不可修改的视图。 添加 - boolean addAll(Collection c,T... elements)将所有指定元素添加到指定 collection 中。 同步 - Collections 类中提供了多个 synchronizedXxx() 方法,该方法可使将指定集合包装成线程同步的集合,从而可以解决多线程并发访问集合时的线程安全问题
企业真题(十二) 2.1 集合概述 1. List,Set,Map是否继承自collection接口?(北京中*译咨询、思*贸易) Map不是。
2. 说说List,Set,Map三者的区别(民*银行) 1 2 类似问题: > Map与Set、List的区别(纬*)
略
3. 写出list、map、set接口的实现类,并说出其特点(华**为) 1 2 3 类似问题: > 集合有哪些, 各自有哪些特点, 各自的API有哪些?(湖**利软件) > List Map Set三个接口在存储元素时个有什么特点(*软)
略
4. 常见集合类的区别和适用场景(饿**) 略
5. 集合的父类是谁?哪些安全的?(北京中**信) 略。 不安全:ArrayList、HashMap、HashSet ; 安全:Vector、Hashtable
6. 集合说一下哪些是线程不安全的(*科软) 略
7. 遍历集合的方式有哪些?(恒*电子)
2.2 List接口 1. List下面有哪些实现(软**力) 略
2. ArrayList与LinkedList区别?(O**O、滴*、汇*天下、拓*软件、博纳**软件、上海*进天下,北京永生**信息、*联、在*途游) 1 2 类似问题: > ArrayList跟LinkedList的区别详细说出?(阿*校招、*东)
略。 补充上第14章中的源码(底层的数据结构)
3. ArrayList与Vector区别呢?为什么要用ArrayList取代Vector呢?(湖**利软件) Vector效率低。
4. Java.util.ArrayList常用的方法有哪些?(华**为) 略
5. Arraylist 是有序还是无序?为什么?(蜜*信息) 有序;底层使用数组:Object[]
2.3 Set接口 1. Set集合有哪些实现类,分别有什么特点?(拓*软件) 1 2 类似问题: > Set的实现类有哪些?(博*科技)
略
2. List集合和Set集合的区别?(亚*科技、*海*翼科技,*华电*系统,达*贷) 略
3. Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()? 它们有何区别?(鸿*网络) 1 2 3 类似问题: > 1.HashSet如何检查重复(创*科技) > 3.Set使用哪个区分不能重复的元素的?(北京创**荣信息)
hashCode() 、 equals()
4. TreeSet两种排序方式在使用的时候怎么起作用?(拓*软件) 在添加新的元素时,需要调用compareTo() 或 compare()
5. TreeSet的数据结构(*米) 红黑树
2.4 Map接口 1. 说一下Java的集合Map有哪些Map?(奥*医药) 略
2. final怎么用,修饰Map可以继续添加数据吗?(*深蓝) final HashMap map = new HashMap();
map.put(“AA”,123);
可以!
3. Set和Map的比较(亚*科技) HashSet底层就是HashMap
LinkedHashSet底层就是LinkedHashMap
TreeSet底层就是TreeMap
4. HashMap说一下,线程安全吗?(*米) 1 2 3 类似问题: > HashMap为什么线程不安全?(微*银行) > HashMap是线程安全的吗?为什么不安全?(*团、*东、顺*)
不安全
5. HashMap和Hashbable的区别?(银*数据、阿**巴芝麻信用、*众银行、爱*信、杭州*智公司) 1 2 类似问题: > HashMap 和 HashTable 有什么区别,以及如何使用,以及他的一些方法?(阿*校招、*东、*度校招、顺*)
略
6. Hashtable是怎么实现的,为什么线程安全?(迪*创新) 数组+单向链表;底层方法使用synchronized修饰
7. HashMap和LinkedHashMap的区别(北京*晨阳光) 略。
8. HashMap 和 TreeMap 的区别(*度,太极**、*线途游、阿*校招) 底层的数据结构截然不同。
9. HashMap里面实际装的是什么?(惠*) JDK7:HashMap内部声明了Entry,实现了Map中的Entry接口。(key,value作为Entry的两个属性出现)
JDK8:HashMap内部声明了Node,实现了Map中的Entry接口。(key,value作为Node的两个属性出现)
10. HashMap的key存储在哪里?和value存储在一起吗?那么value存储在哪里?说具体点?(湖**利软件、天*伟业) 数组+链表+红黑树。 key、value作为Node的属性出现
11. 自定义类型可以作为Key么?(阿*) 可以! 要重写hashCode() 和equals()
Collections 1. 集合类的工具类是谁?用过工具类哪些方法?(顺*) Collections。略
2. Collection 和 Collections的区别?(平*金服、*软) 略
3. ArrayList 如何实现排序(阿*) Collections.sort(list) 或 Collections.sort(list,comparator)
4. HashMap是否线程安全,怎样解决HashMap的线程不安全(中*卫星) 1 2 类似问题: > 怎么实现HashMap线程安全?(*团、*东、顺*)
略
泛型 泛型的理解
泛型在集合、比较器中的使用(重点)
在集合中使用泛型之前可能存在的问题
集合:ArrayList、HashMap、Iterator
比较器:Comparable、Comparator
自定义泛型类/泛型接口、泛型方法(熟悉)
class Order{ }
public 返回值类型 方法名(形参列表){}
具体的细节,见IDEA中的笔记。
泛型在继承上的体现 1 2 3 4 5 6 7 8 1. 类SuperA是类A的父类,则G<SuperA> 与 G<A>的关系:G<SuperA> 和 G<A>是并列的两个类,没有任何子父类的关系。 比如:ArrayList<Object> 、ArrayList<String>没有关系 2. 类SuperA是类A的父类或接口,SuperA<G> 与 A<G>的关系:SuperA<G> 与A<G> 有继承或实现的关系。 即A<G>的实例可以赋值给SuperA<G>类型的引用(或变量) 比如:List<String> 与 ArrayList<String>
通配符的使用
? 的使用 (重点)
以集合为例:可以读取数据、不能写入数据(例外:null)
? extends A
以集合为例:可以读取数据、不能写入数据(例外:null)
? super A
以集合为例:可以读取数据、可以写入A类型或A类型子类的数据(例外:null)
企业真题(十三) 1. Java 的泛型是什么?有什么好处和优点?JDK 不同版本的泛型有什么区别?(软*动力) 泛型,是程序中出现的不确定的类型。
以集合来举例:把一个集合中的内容限制为一个特定的数据类型,这就是generic背后的核心思想。
jdk7.0新特性:
1 ArrayList<String> list = new ArrayList <>();
后续版本的新特性:
1 Comparator<Employee> comparator = new Comparator <>(){}
2. 说说你对泛型的了解(*软国际) 略
数据结构与集合源码 数据结构
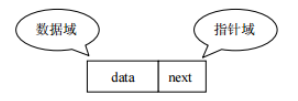
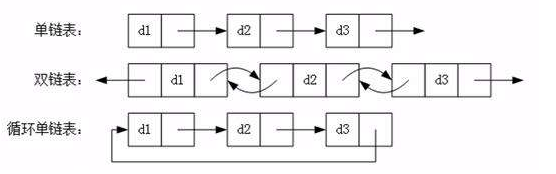
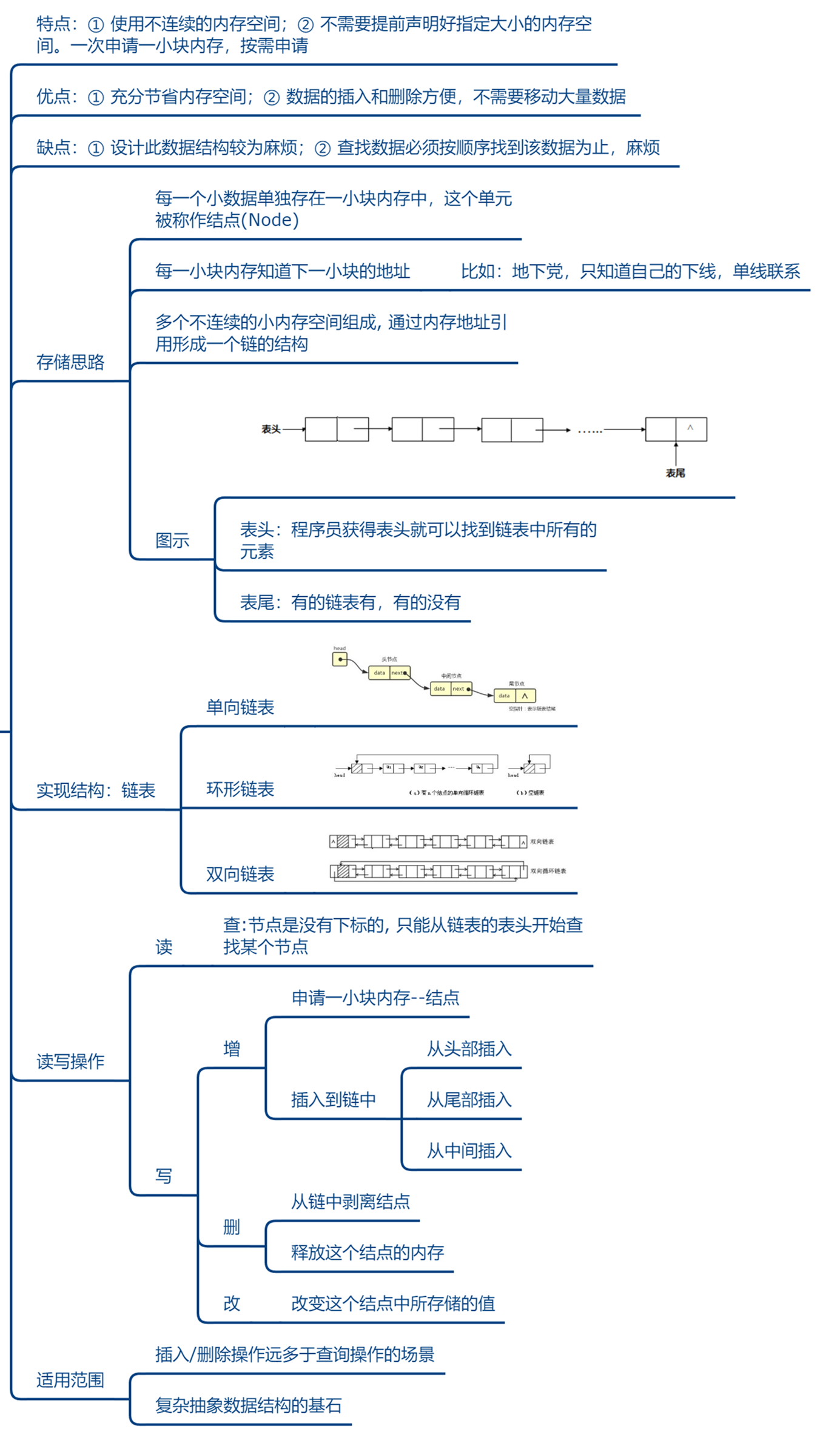
链表
栈
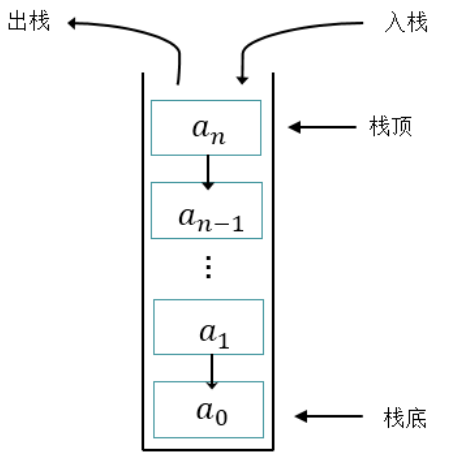
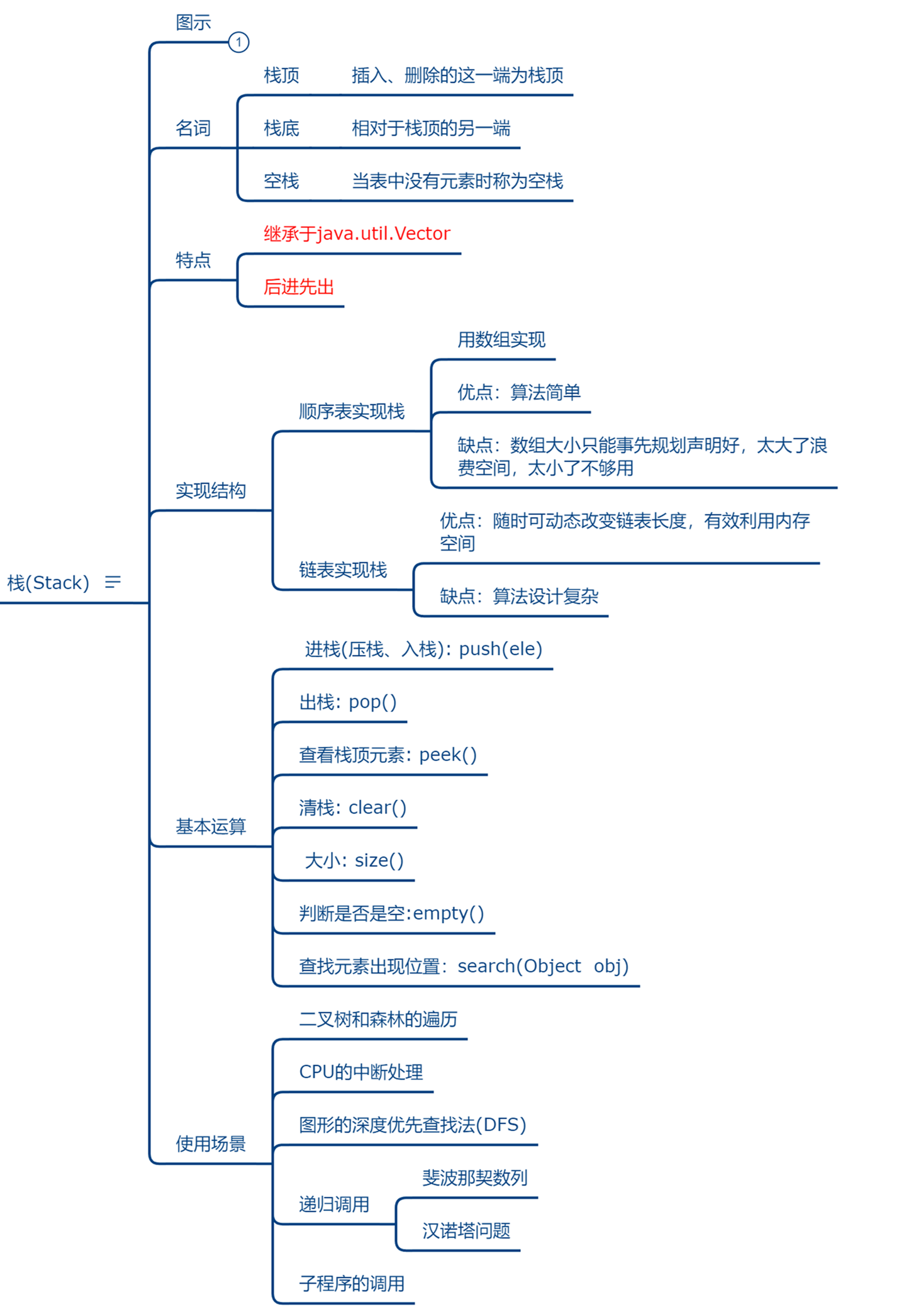
栈(Stack)又称为堆栈或堆叠,是限制仅在表的一端进行插入和删除运算的线性表。
栈按照先进后出(FILO,first in last out)的原则存储数据,先进入的数据被压入栈底,最后的数据在栈顶。每次删除(退栈)的总是删除当前栈中最后插入(进栈)的元素,而最先插入的是被放在栈的底部,要到最后才能删除。
核心类库中的栈结构有Stack和LinkedList。
Stack就是顺序栈,它是Vector的子类。
LinkedList是链式栈。
体现栈结构的操作方法:
peek()方法:查看栈顶元素,不弹出
pop()方法:弹出栈
push(E e)方法:压入栈
时间复杂度:
索引: O(n)
搜索: O(n)
插入: O(1)
移除: O(1)
图示:
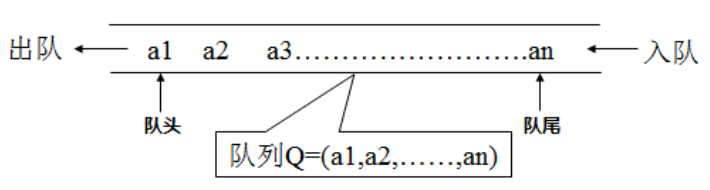
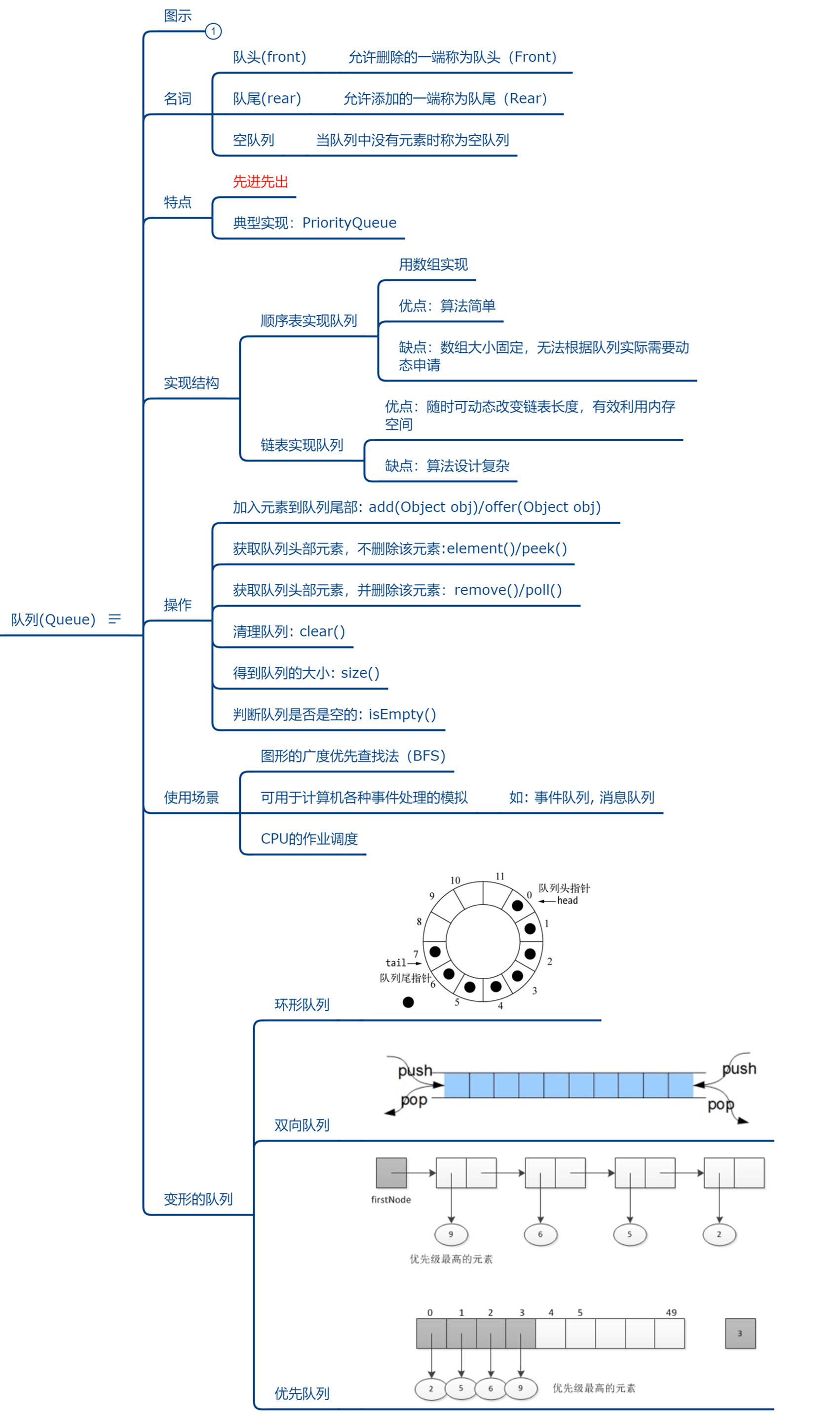
队列
队列(Queue)是只允许在一端进行插入,而在另一端进行删除的运算受限的线性表。
队列是逻辑结构,其物理结构可以是数组,也可以是链表。
队列的修改原则:队列的修改是依先进先出(FIFO)的原则进行的。新来的成员总是加入队尾(即不允许”加塞”),每次离开的成员总是队列头上的(不允许中途离队),即当前”最老的”成员离队。
图示:
树与二叉树
树的理解
专有名词解释:
结点:树中的数据元素都称之为结点
根节点:最上面的结点称之为根,一颗树只有一个根且由根发展而来,从另外一个角度来说,每个结点都可以认为是其子树的根
父节点:结点的上层结点,如图中,结点K的父节点是E、结点L的父节点是G
子节点:节点的下层结点,如图中,节点E的子节点是K节点、节点G的子节点是L节点
兄弟节点:具有相同父节点的结点称为兄弟节点,图中F、G、H互为兄弟节点
结点的度数:每个结点所拥有的子树的个数称之为结点的度,如结点B的度为3
树叶:度数为0的结点,也叫作终端结点,图中D、K、F、L、H、I、J都是树叶
非终端节点(或分支节点):树叶以外的节点,或度数不为0的节点。图中根、A、B、C、E、G都是
树的深度(或高度):树中结点的最大层次数,图中树的深度为4
结点的层数:从根节点到树中某结点所经路径上的分支树称为该结点的层数,根节点的层数规定为1,其余结点的层数等于其父亲结点的层数+1
同代:在同一棵树中具有相同层数的节点
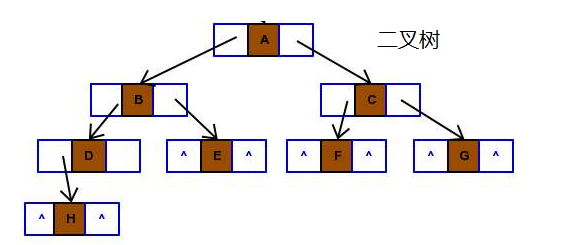
二叉树的基本概念
二叉树(Binary tree)是树形结构的一个重要类型。二叉树特点是每个结点最多只能有两棵子树,且有左右之分。许多实际问题抽象出来的数据结构往往是二叉树形式,二叉树的存储结构及其算法都较为简单,因此二叉树显得特别重要。
二叉树的遍历
前序遍历:中左右(根左右)
即先访问根结点,再前序遍历左子树,最后再前序遍历右子 树。前序遍历运算访问二叉树各结点是以根、左、右的顺序进行访问的。
中序遍历:左中右(左根右)
即先中前序遍历左子树,然后再访问根结点,最后再中序遍 历右子树。中序遍历运算访问二叉树各结点是以左、根、右的顺序进行访问的。
后序遍历:左右中(左右根)
即先后序遍历左子树,然后再后序遍历右子树,最后访问根 结点。后序遍历运算访问二叉树各结点是以左、右、根的顺序进行访问的。
前序遍历:ABDHIECFG
中序遍历:HDIBEAFCG
后序遍历:HIDEBFGCA
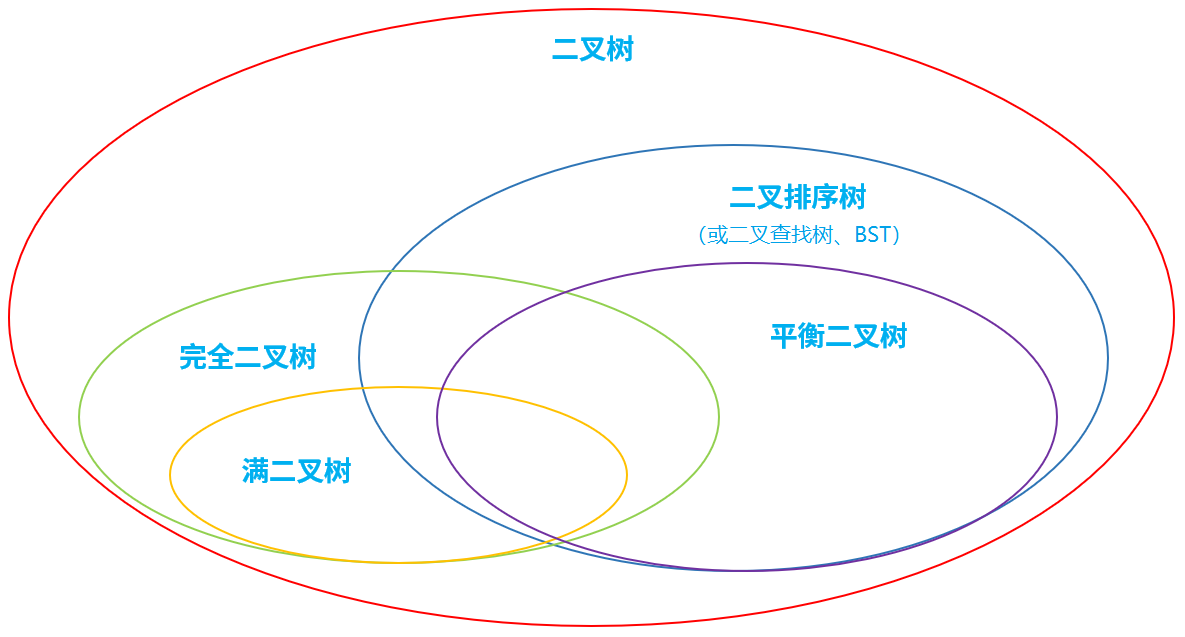
经典二叉树
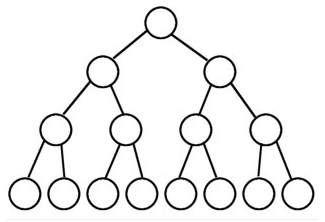
1、满二叉树: 除最后一层无任何子节点外,每一层上的所有结点都有两个子结点的二叉树。 第n层的结点数是2的n-1次方,总的结点个数是2的n次方-1
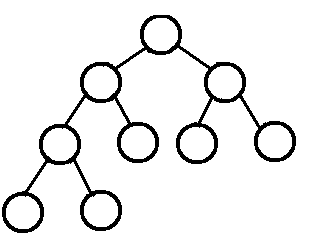
2、完全二叉树: 叶结点只能出现在最底层的两层,且最底层叶结点均处于次底层叶结点的左侧。
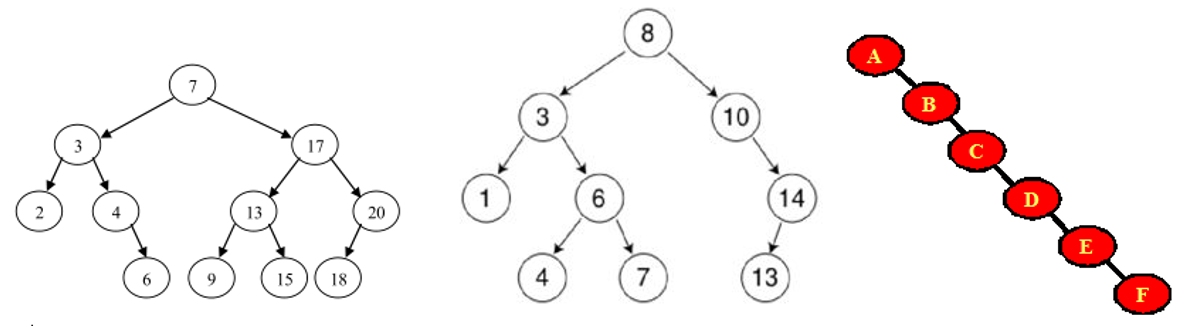
3、二叉排序/查找/搜索树:即为BST (binary search/sort tree)。满足如下性质:
对二叉查找树进行中序遍历,得到有序集合。便于检索。
4、平衡二叉树:(Self-balancing binary search tree,AVL)首先是二叉排序树,此外具有以下性质:
平衡二叉树的目的是为了减少二叉查找树的层次,提高查找速度。平衡二叉树的常用实现有红黑树、AVL、替罪羊树、Treap、伸展树等。
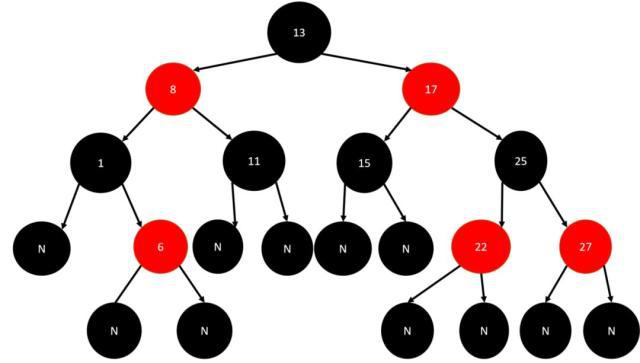
5、红黑树:即Red-Black Tree。红黑树的每个节点上都有存储位表示节点的颜色,可以是红(Red)或黑(Black)。
红黑树是一种自平衡二叉查找树,是在计算机科学中用到的一种数据结构,它是在 1972 年由 Rudolf Bayer 发明的。红黑树是复杂的,但它的操作有着良好的最坏情况运行时间,并且在实践中是高效的:它可以在 O(log n)时间内做查找,插入和删除, 这里的 n 是树中元素的数目。
红黑树的特性:
每个节点是红色或者黑色
根节点是黑色
每个叶子节点(NIL)是黑色。(注意:这里叶子节点,是指为空(NIL或NULL)的叶子节点)
每个红色节点的两个子节点都是黑色的。(从每个叶子到根的所有路径上不能有两个连续的红色节点)
从任一节点到其每个叶子的所有路径都包含相同数目的黑色节点(确保没有一条路径会比其他路径长出2倍)
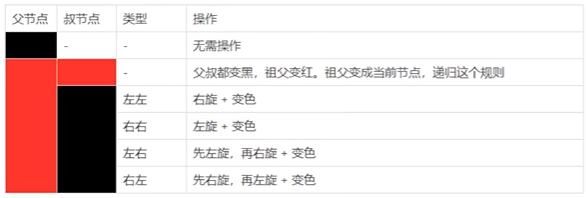
当我们插入或删除节点时,可能会破坏已有的红黑树,使得它不满足以上5个要求,那么此时就需要进行处理,使得它继续满足以上的5个要求:
1、recolor :将某个节点变红或变黑
2、rotation :将红黑树某些结点分支进行旋转(左旋或右旋)
红黑树可以通过红色节点和黑色节点尽可能的保证二叉树的平衡。主要是用它来存储有序的数据,它的时间复杂度是O(logN),效率非常之高。
List接口下的实现类的源码剖析 【面试题】ArrayList、Vector、LinkedList的三者的对比?
1 2 3 4 5 |-----子接口:List:存储有序的、可重复的数据 ("动态"数组) |---- ArrayList:List的主要实现类;线程不安全的、效率高;底层使用Object[]数组存储 在添加数据、查找数据时,效率较高;在插入、删除数据时,效率较低 |---- LinkedList:底层使用双向链表的方式进行存储;在对集合中的数据进行频繁的删除、插入操作时,建议使用此类在插入、删除数据时,效率较高;在添加数据、查找数据时,效率较低; |---- Vector:List的古老实现类;线程安全的、效率低;底层使用Object[]数组存储
ArrayList源码解析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 1. jdk7版本:(以jdk1.7.0_07为例) //如下代码的执行:底层会初始化数组,数组的长度为10。Object[] elementData = new Object[10]; ArrayList<String> list = new ArrayList<>(); list.add("AA"); //elementData[0] = "AA"; list.add("BB");//elementData[1] = "BB"; ... 当要添加第11个元素的时候,底层的elementData数组已满,则需要扩容。默认扩容为原来长度的1.5倍。并将原有数组 中的元素复制到新的数组中。 2. jdk8版本:(以jdk1.8.0_271为例) //如下代码的执行:底层会初始化数组,即:Object[] elementData = new Object[]{}; ArrayList<String> list = new ArrayList<>(); list.add("AA"); //首次添加元素时,会初始化数组elementData = new Object[10];elementData[0] = "AA"; list.add("BB");//elementData[1] = "BB"; ... 当要添加第11个元素的时候,底层的elementData数组已满,则需要扩容。默认扩容为原来长度的1.5倍。并将原有数组 中的元素复制到新的数组中。 小结: jdk1.7.0_07版本中:ArrayList类似于饿汉式 jdk1.8.0_271版本中:ArrayList类似于懒汉式
Vector源码解析 1 2 3 4 5 6 7 Vector源码解析:(以jdk1.8.0_271为例) Vector v = new Vector(); //底层初始化数组,长度为10.Object[] elementData = new Object[10]; v.add("AA"); //elementData[0] = "AA"; v.add("BB");//elementData[1] = "BB"; ... 当添加第11个元素时,需要扩容。默认扩容为原来的2倍。
LinkedList源码解析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 LinkedList在jdk8中的源码解析: LinkedList<String> list = new LinkedList<>(); //底层也没做啥 list.add("AA"); //将"AA"封装到一个Node对象1中,list对象的属性first、last都指向此Node对象1。 list.add("BB"); //将"BB"封装到一个Node对象2中,对象1和对象2构成一个双向链表,同时last指向此Node对象2 ... 因为LinkedList使用的是双向链表,不需要考虑扩容问题。 LinkedList内部声明: private static class Node<E> { E item; Node<E> next; Node<E> prev; }
Vector基本不使用了。
ArrayList底层使用数组结构,查找和添加(尾部添加)操作效率高,时间复杂度为O(1);删除和插入操作效率低,时间复杂度为O(n)
在选择了ArrayList的前提下,new ArrayList() : 底层创建长度为10的数组。new ArrayList(int capacity):底层创建指定capacity长度的数组。如果开发中,大体确认数组的长度,则推荐使用ArrayList(int capacity)这个构造器,避免了底层的扩容、复制数组的操作。
Map接口下的实现类的源码剖析 HashMap源码解析 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 1. jdk7中创建对象和添加数据过程(以JDK1.7.0_07为例说明): //创建对象的过程中,底层会初始化数组Entry[] table = new Entry[16]; HashMap<String,Integer> map = new HashMap<>(); ... map.put("AA",78); //"AA"和78封装到一个Entry对象中,考虑将此对象添加到table数组中。 ... 添加/修改的过程: 将(key1,value1)添加到当前的map中: 首先,需要调用key1所在类的hashCode()方法,计算key1对应的哈希值1,此哈希值1经过某种算法(hash())之后,得到哈希值2。 哈希值2再经过某种算法(indexFor())之后,就确定了(key1,value1)在数组table中的索引位置i。 1.1 如果此索引位置i的数组上没有元素,则(key1,value1)添加成功。 ---->情况1 1.2 如果此索引位置i的数组上有元素(key2,value2),则需要继续比较key1和key2的哈希值2 --->哈希冲突 2.1 如果key1的哈希值2与key2的哈希值2不相同,则(key1,value1)添加成功。 ---->情况2 2.2 如果key1的哈希值2与key2的哈希值2相同,则需要继续比较key1和key2的equals()。要调用key1所在类的equals(),将key2作为参数传递进去。 3.1 调用equals(),返回false: 则(key1,value1)添加成功。 ---->情况3 3.2 调用equals(),返回true: 则认为key1和key2是相同的。默认情况下,value1替换原有的value2。 说明:情况1:将(key1,value1)存放到数组的索引i的位置 情况2,情况3:(key1,value1)元素与现有的(key2,value2)构成单向链表结构,(key1,value1)指向(key2,value2) 随着不断的添加元素,在满足如下的条件的情况下,会考虑扩容: (size >= threshold) && (null != table[i]) 当元素的个数达到临界值(-> 数组的长度 * 加载因子)时,就考虑扩容。默认的临界值 = 16 * 0.75 --> 12. 默认扩容为原来的2倍。 2. jdk8与jdk7的不同之处(以jdk1.8.0_271为例): ① 在jdk8中,当我们创建了HashMap实例以后,底层并没有初始化table数组。当首次添加(key,value)时,进行判断,如果发现table尚未初始化,则对数组进行初始化。 ② 在jdk8中,HashMap底层定义了Node内部类,替换jdk7中的Entry内部类。意味着,我们创建的数组是Node[] ③ 在jdk8中,如果当前的(key,value)经过一系列判断之后,可以添加到当前的数组角标i中。如果此时角标i位置上有 元素。在jdk7中是将新的(key,value)指向已有的旧的元素(头插法),而在jdk8中是旧的元素指向新的 (key,value)元素(尾插法)。 "七上八下" ④ jdk7:数组+单向链表 jk8:数组+单向链表 + 红黑树 什么时候会使用单向链表变为红黑树:如果数组索引i位置上的元素的个数达到8,并且数组的长度达到64时,我们就将此索引i位置上 的多个元素改为使用红黑树的结构进行存储。(为什么修改呢?红黑树进行put()/get()/remove() 操作的时间复杂度为O(logn),比单向链表的时间复杂度O(n)的好。性能更高。 什么时候会使用红黑树变为单向链表:当使用红黑树的索引i位置上的元素的个数低于6的时候,就会将红黑树结构退化为单向链表。 3. 属性/字段: static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 默认的初始容量 16 static final int MAXIMUM_CAPACITY = 1 << 30; //最大容量 1 << 30 static final float DEFAULT_LOAD_FACTOR = 0.75f; //默认加载因子 static final int TREEIFY_THRESHOLD = 8; //默认树化阈值8,当链表的长度达到这个值后,要考虑树化 static final int UNTREEIFY_THRESHOLD = 6;//默认反树化阈值6,当树中结点的个数达到此阈值后,要考虑变为链表 //当单个的链表的结点个数达到8,并且table的长度达到64,才会树化。 //当单个的链表的结点个数达到8,但是table的长度未达到64,会先扩容 static final int MIN_TREEIFY_CAPACITY = 64; //最小树化容量64 transient Node<K,V>[] table; //数组 transient int size; //记录有效映射关系的对数,也是Entry对象的个数 int threshold; //阈值,当size达到阈值时,考虑扩容 final float loadFactor; //加载因子,影响扩容的频率
LinkedHashMap 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 1. LinkedHashMap 与 HashMap 的关系: > LinkedHashMap 是 HashMap的子类。 > LinkedHashMap在HashMap使用的数组+单向链表+红黑树的基础上,又增加了一对双向链表,记录添加的(key,value)的 先后顺序。便于我们遍历所有的key-value。 LinkedHashMap重写了HashMap的如下方法: Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) { LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e); linkNodeLast(p); return p; } 2. 底层结构:LinkedHashMap内部定义了一个Entry static class Entry<K,V> extends HashMap.Node<K,V> { Entry<K,V> before, after; //增加的一对双向链表 Entry(int hash, K key, V value, Node<K,V> next) { super(hash, key, value, next); } }
HashSet和LinkedHashSet的源码分析
HashSet底层使用的是HashMap
企业真题(十四) 数据结构相关 1. 链表和数组有什么区别?(腾*) 略
2. 栈是如何运行的?(西*信息技术) 先进后出。属于ADT(abstract data type),可以使用数组、链表实现栈结构
List集合源码相关 1. ArrayList的默认大小是多少,以及扩容机制(顺*、凡*科技) 1 2 3 4 类似问题: > 说说ArrayList的扩容机制吧(国*电网) > 讲一下ArrayList的扩容机制(*实在) > ArrayList的扩容机制,为什么是10,为什么是1.5倍(*软国际)
略
2. ArrayList的底层是怎么实现的?(腾*) 1 2 3 类似问题: 集合类的ArrayList底层(安全不安全,扩容,初始大小,添加删除查询是怎么操作的,底层是什么组成的) (湖**利软件、汇*云通、猎*、苏州***动、上海*进天下、北京博*软件、*科软、大连*点科技、中*亿达、德*物流、天*伟业、猫*娱乐)
略。
建议:ArrayList(int capacity){}
3. 在ArrayList中remove后面几个元素该怎么做?(惠*、中*亿达) 前移。
4. ArrayList1.7和1.8的区别(拓*思) 类似于饿汉式、懒汉式
5. 数组和 ArrayList 的区别(阿*、*科软) ArrayList看做是对数组的常见操作的封装。
6. 什么是线程安全的List?(平*金服) Vector:线程安全的。
ArrayList:线程不安全。—-> 使用同步机制处理。
1 2 HashMap:线程不安全。 ----> 使用同步机制处理。 -----> JUC:ConcurrentHashMap
HashMap集合源码相关 1. 说说HahMap底层实现(新*股份、顺*、猫*娱乐) 1 2 3 4 5 6 7 8 9 10 11 12 类似问题: > HashMap的实现讲一下?(腾*,上海**网络) > 说说HashMap的底层执行原理?(滴*,纬*软件,上海*想,*昂,*蝶**云,宇*科技,*东数科,猎*网) > 详细说一下 HashMap 的 put 过程(*度) > Java中的HashMap的工作原理是什么?(北京中**译咨询) > 集合类的HashMap底层(安全不安全,扩容,初始大小,添加删除查询是怎么操作的,底层是什么组成的)(湖**利软件) > HashMap 的存储过程(爱*信、杭州*智) > Hashmap底层实现及构造(汇**通、猎*、苏州博*讯动、上海*进天下、北京博*软件、*科软、大连*点科技、中*亿达、德*物流、天*伟业、猫*娱乐) > HashMap的实现原理(腾*、阿*) > HaspMap底层讲一讲(*米) > 说一下HashMap的实现,扩容机制?(*节) > 讲一下 HashMap 中 put 方法过程?(阿*)
略。建议以JDK8为主说明。
2. HashMap初始值16,临界值12是怎么算的(软**力) 16从底层源码的构造器中看到的。
12:threshold,使用数组的长度*加载因子(loadFactor)
3. HashMap长度为什么是2的幂次方(国*时代) 为了方便计算要添加的元素的底层的索引i。
4. HashMap怎么计算哈希值和索引?扩容机制?怎么解决hash冲突?(*软国际、中软*腾) 1 2 3 4 类似问题: > HashMap key的哈希冲突了怎么做(新*股份) > HashMap的默认大小是多少,以及扩容机制(顺*、凡*科技) > 讲一下HashMap的扩容机制?(好实*)
略
5. HashMap底层是数组+链表,有数组很快了,为什么加链表?(润*软件) 因为产生了哈希冲突。解决方案,使用链表的方式。保证要添加的元素仍然在索引i的位置上。
6. HashMap为什么长度达到一定的长度要转化为红黑树(*度) 1 2 类似问题: > HashMap为什么用红黑树(*软国际)
红黑树的常用操作的时间复杂度O(logn),比单向链表的O(n)效率高。
7. HashMap什么时候扩充为红黑树,什么时候又返回到链表?(汉*) 1 2 3 4 类似问题: > HashMap什么时候转换为红黑树(杭州*智公司) > 当HashMap中相同hashcode值的数据超过多少时会转变成红黑树?(百*云创) > 什么时候是数据+链表,什么时候是红黑树(*软国际)
索引i的位置的链表长度超过8且数组长度达到64,需要索引i位置要变成红黑树。
当索引i的位置元素的个数低于6时,要红黑树结构转为单向链表。为什么?节省空间。
8. 在 JDK1.8中,HashMap的数据结构与1.7相比有什么变化,这些变化的好处在哪里?(海*科) 1 2 3 4 5 6 7 8 9 10 11 12 ① 在jdk8中,当我们创建了HashMap实例以后,底层并没有初始化table数组。当首次添加(key,value)时,进行判断, 如果发现table尚未初始化,则对数组进行初始化。 ② 在jdk8中,HashMap底层定义了Node内部类,替换jdk7中的Entry内部类。意味着,我们创建的数组是Node[] ③ 在jdk8中,如果当前的(key,value)经过一系列判断之后,可以添加到当前的数组角标i中。如果此时角标i位置上有 元素。在jdk7中是将新的(key,value)指向已有的旧的元素(头插法),而在jdk8中是旧的元素指向新的 (key,value)元素(尾插法)。 "七上八下" ④ jdk7:数组+单向链表 jk8:数组+单向链表 + 红黑树 什么时候会使用单向链表变为红黑树:如果数组索引i位置上的元素的个数达到8,并且数组的长度达到64时,我们就将此索引i位置上 的多个元素改为使用红黑树的结构进行存储。(为什么修改呢?红黑树进行put()/get()/remove() 操作的时间复杂度为O(logn),比单向链表的时间复杂度O(n)的好。性能更高。 什么时候会使用红黑树变为单向链表:当使用红黑树的索引i位置上的元素的个数低于6的时候,就会将红黑树结构退化为单向链表。
9. HashMap的get()方法的原理?(顺*) 参考put()
hashCode和equals 1. hashcode和equals区别?(海*供应链管理) 略
2. hashCode() 与 equals() 生成算法、方法怎么重写?(阿*校招) 进行equals()判断使用的属性,通常也都会参与到hashCode()的计算中。
尽量保证hashCode()的一致性。(使用IDEA自动生成,hashCode()自动使用相关的算法。
3. 说一下equals和==的区别,然后问equals相等hash值一定相等吗?hash值相等equals一定相等吗?(南*电网、上海*智网络) equals相等hash值一定相等吗? 是
hash值相等equals一定相等吗?不一定
Set集合源码相关 1. HashSet存放数据的方式?(拓*软件) 底层使用HashMap。说一下HashMap
2. Set是如何实现元素的唯一性?(湖**利软件) 略
3. 用哪两种方式来实现集合的排序(凡*科技) 1 2 类似问题: > 集合怎么排序?(北京中**信科技)
自然排序、定制排序。
File类与IO流 File类的使用
位于java.io包下
File类的一个实例对应着磁盘上的一个文件或文件目录。 —-> “万事万物皆对象”
(熟悉)File的实例化、常用的方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 构造器 * public File(String pathname) :以 pathname 为路径创建 File 对象,可以是绝对路径或者相对路径,如果 pathname 是相对路径,则默认的当前路径在系统属性user.dir 中存储。 * public File(String parent, String child) :以 parent 为父路径,child 为子路径创建 File 对象。 * public File(File parent, String child) :根据一个父 File 对象和子文件路径创建 File 对象。 获取文件和目录基本信息 * public String getName() :获取名称 * public String getPath() :获取路径 * public String getAbsolutePath():获取绝对路径 * public File getAbsoluteFile():获取绝对路径表示的文件 * public String getParent():获取上层文件目录路径。若无,返回null * public long length() :获取文件长度(即:字节数)。不能获取目录的长度。 * public long lastModified() :获取最后一次的修改时间,毫秒值 列出目录的下一级 * public String[] list() :返回一个String数组,表示该File目录中的所有子文件或目录。 * public File[] listFiles() :返回一个File数组,表示该File目录中的所有的子文件或目录。 File类的重命名功能 * public boolean renameTo(File dest):把文件重命名为指定的文件路径。 判断功能的方法 * public boolean exists() :此File表示的文件或目录是否实际存在。 * public boolean isDirectory() :此File表示的是否为目录。 * public boolean isFile() :此File表示的是否为文件。 * public boolean canRead() :判断是否可读 * public boolean canWrite() :判断是否可写 * public boolean isHidden() :判断是否隐藏 创建、删除功能 * public boolean createNewFile() :创建文件。若文件存在,则不创建,返回false。 * public boolean mkdir() :创建文件目录。如果此文件目录存在,就不创建了。如果此文件目录的上层目录不存在,也不创建。 * public boolean mkdirs() :创建文件目录。如果上层文件目录不存在,一并创建。 * public boolean delete() :删除文件或者文件夹 删除注意事项:① Java中的删除不走回收站。② 要删除一个文件目录,请注意该文件目录内不能包含文件或者文件目录。
File类中声明了新建、删除、获取名称、重命名等方法,并没有涉及到文件内容的读写操作。要想实现文件内容的读写,我们就需要使用io流。
File类的对象,通常是作为io流操作的文件的端点出现的。代码层面,将File类的对象作为参数传递到IO流相关类的构造器中。
IO流的概述
IO流的分类
流向:输入流、输出流
处理数据单位:字节流、字符流
流的角色:节点流、处理流
IO的4个抽象基类:InputStream \ OutputStream \ Reader \ Writer
节点流之一:文件流
FileInputStream \ FileOutputStream \ FileReader \ FileWriter
执行步骤:
第1步:创建读取或写出的File类的对象
第2步:创建输入流或输出流
第3步:具体的读入或写出的过程。
第4步:关闭流资源,避免内存泄漏
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 @Test public void test5 () { FileReader fr = null ; FileWriter fw = null ; try { File srcFile = new File ("hello.txt" ); File destFile = new File ("hello_copy.txt" ); fr = new FileReader (srcFile); fw = new FileWriter (destFile); char [] cbuffer = new char [5 ]; int len; while ((len = fr.read(cbuffer)) != -1 ) { fw.write(cbuffer, 0 , len); } System.out.println("复制成功" ); } catch (IOException e) { e.printStackTrace(); } finally { try { if (fw != null ) fw.close(); } catch (IOException e) { e.printStackTrace(); } try { if (fr != null ) fr.close(); } catch (IOException e) { e.printStackTrace(); } } }
注意点:
处理流之一:缓冲流
BufferedInputStream \ BufferedOutputStream \ BufferedReader \ BufferedWriter
作用:实现更高效的读写数据的操作
处理流之二:转换流
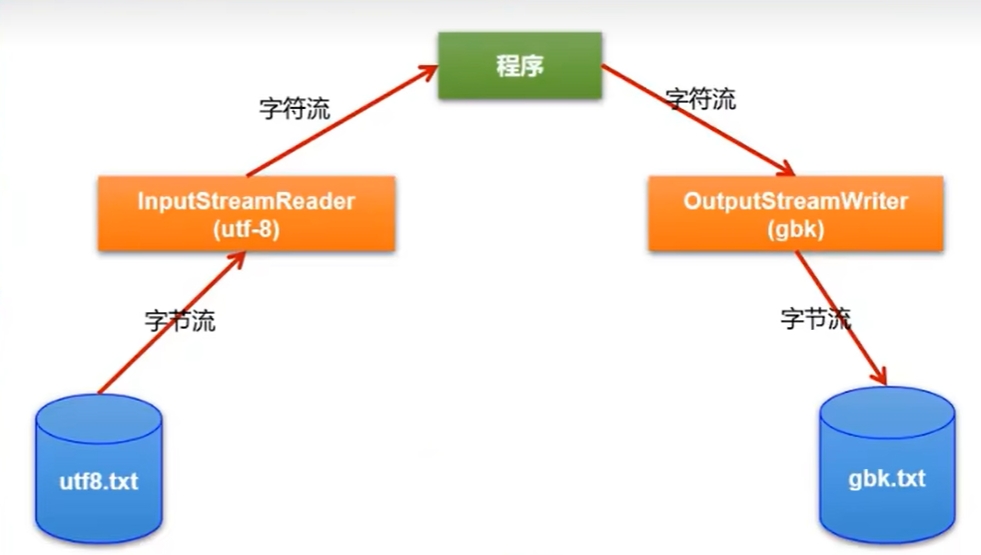
层次1:熟悉转换流的使用
InputStreamReader、OutputStreamWriter:
InputStreamReader:将一个输入型的字节流转换为输入型的字符流。
OutputStreamWriter:将一个输出型的字符流转换为输出型的字节流。
层次2:(掌握)字符的编码和解码的过程、常用的字符集
解决相关的问题:读写字符出现乱码!本质问题:使用的解码集与编码集不一致。
处理流之三:对象流
层次1:熟悉对象流的使用
ObjectInputStream:反序列化时需要使用的api,将文件中的数据或网络传输过来的数据还原为内存中的Java对象
ObjectOutputStream:序列化时需要使用的api,将内存中的Java对象保存在文件中或通过网络传输出去
层次2:对象的序列化机制
对象序列化机制允许把内存中的Java对象转换成平台无关的二进制流,从而允许把这种二进制流持久地保存在磁盘上,或通过网络将这种二进制流传输到另一个网络节点。//当其它程序获取了这种二进制流,就可以恢复成原来的Java对象。
自定义类要想实现序列化机制,需要满足:
对于基本数据类型的属性:默认就是可以序列化的
其它流的使用
了解:数据流:DataInputStream 、DataOutputStream
了解:标准的输入流、标准的输出流:System.in 、System.out
了解:打印流:PrintStream、PrintWriter
企业真题(十五) IO流概述 1. 谈谈Java IO里面的常用类,字节流,字符流(银*数据) 略
2. Java 中有几种类型的流?JDK为每种类型的流提供一些抽象类以供继承,请说出他们分别是哪些类?(上海*厦*联网、极*科技) InputStream \ OutputStream \ Reader \ Writer
3. 流一般需不需要关闭?如果关闭的话用什么方法?处理流是怎么关闭的?(银*数据) 需要。close()
处理流在关闭过程中,也会关闭内部的流。
4. OutputStream里面的write()是什么意思?(君*科技) 数据写出的意思。
缓冲流 1. BufferedReader属于哪种流?他主要是用来做什么的?(国*电网) 略
2. 什么是缓冲区?有什么作用?(北京中油**) 内部提供了一个数组,将读取或要写出的数据,现在此数组中缓存。达到一定程度时,集中性的写出。
作用:减少与磁盘的交互,进而提升读写效率。
转换流 1. 字节流和字符流是什么?怎么转换?(北京蓝*、*海*供应链管理)
序列化 1. 什么是Java序列化,如何实现(君*科技、上海*厦物联网) 1 2 对象序列化机制允许把内存中的Java对象转换成平台无关的二进制流,从而允许把这种二进制流持久地保存在磁盘上, 或通过网络将这种二进制流传输到另一个网络节点。//当其它程序获取了这种二进制流,就可以恢复成原来的Java对象。
2. Java有些类中为什么需要实现Serializable接口?(阿*校招) 便于此类的对象实现序列化操作。
网络编程 网络编程概述
计算机网络:把分布在不同地理区域的计算机与专门的外部设备用通信线路互连成一个规模大、功能强的网络系统,从而使众多的计算机可以方便地互相传递信息、共享硬件、软件、数据信息等资源。
网络编程的目的:直接或间接地通过网络协议与其它计算机实现数据交换,进行通讯。
需要解决的三个问题:
问题1:如何准确地定位网络上一台或多台主机
问题2:如何定位主机上的特定的应用
问题3:找到主机后,如何可靠、高效地进行数据传输
要素1:IP地址
使用具体的一个ip地址对应具体的一个互联网上的主机
IP分类:
角度一:IPv4(占用4个字节)、IPv6(占用16个字节)
角度二:公网地址、私网地址(或局域网,以192.168开头)
域名:便捷的记录ip地址
使用InetAddress类表示IP地址
实例化:getByName(String host) 、getLocalHost()
常用方法:getHostName() 、getHostAddress()
要素2:端口号
用于区分同一台主机上的不同的进程,可以唯一标识主机中的进程(应用程序)
不同的进程分配不同的端口号
范围:0-65535
要素3:网络通信协议 为了实现可靠而高效的数据传输。
这里有两套参考模型
OSI参考模型:将网络分为7层,模型过于理想化,未能在因特网上进行广泛推广
TCP/IP参考模型(或TCP/IP协议):将网络分为4层:应用层、传输层、网络层、物理+数据链路层,事实上的国际标准。
在传输层中涉及到两个协议:TCP、UDP。二者的对比
TCP:可靠的连接(发送数据前,需要三次握手、四次挥手),进行大数据量的传输,效率低。
UDP:不可靠的连接(发送前,不需要确认对方是否在)、使用数据报传输(限制在64kb以内)、效率高。
TCP的三次握手、四次挥手
TCP 协议中,在发送数据的准备阶段,客户端与服务器之间的三次交互,以保证连接的可靠。第一次握手,客户端向服务器端发起 TCP 连接的请求;第二次握手,服务器端发送针对客户端 TCP 连接请求的确认;第三次握手,客户端发送确认的确认。
TCP 协议中,在发送数据结束后,释放连接时需要经过四次挥手。第一次挥手:客户端向服务器端提出结束连接,让服务器做最后的准备工作。此时,客户端处于半关闭状态,即表示不再向服务器发送数据了,但是还可以接受数据;第二次挥手:服务器接收到客户端释放连接的请求后,会将最后的数据发给客户端。并告知上层的应用进程不再接收数据;第三次挥手:服务器发送完数据后,会给客户端发送一个释放连接的报文。那么客户端接收后就知道可以正式释放连接了;第四次挥手:客户端接收到服务器最后的释放连接报文后,要回复一个彻底断开的报文。这样服务器收到后才会彻底释放连接。这里客户端,发送完最后的报文后,会等待 2MSL(Maximum Segment Lifetime),因为有可能服务器没有收到最后的报文,那么服务器迟迟没收到,就会再次给客户端发送释放连接的报文,此时客户端在等待时间范围内接收到,会重新发送最后的报文,并重新计时。如果等待 2MSL 后,没有收到,那么彻底断开。
TCP网络编程 开发步骤:
客户端程序:
创建 Socket :根据指定服务端的 IP 地址或端口号构造 Socket 类对象。若服务器端响应,则建立客户端到服务器的通信线路。若连接失败,会出现异常。
打开连接到 Socket 的输入/ 出流: 使用 getInputStream()方法获得输入流,使用getOutputStream()方法获得输出流,进行数据传输
按照一定的协议对 Socket 进行读/ 写操作:通过输入流读取服务器放入线路的信息(但不能读取自己放入线路的信息),通过输出流将信息写入线路。
关闭 Socket :断开客户端到服务器的连接,释放线路
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 @Test public void client () { Socket socket = null ; OutputStream os = null ; try { InetAddress inetAddress = InetAddress.getByName("192.168.21.107" ); int port = 8989 ; socket = new Socket (inetAddress, port); os = socket.getOutputStream(); os.write("你好,我是客户端,请多多关照" .getBytes()); } catch (IOException e) { e.printStackTrace(); } finally { try { if (socket != null ) socket.close(); } catch (IOException e) { e.printStackTrace(); } try { if (os != null ) { os.close(); } } catch (IOException e) { e.printStackTrace(); } } }
服务器端程序:
调用 ServerSocket(int port) :创建一个服务器端套接字,并绑定到指定端口上。用
调用 accept() :监听连接请求,如果客户端请求连接,则接受连接,返回通信套接
调用 该 Socket 类对象的 getOutputStream() 和 getInputStream () :获取输出流和
关闭 Socket 对象:客户端访问结束,关闭通信套接字。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 @Test public void server () { ServerSocket serverSocket = null ; Socket socket = null ; InputStream is = null ; try { int port = 8989 ; serverSocket = new ServerSocket (port); socket = serverSocket.accept(); System.out.println("服务器端已开启" ); System.out.println("收到了来自于" + socket.getInetAddress().getHostAddress() + "的连接" ); is = socket.getInputStream(); byte [] buffer = new byte [5 ]; int len; ByteArrayOutputStream baos = new ByteArrayOutputStream (); while ((len = is.read(buffer)) != -1 ) { baos.write(buffer,0 ,len); } System.out.println(baos.toString()); System.out.println("\n数据接收完毕" ); } catch (IOException e) { e.printStackTrace(); } finally { try { if (socket != null ) { socket.close(); } } catch (IOException e) { e.printStackTrace(); } try { if (serverSocket != null ) { serverSocket.close(); } } catch (IOException e) { e.printStackTrace(); } try { if (is != null ) { is.close(); } } catch (IOException e) { e.printStackTrace(); } } }
UDP网络编程 开发步骤:
发送端程序:
创建 DatagramSocket :默认使用系统随机分配端口号。
创建 DatagramPacket:将要发送的数据用字节数组表示,并指定要发送的数据长度,接收方的 IP 地址和端口号。
调用 该 DatagramSocket 类对象的 send 方法 :发送数据报 DatagramPacket 对象。
关闭 DatagramSocket 对象:发送端程序结束,关闭通信套接字。
接收端程序:
创建 DatagramSocket :指定监听的端口号。
创建 DatagramPacket:指定接收数据用的字节数组,起到临时数据缓冲区的效果,并指定最大可以接收的数据长度。
调用 该 DatagramSocket 类对象的 receive 方法 :接收数据报 DatagramPacket 对象。
关闭 DatagramSocket :接收端程序结束,关闭通信套接字。
URL编程
1 2 http://192.168.21.107:8080/examples/abcd.jpg?name=Tom ---> "万事万物皆对象" 应用层协议 ip地址 端口号 资源地址 参数列表
企业真题(十六) 1. TCP协议和UDP协议的区别(华**为) 略
2. 简单说说TCP协议的三次握手与四次挥手机制 (*科软) 略
反射机制 反射的概述 通过使用反射前后的例子的对比,回答:
面向对象中创建对象,调用指定结构(属性、方法)等功能,可以不使用反射,也可以使用反射。请问有什么区别?
不使用反射,我们需要考虑封装性。比如:出了Person类之后,就不能调用Person类中私有的结构
以前创建对象并调用方法的方式,与现在通过反射创建对象并调用方法的方式对比的话,哪种用的多?
从我们作为程序员开发者的角度来讲,我们开发中主要是完成业务代码,对于相关的对象、方法的调用都是确定的。
因为反射体现了动态性(可以在运行时动态的获取对象所属的类,动态的调用相关的方法),所以我们在设计框架的时候,
框架 = 注解 + 反射 + 设计模式
单例模式的饿汉式和懒汉式中,私有化类的构造器了! 此时通过反射,可以创建单例模式中类的多个对象吗?
是的!
通过反射,可以调用类中私有的结构,是否与面向对象的封装性有冲突?是不是Java语言设计存在Bug?
不存在bug!
封装性:体现的是是否建议我们调用内部api的问题。比如,private声明的结构,意味着不建议调用。
Java给我们提供了一套API,使用这套API我们可以在运行时动态的获取指定对象所属的类,创建运行时类的对象,调用指定的结构(属性、方法)等。
API:
java.lang.Class:代表一个类java.lang.reflect.Method:代表类的方法
java.lang.reflect.Field:代表类的成员变量
java.lang.reflect.Constructor:代表类的构造器
… …
反射的优点和缺点
优点:
缺点:
反射的性能较低。
反射机制主要应用在对灵活性和扩展性要求很高的系统框架上
反射会模糊程序内部逻辑,可读性较差。
反射,平时开发中,我们使用并不多。主要是在框架的底层使用。
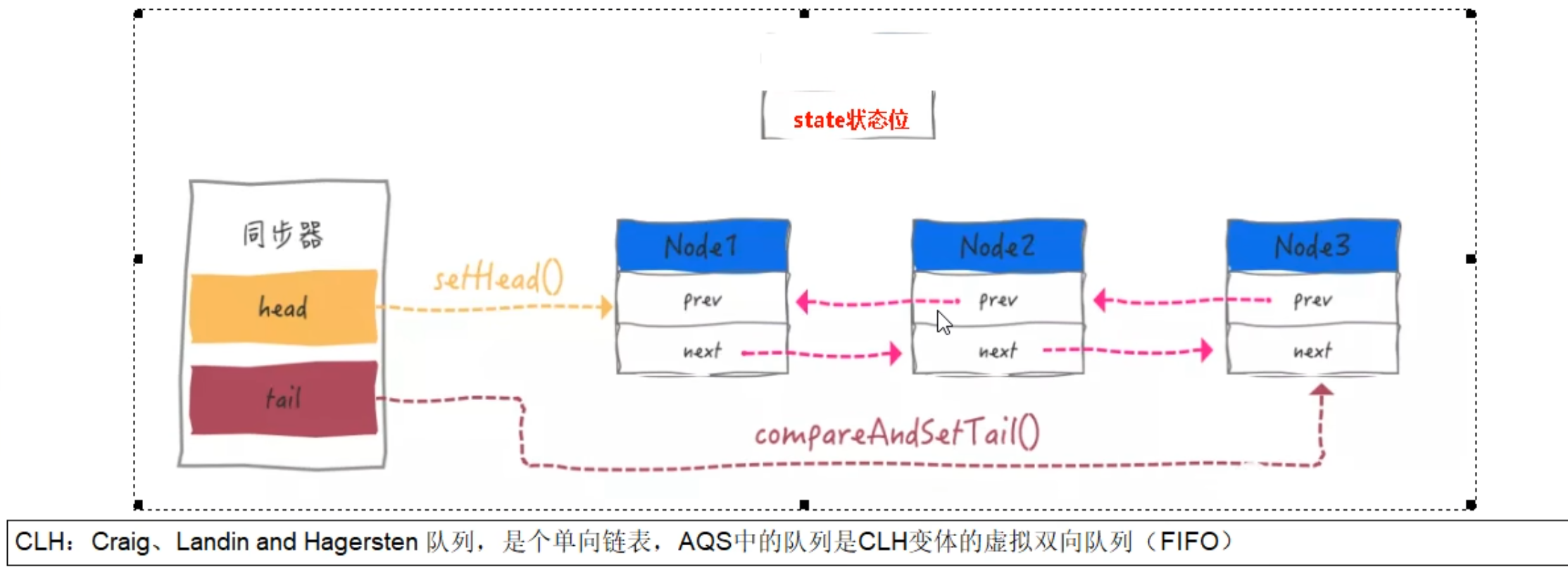
Class:反射的源头
Class的理解 (掌握)
1 2 针对于编写好的.java源文件进行编译(使用javac.exe),会生成一个或多个.class字节码文件。接着,我们使用 java.exe命令对指定的.class文件进行解释运行。这个解释运行的过程中,我们需要将.class字节码文件加载(使用类的加载器)到内存中(存放在方法区)。加载到内存中的.class文件对应的结构即为Class的一个实例。
获取Class的实例的几种方式(前三种)
类.class
对象.getClass()
(使用较多)Class调用静态方法forName(String className)
(了解)使用ClassLoader的方法loadClass(String className)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 Class clazz1 = User.class;User u1 = new User ();Class clazz2 = u1.getClass();String className = "com.atguigu02._class.User" ; Class clazz3 = Class.forName(className);System.out.println(clazz1 == clazz2); System.out.println(clazz1 == clazz3); Class clazz4 = ClassLoader.getSystemClassLoader().loadClass("com.atguigu02._class.User" );System.out.println(clazz1 == clazz4);
Class 可以指向哪些结构。
1 2 3 4 5 6 7 8 简言之,所有Java类型! (1)class:外部类,成员(成员内部类,静态内部类),局部内部类,匿名内部类 (2)interface:接口 (3)[]:数组 (4)enum:枚举 (5)annotation:注解@interface (6)primitive type:基本数据类型 (7)void
类的加载过程、类的加载器(理解)
类的加载过程
1 2 3 4 5 6 7 8 9 10 11 过程1:类的装载(loading) 将类的class文件读入内存,并为之创建一个java.lang.Class对象。此过程由类加载器完成 过程2:链接(linking) > 验证(Verify):确保加载的类信息符合JVM规范,例如:以cafebabe开头,没有安全方面的问题。 > 准备(Prepare):正式为类变量(static)分配内存并设置类变量默认初始值的阶段,这些内存都将在方法区中进行分配。 > 解析(Resolve):虚拟机常量池内的符号引用(常量名)替换为直接引用(地址)的过程。 过程3:初始化(initialization) 执行类构造器<clinit>()方法的过程。 类构造器<clinit>()方法是由编译期自动收集类中所有类变量的赋值动作和静态代码块中的语句合并产生的。
类的加载器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 作用:负责类的加载,并对应于一个Class的实例。 分类(分为两种): > BootstrapClassLoader:引导类加载器、启动类加载器 > 使用C/C++语言编写的,不能通过Java代码获取其实例 > 负责加载Java的核心库(JAVA_HOME/jre/lib/rt.jar或sun.boot.class.path路径下的内容) > 继承于ClassLoader的类加载器 > ExtensionClassLoader:扩展类加载器 > 负责加载从java.ext.dirs系统属性所指定的目录中加载类库,或从JDK的安装目录的jre/lib/ext子目录下加载类库 > SystemClassLoader/ApplicationClassLoader:系统类加载器、应用程序类加载器 > 我们自定义的类,默认使用的类的加载器。 > 用户自定义类的加载器 > 实现应用的隔离(同一个类在一个应用程序中可以加载多份);数据的加密。
使用类的加载器获取流,并读取配置文件信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Test public void test3 () throws IOException { Properties pros = new Properties (); InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("info1.properties" ); pros.load(is); String name = pros.getProperty("name" ); String pwd = pros.getProperty("password" ); System.out.println(name + ":" +pwd); }
反射的应用1:创建运行时类的对象(重点) 1 2 3 4 5 6 Class clazz = Person.class; //创建Person类的实例 Person per = (Person) clazz.newInstance(); System.out.println(per);
1 2 3 要想创建对象成功,需要满足: 条件1:要求运行时类中必须提供一个空参的构造器 条件2:要求提供的空参的构造器的权限要足够。
反射的应用2:获取运行时类所有的结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 (了解)获取运行时类的内部结构1:所有属性、所有方法、所有构造器 · getFields():获取到运行时类本身及其所有的父类中声明为public权限的属性 · getDeclaredFields():获取当前运行时类中声明的所有属性 · getMethods():获取到运行时类本身及其所有的父类中声明为public权限的方法 · getDeclaredMethods():获取当前运行时类中声明的所有方法 (熟悉)获取运行时类的内部结构2:父类、接口们、包、带泛型的父类、父类的泛型等 1. 获取运行时类的父类 getSuperclass() 2. 获取运行时类实现的接口 getInterfaces() 3. 获取运行时类所在的包 getPackage() 4. 获取运行时类的带泛型的父类 getGenericSuperclass() 5. 获取运行时类的父类的泛型 @Test public void test5() throws ClassNotFoundException { Class clazz = Class.forName("com.atguigu03.reflectapply.data.Person"); //获取带泛型的父类(Type是一个接口,Class实现了此接口 Type superclass = clazz.getGenericSuperclass(); //如果父类是带泛型的,则可以强转为ParameterizedType ParameterizedType paramType = (ParameterizedType) superclass; //调用getActualTypeArguments()获取泛型的参数,结果是一个数组,因为可能有多个泛型参数。 Type[] arguments = paramType.getActualTypeArguments(); //获取泛型参数的名称 System.out.println(((Class)arguments[0]).getName()); }
反射的应用3:调用指定的结构(重点) 1 2 3 4 5 1 调用指定的属性(步骤) 步骤1.通过Class实例调用getDeclaredField(String fieldName),获取运行时类指定名的属性 步骤2. setAccessible(true):确保此属性是可以访问的 步骤3. 通过Filed类的实例调用get(Object obj) (获取的操作) 或 set(Object obj,Object value) (设置的操作)进行操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 @Test public void test2 () throws Exception { Class clazz = Person.class; Person per = (Person) clazz.newInstance(); Field nameField = clazz.getDeclaredField("name" ); nameField.setAccessible(true ); nameField.set(per,"Tom" ); System.out.println(nameField.get(per)); }
1 2 3 4 5 6 2 调用指定的方法(步骤) 步骤1.通过Class的实例调用getDeclaredMethod(String methodName,Class ... args),获取指定的方法 步骤2. setAccessible(true):确保此方法是可访问的 步骤3.通过Method实例调用invoke(Object obj,Object ... objs),即为对Method对应的方法的调用。 invoke()的返回值即为Method对应的方法的返回值 特别的:如果Method对应的方法的返回值类型为void,则invoke()返回值为null
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Test public void test4 () throws Exception { Class clazz = Person.class; Person per = (Person) clazz.newInstance(); Method showNationMethod = clazz.getDeclaredMethod("showNation" ,String.class,int .class); showNationMethod.setAccessible(true ); Object returnValue = showNationMethod.invoke(per,"CHN" ,10 ); System.out.println(returnValue); }
1 2 3 4 3 调用指定的构造器(步骤) 步骤1.通过Class的实例调用getDeclaredConstructor(Class ... args),获取指定参数类型的构造器 步骤2.setAccessible(true):确保此构造器是可以访问的 步骤3.通过Constructor实例调用newInstance(Object ... objs),返回一个运行时类的实例。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Test public void test6 () throws Exception { Class clazz = Person.class; Constructor constructor = clazz.getDeclaredConstructor(String.class, int .class); constructor.setAccessible(true ); Person per = (Person) constructor.newInstance("Tom" , 12 ); System.out.println(per); }
反射的应用4:注解的使用(了解) 在框架中用的比较多。
体会:反射的动态性 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 public class ReflectTest { public Person getInstance () { return new Person (); } public <T> T getInstance (String className) throws Exception { Class clazz = Class.forName(className); Constructor con = clazz.getDeclaredConstructor(); con.setAccessible(true ); return (T) con.newInstance(); } @Test public void test1 () throws Exception { Person p1 = getInstance(); System.out.println(p1); String className = "com.atguigu04.other.dynamic.Person" ; Person per1 = getInstance(className); System.out.println(per1); String className1 = "java.util.Date" ; Date date1 = getInstance(className1); System.out.println(date1); } public Object invoke (String className,String methodName) throws Exception { Class clazz = Class.forName(className); Constructor con = clazz.getDeclaredConstructor(); con.setAccessible(true ); Object obj = con.newInstance(); Method method = clazz.getDeclaredMethod(methodName); method.setAccessible(true ); return method.invoke(obj); } @Test public void test2 () throws Exception { String className = "com.atguigu04.other.dynamic.Person" ; String methodName = "show" ; Object returnValue = invoke(className,methodName); System.out.println(returnValue); } }
企业真题(十七) 反射概述 1. 对反射了解吗?反射有什么好处?为什么需要反射?(微*银行) 1 2 3 4 类似问题: > Java反射的作用是什么?(三*重工、上海*和网络) > Java反射机制的作用有什么?(上海明*物联网) > 反射的具体用途?(阿***芝*信用项目组)
略
2. 反射的使用场合和作用、及其优缺点(*软国际) 1 2 3 类似问题: > 反射机制的优缺点(君*科技) > Java反射你怎么用的?(吉*航空)
略
3. 实现Java反射的类有什么?(君*科技) 1 2 类似问题: > Java反射 API 有几类?(北京*蓝)
问API。
4. 反射是怎么实现的?(上海立*网络) 从Class说起。
Class的理解 1. Class类的作用?生成Class对象的方法有哪些?(顺*) 反射的源头。 主要有三种。
2. Class.forName(“全路径”) 会调用哪些方法 ? 会调用构造方法吗?加载的类会放在哪?(上*银行外包) Class.forName() 会执行执行类构造器()方法。
不会调用构造方法
加载的类放在方法区。
类的加载 1. 类加载流程(汇**通、同*顺、凡*科技) 略
创建对象 1. 说一下创建对象的几种方法?(华油***集团、*科软、凡*科技) 1 2 类似问题: > 除了使用new创建对象之外,还可以用什么方法创建对象?(*云网络)
2. 如何找到对象实际类的?(*度) 对象.getClass();
1 2 3 Object obj = new Date(); obj.getClass();// 获取到的是Date。
3. Java反射创建对象效率高还是通过new创建对象的效率高?(三*重工) new 的方式。
调用属性、方法 1. 如何利用反射机制来访问一个类的方法?(神州**软件) 1 2 3 4 5 6 调用指定的方法(步骤) 步骤1.通过Class的实例调用getDeclaredMethod(String methodName,Class ... args),获取指定的方法 步骤2. setAccessible(true):确保此方法是可访问的 步骤3.通过Method实例调用invoke(Object obj,Object ... objs),即为对Method对应的方法的调用。 invoke()的返回值即为Method对应的方法的返回值 特别的:如果Method对应的方法的返回值类型为void,则invoke()返回值为null
2. 说一下Java反射获取私有属性,如何改变值?(阿****麻信用项目组) 1 2 3 4 5 调用指定的属性(步骤) 步骤1.通过Class实例调用getDeclaredField(String fieldName),获取运行时类指定名的属性 步骤2. setAccessible(true):确保此属性是可以访问的 步骤3. 通过Filed类的实例调用get(Object obj) (获取的操作) 或 set(Object obj,Object value) (设置的操作)进行操作。
1 针对于核心源码的api,内部的私有的结构在jdk17中就不可以通过反射调用了。
JDK8-17新特性 Java版本迭代概述
发行版本
发行时间
备注
Java 1.0
1996.01.23
Sun公司发布了Java的第一个开发工具包
Java 5.0
2004.09.30
①版本号从1.4直接更新至5.0;②平台更名为JavaSE、JavaEE、JavaME
Java 8.0
2014.03.18
此版本是继Java 5.0以来变化最大的版本。是长期支持版本(LTS)
Java 9.0
2017.09.22
此版本开始,每半年更新一次
Java 10.0
2018.03.21
Java 11.0
2018.09.25
JDK安装包取消独立JRE安装包,是长期支持版本(LTS)
Java 12.0
2019.03.19
…
…
Java17.0
2021.09
发布Java 17.0,版本号也称为21.9,是长期支持版本(LTS)
…
…
Java19.0
2022.09
发布Java19.0,版本号也称为22.9。
从Java 9 这个版本开始,Java 的计划发布周期是 6个月。
这意味着Java的更新从传统的以特性驱动的发布周期,转变为以时间驱动的发布模式,并且承诺不会跳票。通过这样的方式,开发团队可以把一些关键特性尽早合并到 JDK 之中,以快速得到开发者反馈,在一定程度上避免出现像 Java 9 两次被迫延迟发布的窘况。
针对企业客户的需求,Oracle 将以三年为周期发布长期支持版本(long term support)。
Oracle 的官方观点认为:与 Java 7->8->9 相比,Java 9->10->11的升级和 8->8u20->8u40 更相似。
新模式下的 Java 版本发布都会包含许多变更,包括语言变更和 JVM 变更,这两者都会对 IDE、字节码库和框架产生重大影响。此外,不仅会新增其他 API,还会有 API被删除(这在 Java 8 之前没有发生过)。
各版本介绍 jdk 9 Java 9 提供了超过150项新功能特性,包括备受期待的模块化系统、可交互的 REPL 工具:jshell,JDK 编译工具,Java 公共 API 和私有代码,以及安全增强、扩展提升、性能管理改善等。
特性太多,查看链接:
https://openjdk.java.net/projects/jdk9/
jdk 10 https://openjdk.java.net/projects/jdk/10/
286: Local-Variable Type Inference 局部变量类型推断Consolidate the JDK Forest into a Single Repository JDK库的合并Garbage-Collector Interface 统一的垃圾回收接口Parallel Full GC for G1 为G1提供并行的Full GCApplication Class-Data Sharing 应用程序类数据(AppCDS)共享Thread-Local Handshakes ThreadLocal握手交互Remove the Native-Header Generation Tool (javah) 移除JDK中附带的javah工具Additional Unicode Language-Tag Extensions 使用附加的Unicode语言标记扩展Heap Allocation on Alternative Memory Devices 能将堆内存占用分配给用户指定的备用内存设备Experimental Java-Based JIT Compiler 使用Graal基于Java的编译器
319: Root Certificates 根证书Time-Based Release Versioning 基于时间定于的发布版本
jdk 11 https://openjdk.java.net/projects/jdk/11/
181: Nest-Based Access Control 基于嵌套的访问控制Dynamic Class-File Constants 动态类文件常量Improve Aarch64 Intrinsics 改进 Aarch64 IntrinsicsEpsilon: A No-Op Garbage Collector Epsilon — 一个No-Op(无操作)的垃圾收集器Remove the Java EE and CORBA Modules 删除 Java EE 和 CORBA 模块HTTP Client (Standard) HTTPClient APILocal-Variable Syntax for Lambda Parameters 用于 Lambda 参数的局部变量语法Key Agreement with Curve25519 and Curve448 Curve25519 和 Curve448 算法的密钥协议Unicode 10 Flight Recorder 飞行记录仪ChaCha20 and Poly1305 Cryptographic Algorithms ChaCha20 和 Poly1305 加密算法Launch Single-File Source-Code Programs 启动单一文件的源代码程序Low-Overhead Heap Profiling 低开销的 Heap ProfilingTransport Layer Security (TLS) 1.3 支持 TLS 1.3ZGC: A Scalable Low-Latency Garbage Collector 可伸缩低延迟垃圾收集器Deprecate the Nashorn JavaScript Engine 弃用 Nashorn JavaScript 引擎Deprecate the Pack200 Tools and API 弃用 Pack200 工具和 API
jdk 12 https://openjdk.java.net/projects/jdk/12/
189:Shenandoah: A Low-Pause-Time Garbage Collector (Experimental) 低暂停时间的GCMicrobenchmark Suite 微基准测试套件Switch Expressions (Preview) switch表达式JVM Constants API JVM常量APIOne AArch64 Port, Not Two 只保留一个AArch64实现Default CDS Archives 默认类数据共享归档文件Abortable Mixed Collections for G1 可中止的G1 Mixed GCPromptly Return Unused Committed Memory from G1 G1及时返回未使用的已分配内存
jdk 13 https://openjdk.java.net/projects/jdk/13/
350: Dynamic CDS Archives 动态CDS档案ZGC: Uncommit Unused Memory ZGC:取消使用未使用的内存Reimplement the Legacy Socket API 重新实现旧版套接字APISwitch Expressions (Preview) switch表达式(预览)Text Blocks (Preview) 文本块(预览)
jdk 14 https://openjdk.java.net/projects/jdk/14/
305: Pattern Matching for instanceof (Preview) instanceof的模式匹配Packaging Tool (Incubator) 打包工具NUMA-Aware Memory Allocation for G1 G1的NUMA-Aware内存分配JFR Event Streaming JFR事件流Non-Volatile Mapped Byte Buffers 非易失性映射字节缓冲区Helpful NullPointerExceptions 实用的NullPointerExceptionsRecords (Preview) Switch Expressions (Standard) Switch表达式Deprecate the Solaris and SPARC Ports 弃用Solaris和SPARC端口Remove the Concurrent Mark Sweep (CMS) Garbage Collector 删除并发标记扫描(CMS)垃圾回收器ZGC on macOS ZGC on Windows Deprecate the ParallelScavenge + SerialOld GC Combination 弃用ParallelScavenge + SerialOld GC组合Remove the Pack200 Tools and API 删除Pack200工具和APIText Blocks (Second Preview) 文本块Foreign-Memory Access API (Incubator) 外部存储器访问API
jdk 15 https://openjdk.java.net/projects/jdk/15/
339: Edwards-Curve Digital Signature Algorithm (EdDSA) EdDSA 数字签名算法Sealed Classes (Preview) 密封类(预览)Hidden Classes 隐藏类Remove the Nashorn JavaScript Engine 移除 Nashorn JavaScript 引擎Reimplement the Legacy DatagramSocket API 重新实现 Legacy DatagramSocket APIDisable and Deprecate Biased Locking 禁用偏向锁定Pattern Matching for instanceof (Second Preview) instanceof 模式匹配(第二次预览)ZGC: A Scalable Low-Latency Garbage Collector ZGC:一个可扩展的低延迟垃圾收集器Text Blocks 文本块Shenandoah: A Low-Pause-Time Garbage Collector Shenandoah:低暂停时间垃圾收集器Remove the Solaris and SPARC Ports 移除 Solaris 和 SPARC 端口Foreign-Memory Access API (Second Incubator) 外部存储器访问 API(第二次孵化版)Records (Second Preview) Records(第二次预览)Deprecate RMI Activation for Removal 废弃 RMI 激活机制
jdk 16 https://openjdk.java.net/projects/jdk/16/
338: Vector API (Incubator) Vector API(孵化器)Enable C++14 Language Features JDK C++的源码中允许使用C++14的语言特性Migrate from Mercurial to Git OpenJDK源码的版本控制从Mercurial (hg) 迁移到gitMigrate to GitHub OpenJDK源码的版本控制迁移到github上ZGC: Concurrent Thread-Stack Processing ZGC:并发线程处理Unix-Domain Socket Channels Unix域套接字通道Alpine Linux Port 将glibc的jdk移植到使用musl的alpine linux上Elastic Metaspace 弹性元空间Windows/AArch64 Port 移植JDK到Windows/AArch64Foreign Linker API (Incubator) 提供jdk.incubator.foreign来简化native code的调用Warnings for Value-Based Classes 提供基于值的类的警告Packaging Tool jpackage打包工具转正Foreign-Memory Access API (Third Incubator) Pattern Matching for instanceof Instanceof的模式匹配转正Records Records转正Strongly Encapsulate JDK Internals by Default 默认情况下,封装了JDK内部构件Sealed Classes (Second Preview) 密封类
jdk 17 https://openjdk.java.net/projects/jdk/17/
306: Restore Always-Strict Floating-Point Semantics 恢复始终严格的浮点语义
356: Enhanced Pseudo-Random Number Generators 增强型伪随机数生成器
382: New macOS Rendering Pipeline 新的macOS渲染管道
391: macOS/AArch64 Port macOS/AArch64端口
398: Deprecate the Applet API for Removal 弃用Applet API后续将进行删除
403: Strongly Encapsulate JDK Internals 强封装JDK的内部API
406: Pattern Matching for switch (Preview) switch模式匹配(预览)
407: Remove RMI Activation 删除RMI激活机制
409: Sealed Classes 密封类转正
410: Remove the Experimental AOT and JIT Compiler 删除实验性的AOT和JIT编译器
411: Deprecate the Security Manager for Removal 弃用即将删除的安全管理器
412: Foreign Function & Memory API (Incubator) 外部函数和内存API(孵化特性)
414: Vector API (Second Incubator) Vector API(第二次孵化特性)
415: Context-Specific Deserialization Filters 上下文特定的反序列化过滤器
Java8新特性:Lambda表达式 场景 冗余的匿名内部类 :java.lang.Runnable接口来定义任务内容,并使用java.lang.Thread类来启动该线程。代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 package com.atguigu.fp;public class UseFunctionalProgramming { public static void main (String[] args) { new Thread (new Runnable () { @Override public void run () { System.out.println("多线程任务执行!" ); } }).start(); } }
本着“一切皆对象”的思想,这种做法是无可厚非的:首先创建一个Runnable接口的匿名内部类对象来指定任务内容,再将其交给一个线程来启动。
代码分析:
对于Runnable的匿名内部类用法,可以分析出几点内容:
Thread类需要Runnable接口作为参数,其中的抽象run方法是用来指定线程任务内容的核心;为了指定run的方法体,不得不 需要Runnable接口的实现类;
为了省去定义一个RunnableImpl实现类的麻烦,不得不 使用匿名内部类;
必须覆盖重写抽象run方法,所以方法名称、方法参数、方法返回值不得不 再写一遍,且不能写错;
而实际上,似乎只有方法体才是关键所在 。
Lambda 及其语法 Lambda 是一个匿名函数 ,我们可以把 Lambda 表达式理解为是一段可以传递的代码 (将代码像数据一样进行传递)。使用它可以写出更简洁、更灵活的代码。作为一种更紧凑的代码风格,使Java的语言表达能力得到了提升
Lambda 表达式:在Java 8 语言中引入的一种新的语法元素和操作符。这个操作符为 “->” , 该操作符被称为 Lambda 操作符或箭头操作符。它将 Lambda 分为两个部分:
左侧:指定了 Lambda 表达式需要的参数列表
右侧:指定了 Lambda 体,是抽象方法的实现逻辑,也即 Lambda 表达式要执行的功能。
语法格式一: 无参,无返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 @Test public void test1 () { Runnable r1 = new Runnable () { @Override public void run () { System.out.println("我爱北京天安门" ); } }; r1.run(); System.out.println("***********************" ); Runnable r2 = () -> { System.out.println("我爱北京故宫" ); }; r2.run(); }
语法格式二: Lambda 需要一个参数,但是没有返回值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 @Test public void test2 () { Consumer<String> con = new Consumer <String>() { @Override public void accept (String s) { System.out.println(s); } }; con.accept("谎言和誓言的区别是什么?" ); System.out.println("*******************" ); Consumer<String> con1 = (String s) -> { System.out.println(s); }; con1.accept("一个是听得人当真了,一个是说的人当真了" ); }
语法格式三: 数据类型可以省略,因为可由编译器推断得出,称为“类型推断”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 @Test public void test3 () { Consumer<String> con1 = (String s) -> { System.out.println(s); }; con1.accept("一个是听得人当真了,一个是说的人当真了" ); System.out.println("*******************" ); Consumer<String> con2 = (s) -> { System.out.println(s); }; con2.accept("一个是听得人当真了,一个是说的人当真了" ); }
语法格式四: Lambda 若只需要一个参数时,参数的小括号可以省略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 @Test public void test4 () { Consumer<String> con1 = (s) -> { System.out.println(s); }; con1.accept("一个是听得人当真了,一个是说的人当真了" ); System.out.println("*******************" ); Consumer<String> con2 = s -> { System.out.println(s); }; con2.accept("一个是听得人当真了,一个是说的人当真了" ); }
语法格式五: Lambda 需要两个或以上的参数,多条执行语句,并且可以有返回值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 @Test public void test5 () { Comparator<Integer> com1 = new Comparator <Integer>() { @Override public int compare (Integer o1, Integer o2) { System.out.println(o1); System.out.println(o2); return o1.compareTo(o2); } }; System.out.println(com1.compare(12 ,21 )); System.out.println("*****************************" ); Comparator<Integer> com2 = (o1,o2) -> { System.out.println(o1); System.out.println(o2); return o1.compareTo(o2); }; System.out.println(com2.compare(12 ,6 )); }
语法格式六: 当 Lambda 体只有一条语句时,return 与大括号若有,都可以省略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 @Test public void test6 () { Comparator<Integer> com1 = (o1,o2) -> { return o1.compareTo(o2); }; System.out.println(com1.compare(12 ,6 )); System.out.println("*****************************" ); Comparator<Integer> com2 = (o1,o2) -> o1.compareTo(o2); System.out.println(com2.compare(12 ,21 )); } @Test public void test7 () { Consumer<String> con1 = s -> { System.out.println(s); }; con1.accept("一个是听得人当真了,一个是说的人当真了" ); System.out.println("*****************************" ); Consumer<String> con2 = s -> System.out.println(s); con2.accept("一个是听得人当真了,一个是说的人当真了" ); }
Java8新特性:函数式(Functional)接口 什么是函数式接口
只包含一个抽象方法(Single Abstract Method,简称SAM)的接口,称为函数式接口。当然该接口可以包含其他非抽象方法。
你可以通过 Lambda 表达式来创建该接口的对象。(若 Lambda 表达式抛出一个受检异常(即:非运行时异常),那么该异常需要在目标接口的抽象方法上进行声明)。
我们可以在一个接口上使用 @FunctionalInterface 注解,这样做可以检查它是否是一个函数式接口。同时 javadoc 也会包含一条声明,说明这个接口是一个函数式接口。
在java.util.function包下定义了Java 8 的丰富的函数式接口
如何理解函数式接口
简单的说,在Java8中,Lambda表达式就是一个函数式接口的实例。这就是Lambda表达式和函数式接口的关系。也就是说,只要一个对象是函数式接口的实例,那么该对象就可以用Lambda表达式来表示。
Java 内置函数式接口
java.lang.Runnable
java.lang.Iterable
public Iterator iterate()
java.lang.Comparable
public int compareTo(T t)
java.util.Comparator
public int compare(T t1, T t2)
函数式接口
称谓
参数类型
用途
Consumer<T> 消费型接口
T
对类型为T的对象应用操作,包含方法: void accept(T t)
Supplier<T> 供给型接口
无
返回类型为T的对象,包含方法:T get()
Function<T, R> 函数型接口
T
对类型为T的对象应用操作,并返回结果。结果是R类型的对象。包含方法:R apply(T t)
Predicate<T> 判断型接口
T
确定类型为T的对象是否满足某约束,并返回 boolean 值。包含方法:boolean test(T t)
其他接口:
类型1:消费型接口
消费型接口的抽象方法特点:有形参,但是返回值类型是void
接口名
抽象方法
描述
BiConsumer<T,U>
void accept(T t, U u)
接收两个对象用于完成功能
DoubleConsumer
void accept(double value)
接收一个double值
IntConsumer
void accept(int value)
接收一个int值
LongConsumer
void accept(long value)
接收一个long值
ObjDoubleConsumer
void accept(T t, double value)
接收一个对象和一个double值
ObjIntConsumer
void accept(T t, int value)
接收一个对象和一个int值
ObjLongConsumer
void accept(T t, long value)
接收一个对象和一个long值
类型2:供给型接口
这类接口的抽象方法特点:无参,但是有返回值
接口名
抽象方法
描述
BooleanSupplier
boolean getAsBoolean()
返回一个boolean值
DoubleSupplier
double getAsDouble()
返回一个double值
IntSupplier
int getAsInt()
返回一个int值
LongSupplier
long getAsLong()
返回一个long值
类型3:函数型接口
这类接口的抽象方法特点:既有参数又有返回值
接口名
抽象方法
描述
UnaryOperator
T apply(T t)
接收一个T类型对象,返回一个T类型对象结果
DoubleFunction
R apply(double value)
接收一个double值,返回一个R类型对象
IntFunction
R apply(int value)
接收一个int值,返回一个R类型对象
LongFunction
R apply(long value)
接收一个long值,返回一个R类型对象
ToDoubleFunction
double applyAsDouble(T value)
接收一个T类型对象,返回一个double
ToIntFunction
int applyAsInt(T value)
接收一个T类型对象,返回一个int
ToLongFunction
long applyAsLong(T value)
接收一个T类型对象,返回一个long
DoubleToIntFunction
int applyAsInt(double value)
接收一个double值,返回一个int结果
DoubleToLongFunction
long applyAsLong(double value)
接收一个double值,返回一个long结果
IntToDoubleFunction
double applyAsDouble(int value)
接收一个int值,返回一个double结果
IntToLongFunction
long applyAsLong(int value)
接收一个int值,返回一个long结果
LongToDoubleFunction
double applyAsDouble(long value)
接收一个long值,返回一个double结果
LongToIntFunction
int applyAsInt(long value)
接收一个long值,返回一个int结果
DoubleUnaryOperator
double applyAsDouble(double operand)
接收一个double值,返回一个double
IntUnaryOperator
int applyAsInt(int operand)
接收一个int值,返回一个int结果
LongUnaryOperator
long applyAsLong(long operand)
接收一个long值,返回一个long结果
BiFunction<T,U,R>
R apply(T t, U u)
接收一个T类型和一个U类型对象,返回一个R类型对象结果
BinaryOperator
T apply(T t, T u)
接收两个T类型对象,返回一个T类型对象结果
ToDoubleBiFunction<T,U>
double applyAsDouble(T t, U u)
接收一个T类型和一个U类型对象,返回一个double
ToIntBiFunction<T,U>
int applyAsInt(T t, U u)
接收一个T类型和一个U类型对象,返回一个int
ToLongBiFunction<T,U>
long applyAsLong(T t, U u)
接收一个T类型和一个U类型对象,返回一个long
DoubleBinaryOperator
double applyAsDouble(double left, double right)
接收两个double值,返回一个double结果
IntBinaryOperator
int applyAsInt(int left, int right)
接收两个int值,返回一个int结果
LongBinaryOperator
long applyAsLong(long left, long right)
接收两个long值,返回一个long结果
类型4:判断型接口
这类接口的抽象方法特点:有参,但是返回值类型是boolean结果。
接口名
抽象方法
描述
BiPredicate<T,U>
boolean test(T t, U u)
接收两个对象
DoublePredicate
boolean test(double value)
接收一个double值
IntPredicate
boolean test(int value)
接收一个int值
LongPredicate
boolean test(long value)
接收一个long值
练习 练习1:无参无返回值形式
假如有自定义函数式接口Call如下:
1 2 3 public interface Call { void shout () ; }
在测试类中声明一个如下方法:
1 2 3 public static void callSomething (Call call) { call.shout(); }
在测试类的main方法中调用callSomething方法,并用Lambda表达式为形参call赋值,可以喊出任意你想说的话。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class TestLambda { public static void main (String[] args) { callSomething(()->System.out.println("回家吃饭" )); callSomething(()->System.out.println("我爱你" )); callSomething(()->System.out.println("滚蛋" )); callSomething(()->System.out.println("回来" )); } public static void callSomething (Call call) { call.shout(); } } interface Call { void shout () ; }
练习2:消费型接口
代码示例:Consumer接口
在JDK1.8中Collection集合接口的父接口Iterable接口中增加了一个默认方法:
public default void forEach(Consumer<? super T> action) 遍历Collection集合的每个元素,执行“xxx消费型”操作。
在JDK1.8中Map集合接口中增加了一个默认方法:
public default void forEach(BiConsumer<? super K,? super V> action)遍历Map集合的每对映射关系,执行“xxx消费型”操作。
案例:
(1)创建一个Collection系列的集合,添加一些字符串,调用forEach方法遍历查看
(2)创建一个Map系列的集合,添加一些(key,value)键值对,调用forEach方法遍历查看
示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 @Test public void test1 () { List<String> list = Arrays.asList("hello" ,"java" ,"lambda" ,"atguigu" ); list.forEach(s -> System.out.println(s)); } @Test public void test2 () { HashMap<Integer,String> map = new HashMap <>(); map.put(1 , "hello" ); map.put(2 , "java" ); map.put(3 , "lambda" ); map.put(4 , "atguigu" ); map.forEach((k,v) -> System.out.println(k+"->" +v)); }
练习3:供给型接口
代码示例:Supplier接口
在JDK1.8中增加了StreamAPI,java.util.stream.Stream是一个数据流。这个类型有一个静态方法:
public static <T> Stream<T> generate(Supplier<T> s)可以创建Stream的对象。而又包含一个forEach方法可以遍历流中的元素:public void forEach(Consumer<? super T> action)。
案例:
现在请调用Stream的generate方法,来产生一个流对象,并调用Math.random()方法来产生数据,为Supplier函数式接口的形参赋值。最后调用forEach方法遍历流中的数据查看结果。
1 2 3 4 @Test public void test2 () { Stream.generate(() -> Math.random()).forEach(num -> System.out.println(num)); }
练习4:功能型接口
代码示例:Function<T,R>接口
在JDK1.8时Map接口增加了很多方法,例如:
public default void replaceAll(BiFunction<? super K,? super V,? extends V> function) 按照function指定的操作替换map中的value。
public default void forEach(BiConsumer<? super K,? super V> action)遍历Map集合的每对映射关系,执行“xxx消费型”操作。
案例:
(1)声明一个Employee员工类型,包含编号、姓名、薪资。
(2)添加n个员工对象到一个HashMap<Integer,Employee>集合中,其中员工编号为key,员工对象为value。
(3)调用Map的forEach遍历集合
(4)调用Map的replaceAll方法,将其中薪资低于10000元的,薪资设置为10000。
(5)再次调用Map的forEach遍历集合查看结果
Employee类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 class Employee { private int id; private String name; private double salary; public Employee (int id, String name, double salary) { super (); this .id = id; this .name = name; this .salary = salary; } public Employee () { super (); } public int getId () { return id; } public void setId (int id) { this .id = id; } public String getName () { return name; } public void setName (String name) { this .name = name; } public double getSalary () { return salary; } public void setSalary (double salary) { this .salary = salary; } @Override public String toString () { return "Employee [id=" + id + ", name=" + name + ", salary=" + salary + "]" ; } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import java.util.HashMap;public class TestLambda { public static void main (String[] args) { HashMap<Integer,Employee> map = new HashMap <>(); Employee e1 = new Employee (1 , "张三" , 8000 ); Employee e2 = new Employee (2 , "李四" , 9000 ); Employee e3 = new Employee (3 , "王五" , 10000 ); Employee e4 = new Employee (4 , "赵六" , 11000 ); Employee e5 = new Employee (5 , "钱七" , 12000 ); map.put(e1.getId(), e1); map.put(e2.getId(), e2); map.put(e3.getId(), e3); map.put(e4.getId(), e4); map.put(e5.getId(), e5); map.forEach((k,v) -> System.out.println(k+"=" +v)); System.out.println(); map.replaceAll((k,v)->{ if (v.getSalary()<10000 ){ v.setSalary(10000 ); } return v; }); map.forEach((k,v) -> System.out.println(k+"=" +v)); } }
练习5:判断型接口
代码示例:Predicate接口
JDK1.8时,Collecton接口增加了一下方法,其中一个如下:
public default boolean removeIf(Predicate<? super E> filter) 用于删除集合中满足filter指定的条件判断的。
public default void forEach(Consumer<? super T> action) 遍历Collection集合的每个元素,执行“xxx消费型”操作。
案例:
(1)添加一些字符串到一个Collection集合中
(2)调用forEach遍历集合
(3)调用removeIf方法,删除其中字符串的长度<5的
(4)再次调用forEach遍历集合
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import java.util.ArrayList;public class TestLambda { public static void main (String[] args) { ArrayList<String> list = new ArrayList <>(); list.add("hello" ); list.add("java" ); list.add("atguigu" ); list.add("ok" ); list.add("yes" ); list.forEach(str->System.out.println(str)); System.out.println(); list.removeIf(str->str.length()<5 ); list.forEach(str->System.out.println(str)); } }
练习6:判断型接口
案例:
(1)声明一个Employee员工类型,包含编号、姓名、性别,年龄,薪资。
(2)声明一个EmployeeSerice员工管理类,包含一个ArrayList集合的属性all,在EmployeeSerice的构造器中,创建一些员工对象,为all集合初始化。
(3)在EmployeeSerice员工管理类中,声明一个方法:ArrayList get(Predicate p),即将满足p指定的条件的员工,添加到一个新的ArrayList 集合中返回。
(4)在测试类中创建EmployeeSerice员工管理类的对象,并调用get方法,分别获取:
所有员工对象
所有年龄超过35的员工
所有薪资高于15000的女员工
所有编号是偶数的员工
名字是“张三”的员工
年龄超过25,薪资低于10000的男员工
示例代码:
Employee类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class Employee { private int id; private String name; private char gender; private int age; private double salary; public Employee (int id, String name, char gender, int age, double salary) { super (); this .id = id; this .name = name; this .gender = gender; this .age = age; this .salary = salary; } public Employee () { super (); } public int getId () { return id; } public void setId (int id) { this .id = id; } public String getName () { return name; } public void setName (String name) { this .name = name; } public double getSalary () { return salary; } public void setSalary (double salary) { this .salary = salary; } @Override public String toString () { return "Employee [id=" + id + ", name=" + name + ", gender=" + gender + ", age=" + age + ", salary=" + salary + "]" ; } }
员工管理类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 class EmployeeService { private ArrayList<Employee> all; public EmployeeService () { all = new ArrayList <Employee>(); all.add(new Employee (1 , "张三" , '男' , 33 , 8000 )); all.add(new Employee (2 , "翠花" , '女' , 23 , 18000 )); all.add(new Employee (3 , "无能" , '男' , 46 , 8000 )); all.add(new Employee (4 , "李四" , '女' , 23 , 9000 )); all.add(new Employee (5 , "老王" , '男' , 23 , 15000 )); all.add(new Employee (6 , "大嘴" , '男' , 23 , 11000 )); } public ArrayList<Employee> get (Predicate<Employee> p) { ArrayList<Employee> result = new ArrayList <Employee>(); for (Employee emp : result) { if (p.test(emp)){ result.add(emp); } } return result; } }
测试类:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public class TestLambda { public static void main (String[] args) { EmployeeService es = new EmployeeService (); es.get(e -> true ).forEach(e->System.out.println(e)); System.out.println(); es.get(e -> e.getAge()>35 ).forEach(e->System.out.println(e)); System.out.println(); es.get(e -> e.getSalary()>15000 && e.getGender()=='女' ).forEach(e->System.out.println(e)); System.out.println(); es.get(e -> e.getId()%2 ==0 ).forEach(e->System.out.println(e)); System.out.println(); es.get(e -> "张三" .equals(e.getName())).forEach(e->System.out.println(e)); System.out.println(); es.get(e -> e.getAge()>25 && e.getSalary()<10000 && e.getGender()=='男' ).forEach(e->System.out.println(e)); } }
Java8新特性:方法引用与构造器引用 方法引用 当要传递给Lambda体的操作,已经有实现的方法了,可以使用方法引用!
方法引用可以看做是Lambda表达式深层次的表达。换句话说,方法引用就是Lambda表达式,也就是函数式接口的一个实例,通过方法的名字来指向一个方法,可以认为是Lambda表达式的一个语法糖。
语法糖(Syntactic sugar),也译为糖衣语法,是由英国计算机科学家彼得·约翰·兰达(Peter J. Landin)发明的一个术语,指计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。通常来说使用语法糖能够增加程序的可读性,从而减少程序代码出错的机会。
方法引用格式
方法引用使用前提 要求1: Lambda体只有一句语句,并且是通过调用一个对象的/类现有的方法来完成的
例如:System.out对象,调用println()方法来完成Lambda体
Math类,调用random()静态方法来完成Lambda体
要求2:
针对情况1:函数式接口中的抽象方法a在被重写时使用了某一个对象的方法b。如果方法a的形参列表、返回值类型与方法b的形参列表、返回值类型都相同,则我们可以使用方法b实现对方法a的重写、替换。 对象 :: 实例方法
1 2 3 4 5 6 7 Consumer<String> con1 = str -> System.out.println(str); Consumer<String> con2 = System.out::println; Supplier<String> sup1 = () -> emp.getName(); Supplier<String> sup2 = emp::getName;
针对情况2:函数式接口中的抽象方法a在被重写时使用了某一个类的静态方法b。如果方法a的形参列表、返回值类型与方法b的形参列表、返回值类型都相同,则我们可以使用方法b实现对方法a的重写、替换。 类 :: 静态方法
1 2 3 4 5 6 7 Comparator<Integer> com1 = (t1,t2) -> Integer.compare(t1,t2); Comparator<Integer> com2 = Integer::compare; Function<Double,Long> func1 = d -> Math.round(d); Function<Double,Long> func2 = Math::round;
针对情况3:函数式接口中的抽象方法a在被重写时使用了某一个对象的方法b。如果方法a的返回值类型与方法b的返回值类型相同,同时方法a的形参列表中有n个参数,方法b的形参列表有n-1个参数,且方法a的第1个参数作为方法b的调用者,且方法a的后n-1参数与方法b的n-1参数匹配(类型相同或满足多态场景也可以) 类 :: 实例方法
1 2 3 4 5 6 7 8 9 10 11 Comparator<String> com1 = (s1,s2) -> s1.compareTo(s2); Comparator<String> com2 = String :: compareTo; BiPredicate<String,String> pre1 = (s1,s2) -> s1.equals(s2); BiPredicate<String,String> pre2 = String :: equals; Function<Employee,String> func1 = e -> e.getName(); Function<Employee,String> func2 = Employee::getName;
构造器引用 当Lambda表达式是创建一个对象,并且满足Lambda表达式形参,正好是给创建这个对象的构造器的实参列表,就可以使用构造器引用。
格式:类名::new
1 2 3 4 5 6 7 8 9 10 11 12 Supplier<Employee> sup = new Supplier <Employee>() { @Override public Employee get () { return new Employee (); } }; Supplier<Employee> sup1 = () -> new Employee (); Supplier<Employee> sup2 = Employee :: new ;
数组构造引用 当Lambda表达式是创建一个数组对象,并且满足Lambda表达式形参,正好是给创建这个数组对象的长度,就可以数组构造引用。
格式:数组类型名::new
1 2 Function<Integer,String[]> func1 = length -> new String [length]; Function<Integer,String[]> func2 = String[] :: new ;
Java8新特性:强大的Stream API 概述
Stream API ( java.util.stream) 把真正的函数式编程风格引入到Java中。这是目前为止对Java类库最好的补充,因为Stream API可以极大提供Java程序员的生产力,让程序员写出高效率、干净、简洁的代码。
Stream 是 Java8 中处理集合的关键抽象概念,它可以指定你希望对集合进行的操作,可以执行非常复杂的查找、过滤和映射数据等操作。 使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。 也可以使用 Stream API 来并行执行操作。简言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
为什么要使用Stream API :实际开发中,项目中多数数据源都来自于MySQL、Oracle等。但现在数据源可以更多了,有MongDB,Radis等,而这些NoSQL的数据就需要Java层面去处理。
什么是Stream :
Stream 和 Collection 集合的区别:Collection 是一种静态的内存数据结构,讲的是数据,而 Stream 是有关计算的,讲的是计算。 前者是主要面向内存,存储在内存中,后者主要是面向 CPU,通过 CPU 实现计算。
注意:
①Stream 自己不会存储元素。
②Stream 不会改变源对象。相反,他们会返回一个持有结果的新Stream。
③Stream 操作是延迟执行的。这意味着他们会等到需要结果的时候才执行。即一旦执行终止操作,就执行中间操作链,并产生结果。
④ Stream一旦执行了终止操作,就不能再调用其它中间操作或终止操作了。
Stream的操作三个步骤 1- 创建 Stream
2- 中间操作 操作链,可对数据源的数据进行n次处理,但是在终结操作前,并不会真正执行。
3- 终止操作(终端操作)
创建Stream实例 方式一:通过集合
Java8 中的 Collection 接口被扩展,提供了两个获取流的方法:
1 2 3 4 5 6 7 @Test public void test01 () { List<Integer> list = Arrays.asList(1 ,2 ,3 ,4 ,5 ); Stream<Integer> stream = list.stream(); }
方式二:通过数组
Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
static Stream stream(T[] array): 返回一个流
public static IntStream stream(int[] array)
public static LongStream stream(long[] array)
public static DoubleStream stream(double[] array)
1 2 3 4 5 6 7 8 9 10 11 @Test public void test02 () { String[] arr = {"hello" ,"world" }; Stream<String> stream = Arrays.stream(arr); } @Test public void test03 () { int [] arr = {1 ,2 ,3 ,4 ,5 }; IntStream stream = Arrays.stream(arr); }
方式三:通过Stream的of()
可以调用Stream类静态方法 of(), 通过显示值创建一个流。它可以接收任意数量的参数。
public static Stream of(T… values) : 返回一个流
1 2 3 4 5 @Test public void test04 () { Stream<Integer> stream = Stream.of(1 ,2 ,3 ,4 ,5 ); stream.forEach(System.out::println); }
方式四:创建无限流(了解)
可以使用静态方法 Stream.iterate() 和 Stream.generate(), 创建无限流。
迭代 Stream iterate(final T seed, final UnaryOperator f)
生成 Stream generate(Supplier s)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 @Test public void test05 () { Stream<Integer> stream = Stream.iterate(0 , x -> x + 2 ); stream.limit(10 ).forEach(System.out::println); Stream<Double> stream1 = Stream.generate(Math::random); stream1.limit(10 ).forEach(System.out::println); }
一系列中间操作 多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何的处理!而在终止操作时一次性全部处理,称为“惰性求值”。
1-筛选与切片
方 法 描 述
filter(Predicatep) 接收 Lambda , 从流中排除某些元素
distinct() 筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素
limit(long maxSize) 截断流,使其元素不超过给定数量
skip(long n) 跳过元素,返回一个扔掉了前 n 个元素的流。
2-映 射
方法 描述
map(Function f) 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
mapToDouble(ToDoubleFunction f) 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。
mapToInt(ToIntFunction f) 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream。
mapToLong(ToLongFunction f) 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。
flatMap(Function f) 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流
3-排序
方法 描述
sorted() 产生一个新流,其中按自然顺序排序
sorted(Comparator com) 产生一个新流,其中按比较器顺序排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 public class StreamMiddleOperate { @Test public void test01 () { Stream<Integer> stream = Stream.of(1 ,2 ,3 ,4 ,5 ,6 ); stream = stream.filter(t -> t%2 ==0 ); stream.forEach(System.out::println); } @Test public void test02 () { Stream.of(1 ,2 ,3 ,4 ,5 ,6 ) .filter(t -> t%2 ==0 ) .forEach(System.out::println); } @Test public void test03 () { Stream.of(1 ,2 ,3 ,4 ,5 ,6 ,2 ,2 ,3 ,3 ,4 ,4 ,5 ) .distinct() .forEach(System.out::println); } @Test public void test04 () { Stream.of(1 ,2 ,3 ,4 ,5 ,6 ,2 ,2 ,3 ,3 ,4 ,4 ,5 ) .limit(3 ) .forEach(System.out::println); } @Test public void test05 () { Stream.of(1 ,2 ,2 ,3 ,3 ,4 ,4 ,5 ,2 ,3 ,4 ,5 ,6 ,7 ) .distinct() .filter(t -> t%2 !=0 ) .limit(3 ) .forEach(System.out::println); } @Test public void test06 () { Stream.of(1 ,2 ,3 ,4 ,5 ,6 ,2 ,2 ,3 ,3 ,4 ,4 ,5 ) .skip(5 ) .forEach(System.out::println); } @Test public void test07 () { Stream.of(1 ,2 ,3 ,4 ,5 ,6 ,2 ,2 ,3 ,3 ,4 ,4 ,5 ) .skip(5 ) .distinct() .filter(t -> t%3 ==0 ) .forEach(System.out::println); } @Test public void test08 () { long count = Stream.of(1 ,2 ,3 ,4 ,5 ,6 ,2 ,2 ,3 ,3 ,4 ,4 ,5 ) .distinct() .peek(System.out::println) .count(); System.out.println("count=" +count); } @Test public void test09 () { Stream.of(11 ,2 ,39 ,4 ,54 ,6 ,2 ,22 ,3 ,3 ,4 ,54 ,54 ) .distinct() .sorted((t1,t2) -> -Integer.compare(t1, t2)) .limit(3 ) .forEach(System.out::println); } @Test public void test10 () { Stream.of(1 ,2 ,3 ,4 ,5 ) .map(t -> t+=1 ) .forEach(System.out::println); } @Test public void test11 () { String[] arr = {"hello" ,"world" ,"java" }; Arrays.stream(arr) .map(t->t.toUpperCase()) .forEach(System.out::println); } @Test public void test12 () { String[] arr = {"hello" ,"world" ,"java" }; Arrays.stream(arr) .flatMap(t -> Stream.of(t.split("|" ))) .forEach(System.out::println); } }
终止操作 终端操作会从流的流水线生成结果。其结果可以是任何不是流的值,例如:List、Integer,甚至是 void 。
1-匹配与查找
方法 描述
allMatch(Predicate p) 检查是否匹配所有元素
anyMatch(Predicate p) 检查是否至少匹配一个元素
noneMatch(Predicate p) 检查是否没有匹配所有元素
findFirst() 返回第一个元素
findAny() 返回当前流中的任意元素
count() 返回流中元素总数
max(Comparator c) 返回流中最大值
min(Comparator c) 返回流中最小值
forEach(Consumer c) 内部迭代(使用 Collection 接口需要用户去做迭代,称为外部迭代。
2-归约
方法 描述
reduce(T identity, BinaryOperator b) 可以将流中元素反复结合起来,得到一个值。返回 T
reduce(BinaryOperator b) 可以将流中元素反复结合起来,得到一个值。返回 Optional
备注:map 和 reduce 的连接通常称为 map-reduce 模式,因 Google 用它来进行网络搜索而出名。
3-收集
方 法 描 述
collect(Collector c) 将流转换为其他形式。接收一个 Collector接口的实现,
Collector 接口中方法的实现决定了如何对流执行收集的操作(如收集到 List、Set、Map)。
另外, Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例,具体方法与实例如下表:
方法 返回类型 作用
toList Collector<T, ?, List>
把流中元素收集到List
1 List<Employee> emps= list.stream().collect(Collectors.toList());
方法 返回类型 作用
toSet Collector<T, ?, Set>
把流中元素收集到Set
1 Set<Employee> emps= list.stream().collect(Collectors.toSet());
方法 返回类型 作用
toCollection Collector<T, ?, C>
把流中元素收集到创建的集合
1 Collection<Employee> emps =list.stream().collect(Collectors.toCollection(ArrayList::new ));
方法 返回类型 作用
counting Collector<T, ?, Long>
计算流中元素的个数
1 long count = list.stream().collect(Collectors.counting());
方法 返回类型 作用
summingInt Collector<T, ?, Integer>
对流中元素的整数属性求和
1 int total=list.stream().collect(Collectors.summingInt(Employee::getSalary));
方法 返回类型 作用
averagingInt Collector<T, ?, Double>
计算流中元素Integer属性的平均值
1 double avg = list.stream().collect(Collectors.averagingInt(Employee::getSalary));
方法 返回类型 作用
summarizingInt Collector<T, ?, IntSummaryStatistics>
收集流中Integer属性的统计值。如:平均值
1 int SummaryStatisticsiss= list.stream().collect(Collectors.summarizingInt(Employee::getSalary));
方法 返回类型 作用
joining Collector<CharSequence, ?, String>
连接流中每个字符串
1 String str= list.stream().map(Employee::getName).collect(Collectors.joining());
方法 返回类型 作用
maxBy Collector<T, ?, Optional>
根据比较器选择最大值
1 Optional<Emp>max= list.stream().collect(Collectors.maxBy(comparingInt(Employee::getSalary)));
方法 返回类型 作用
minBy Collector<T, ?, Optional>
根据比较器选择最小值
1 Optional<Emp> min = list.stream().collect(Collectors.minBy(comparingInt(Employee::getSalary)));
方法 返回类型 作用
reducing Collector<T, ?, Optional>
从一个作为累加器的初始值开始,利用BinaryOperator与流中元素逐个结合,从而归约成单个值
1 int total=list.stream().collect(Collectors.reducing(0 , Employee::getSalar, Integer::sum));
方法 返回类型 作用
collectingAndThen Collector<T,A,RR>
包裹另一个收集器,对其结果转换函数
1 int how= list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size));
方法 返回类型 作用
groupingBy Collector<T, ?, Map<K, List>>
根据某属性值对流分组,属性为K,结果为V
1 Map<Emp.Status, List<Emp>> map= list.stream().collect(Collectors.groupingBy(Employee::getStatus));
方法 返回类型 作用
partitioningBy Collector<T, ?, Map<Boolean, List>>
根据true或false进行分区
Java9新增API 新增1:Stream实例化方法
ofNullable()的使用:
Java 8 中 Stream 不能完全为null,否则会报空指针异常。而 Java 9 中的 ofNullable 方法允许我们创建一个单元素 Stream,可以包含一个非空元素,也可以创建一个空 Stream。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 Stream<String> stringStream = Stream.of("AA" , "BB" , null ); System.out.println(stringStream.count()); List<String> list = new ArrayList <>(); list.add("AA" ); list.add(null ); System.out.println(list.stream().count()); Stream<Object> stream1 = Stream.ofNullable(null ); System.out.println(stream1.count()); Stream<String> stream = Stream.ofNullable("hello world" ); System.out.println(stream.count());
iterator()重载的使用:
1 2 3 4 5 6 Stream.iterate(1 ,i -> i + 1 ).limit(10 ).forEach(System.out::println); Stream.iterate(1 ,i -> i < 100 ,i -> i + 1 ).forEach(System.out::println);
新语法结构 新的语法结构,为我们勾勒出了 Java 语法进化的一个趋势,将开发者从复杂、繁琐的低层次抽象中逐渐解放出来,以更高层次、更优雅的抽象,既降低代码量,又避免意外编程错误的出现,进而提高代码质量和开发效率。
Java的REPL工具: jShell命令 利用jShell在没有创建类的情况下,在命令行里直接声明变量,计算表达式,执行语句。无需跟人解释”public static void main(String[] args)”这句”废话”。
异常处理之try-catch资源关闭 在JDK7 之前,我们这样处理资源的关闭:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 @Test public void test01 () { FileWriter fw = null ; BufferedWriter bw = null ; try { fw = new FileWriter ("d:/1.txt" ); bw = new BufferedWriter (fw); bw.write("hello" ); } catch (IOException e) { e.printStackTrace(); } finally { try { if (bw != null ) { bw.close(); } } catch (IOException e) { e.printStackTrace(); } try { if (fw != null ) { fw.close(); } } catch (IOException e) { e.printStackTrace(); } } }
JDK7的新特性
在try的后面可以增加一个(),在括号中可以声明流对象并初始化。try中的代码执行完毕,会自动把流对象释放,就不用写finally了。
格式:
1 2 3 4 5 6 7 try (资源对象的声明和初始化){ 业务逻辑代码,可能会产生异常 }catch (异常类型1 e){ 处理异常代码 }catch (异常类型2 e){ 处理异常代码 }
说明:
1、在try()中声明的资源,无论是否发生异常,无论是否处理异常,都会自动关闭资源对象,不用手动关闭了。
2、这些资源实现类必须实现AutoCloseable或Closeable接口,实现其中的close()方法。Closeable是AutoCloseable的子接口。Java7几乎把所有的“资源类”(包括文件IO的各种类、JDBC编程的Connection、Statement等接口…)都进行了改写,改写后资源类都实现了AutoCloseable或Closeable接口,并实现了close()方法。
3、写到try()中的资源类的变量默认是final声明的,不能修改。
举例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 @Test public void test02 () { try ( FileWriter fw = new FileWriter ("d:/1.txt" ); BufferedWriter bw = new BufferedWriter (fw); ) { bw.write("hello" ); } catch (IOException e) { e.printStackTrace(); } } @Test public void test03 () { try ( FileInputStream fis = new FileInputStream ("d:/1.txt" ); InputStreamReader isr = new InputStreamReader (fis, "utf-8" ); BufferedReader br = new BufferedReader (isr); FileOutputStream fos = new FileOutputStream ("1.txt" ); OutputStreamWriter osw = new OutputStreamWriter (fos, "gbk" ); BufferedWriter bw = new BufferedWriter (osw); ) { String str; while ((str = br.readLine()) != null ) { bw.write(str); bw.newLine(); } } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }
JDK9的新特性
try的前面可以定义流对象,try后面的()中可以直接引用流对象的名称。在try代码执行完毕后,流对象也可以释放掉,也不用写finally了。
格式:
1 2 3 4 5 6 7 A a = new A ();B b = new B ();try (a;b){ 可能产生的异常代码 }catch (异常类名 变量名){ 异常处理的逻辑 }
举例:
1 2 3 4 5 6 7 8 9 10 11 12 @Test public void test04 () { InputStreamReader reader = new InputStreamReader (System.in); OutputStreamWriter writer = new OutputStreamWriter (System.out); try (reader; writer) { } catch (IOException e) { e.printStackTrace(); } }
局部变量类型推断 JDK 10的新特性
局部变量的显示类型声明,常常被认为是不必须的,给一个好听的名字反而可以很清楚的表达出下面应该怎样继续。本新特性允许开发人员省略通常不必要的局部变量类型声明,以增强Java语言的体验性、可读性。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 var list = new ArrayList <String>();var set = new LinkedHashSet <Integer>();for (var v : list) { System.out.println(v); } for (var i = 0 ; i < 100 ; i++) { System.out.println(i); } var iterator = set.iterator();
不适用场景
声明一个成员变量
声明一个数组变量,并为数组静态初始化(省略new的情况下)
方法的返回值类型
方法的参数类型
没有初始化的方法内的局部变量声明
作为catch块中异常类型
Lambda表达式中函数式接口的类型
方法引用中函数式接口的类型
注意:
instanceof的模式匹配 JDK14中预览特性:
instanceof 模式匹配通过提供更为简便的语法,来提高生产力。有了该功能,可以减少Java程序中显式强制转换的数量,实现更精确、简洁的类型安全的代码。
Java 14之前旧写法:
1 2 3 4 5 6 if (obj instanceof String){ String str = (String)obj; .. str.contains(..).. }else { ... }
Java 14新特性写法:
1 2 3 4 5 if (obj instanceof String str){ .. str.contains(..).. }else { ... }
JDK15中第二次预览:
没有任何更改。
JDK16中转正特性:
在Java16中转正。
switch表达式 传统switch声明语句的弊端:
匹配是自上而下的,如果忘记写break,后面的case语句不论匹配与否都会执行; —>case穿透
所有的case语句共用一个块范围,在不同的case语句定义的变量名不能重复;
不能在一个case里写多个执行结果一致的条件;
整个switch不能作为表达式返回值;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 switch (month){ case 3 |4 |5 : System.out.println("春季" ); break ; case 6 |7 |8 : System.out.println("夏季" ); break ; case 9 |10 |11 : System.out.println("秋季" ); break ; case 12 |1 |2 : System.out.println("冬季" ); break ; default : System.out.println("输入有误" ); }
JDK12中预览特性:
Java 12将会对switch声明语句进行扩展,使用case L ->来替代以前的break;,省去了 break 语句,避免了因少写 break 而出错。
同时将多个 case 合并到一行,显得简洁、清晰,也更加优雅的表达逻辑分支。
为了保持兼容性,case 条件语句中依然可以使用字符 : ,但是同一个 switch 结构里不能混用 -> 和 : ,否则编译错误。
1 2 3 4 5 6 7 8 9 10 11 public class SwitchTest1 { public static void main (String[] args) { Fruit fruit = Fruit.GRAPE; switch (fruit){ case PEAR -> System.out.println(4 ); case APPLE,MANGO,GRAPE -> System.out.println(5 ); case ORANGE,PAPAYA -> System.out.println(6 ); default -> throw new IllegalStateException ("No Such Fruit:" + fruit); }; } }
更进一步:
1 2 3 4 5 6 7 8 9 10 11 12 public class SwitchTest2 { public static void main (String[] args) { Fruit fruit = Fruit.GRAPE; int numberOfLetters = switch (fruit){ case PEAR -> 4 ; case APPLE,MANGO,GRAPE -> 5 ; case ORANGE,PAPAYA -> 6 ; default -> throw new IllegalStateException ("No Such Fruit:" + fruit); }; System.out.println(numberOfLetters); } }
JDK13中二次预览特性:
JDK13中引入了yield语句,用于返回值。这意味着,switch表达式(返回值)应该使用yield,switch语句(不返回值)应该使用break。
yield和return的区别在于:return会直接跳出当前循环或者方法,而yield只会跳出当前switch块。
1 2 3 4 5 6 7 8 9 10 11 12 13 @Test public void testSwitch3 () { String x = "3" ; int i = switch (x) { case "1" : yield 1 ; case "2" : yield 2 ; default : yield 3 ; }; System.out.println(i); }
JDK14中转正特性:
这是JDK 12和JDK 13中的预览特性,现在是正式特性了。
JDK17的预览特性:switch的模式匹配
旧写法:
1 2 3 4 5 6 7 8 9 10 11 12 13 static String formatter (Object o) { String formatted = "unknown" ; if (o instanceof Integer i) { formatted = String.format("int %d" , i); } else if (o instanceof Long l) { formatted = String.format("long %d" , l); } else if (o instanceof Double d) { formatted = String.format("double %f" , d); } else if (o instanceof String s) { formatted = String.format("String %s" , s); } return formatted; }
模式匹配新写法:
1 2 3 4 5 6 7 8 9 static String formatterPatternSwitch (Object o) { return switch (o) { case Integer i -> String.format("int %d" , i); case Long l -> String.format("long %d" , l); case Double d -> String.format("double %f" , d); case String s -> String.format("String %s" , s); default -> o.toString(); }; }
直接在 switch 上支持 Object 类型,这就等于同时支持多种类型,使用模式匹配得到具体类型,大大简化了语法量,这个功能很实用。
文本块 现实问题:
在Java中,通常需要使用String类型表达HTML,XML,SQL或JSON等格式的字符串,在进行字符串赋值时需要进行转义和连接操作,然后才能编译该代码,这种表达方式难以阅读并且难以维护。
JDK13的新特性
使用”””作为文本块的开始符和结束符,在其中就可以放置多行的字符串,不需要进行任何转义。因此,文本块将提高Java程序的可读性和可写性。
基本使用:
1 2 3 4 5 """ line1 line2 line3 """
相当于:
或者一个连接的字符串:
1 2 3 "line1\n" +"line2\n" +"line3\n"
如果字符串末尾不需要行终止符,则结束分隔符可以放在最后一行内容上。例如:
1 2 3 4 """ line1 line2 line3"""
相当于
文本块可以表示空字符串,但不建议这样做,因为它需要两行源代码:
JDK14中二次预览特性
JDK14的版本主要增加了两个escape sequences,分别是 \ <line-terminator>与\s escape sequence。
JDK15中功能转正
Record 背景
早在2019年2月份,Java 语言架构师 Brian Goetz,曾写文抱怨“Java太啰嗦”或有太多的“繁文缛节”。他提到:开发人员想要创建纯数据载体类(plain data carriers)通常都必须编写大量低价值、重复的、容易出错的代码。如:构造函数、getter/setter、equals()、hashCode()以及toString()等。
以至于很多人选择使用IDE的功能来自动生成这些代码。还有一些开发会选择使用一些第三方类库,如Lombok等来生成这些方法。
JDK14中预览特性:神说要用record,于是就有了。 实现一个简单的数据载体类,为了避免编写:构造函数,访问器,equals(),hashCode () ,toString ()等,Java 14推出record。
record 是一种全新的类型,它本质上是一个 final 类,同时所有的属性都是 final 修饰,它会自动编译出 public get 、hashcode 、equals、toString、构造器等结构,减少了代码编写量。
具体来说:当你用record 声明一个类时,该类将自动拥有以下功能:
获取成员变量的简单方法,比如例题中的 name() 和 partner() 。注意区别于我们平常getter()的写法。
一个 equals 方法的实现,执行比较时会比较该类的所有成员属性。
重写 hashCode() 方法。
一个可以打印该类所有成员属性的 toString() 方法。
只有一个构造方法。
此外:
举例1(新写法):
1 record Point (int x, int y) { }
JDK15中第二次预览特性
JDK16中转正特性
最终到JDK16中转正。
记录不适合哪些场景
record的设计目标是提供一种将数据建模为数据的好方法。它也不是 JavaBeans 的直接替代品,因为record的方法不符合 JavaBeans 的 get 标准。另外 JavaBeans 通常是可变的,而记录是不可变的。尽管它们的用途有点像,但记录并不会以某种方式取代 JavaBean。
密封类 背景:
在 Java 中如果想让一个类不能被继承和修改,这时我们应该使用 final 关键字对类进行修饰。不过这种要么可以继承,要么不能继承的机制不够灵活,有些时候我们可能想让某个类可以被某些类型继承,但是又不能随意继承,是做不到的。Java 15 尝试解决这个问题,引入了 sealed 类,被 sealed 修饰的类可以指定子类。这样这个类就只能被指定的类继承。
JDK15的预览特性:
通过密封的类和接口来限制超类的使用,密封的类和接口限制其它可能继承或实现它们的其它类或接口。
具体使用:
JDK16二次预览特性
JDK17中转正特性
API的变化 Optional 类 JDK8的新特性
到目前为止,臭名昭著的空指针异常是导致Java应用程序失败的最常见原因。以前,为了解决空指针异常,Google在著名的Guava项目引入了Optional类,通过检查空值的方式避免空指针异常。受到Google的启发,Optional类已经成为Java 8类库的一部分。
Optional<T> 类(java.util.Optional) 是一个容器类,它可以保存类型T的值,代表这个值存在。或者仅仅保存null,表示这个值不存在。如果值存在,则isPresent()方法会返回true,调用get()方法会返回该对象。
Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
创建Optional类对象的方法:
static Optional empty() :用来创建一个空的Optional实例
static Optional of(T value) :用来创建一个Optional实例,value必须非空
static <T> Optional<T> ofNullable(T value) :用来创建一个Optional实例,value可能是空,也可能非空
判断Optional容器中是否包含对象:
boolean isPresent() : 判断Optional容器中的值是否存在
void ifPresent(Consumer<? super T> consumer) :判断Optional容器中的值是否存在,如果存在,就对它进行Consumer指定的操作,如果不存在就不做
获取Optional容器的对象:
T get(): 如果调用对象包含值,返回该值。否则抛异常。T get()与of(T value)配合使用
T orElse(T other) :orElse(T other) 与ofNullable(T value)配合使用,如果Optional容器中非空,就返回所包装值,如果为空,就用orElse(T other)other指定的默认值(备胎)代替
T orElseGet(Supplier<? extends T> other) :如果Optional容器中非空,就返回所包装值,如果为空,就用Supplier接口的Lambda表达式提供的值代替
T orElseThrow(Supplier<? extends X> exceptionSupplier) :如果Optional容器中非空,就返回所包装值,如果为空,就抛出你指定的异常类型代替原来的NoSuchElementException
这是JDK9-11的新特性
新增方法 描述 新增的版本
boolean isEmpty()
判断value是否为空
JDK 11
ifPresentOrElse(Consumer<? super T> action, Runnable emptyAction)
value非空,执行参数1功能;如果value为空,执行参数2功能
JDK 9
Optional or(Supplier<? extends Optional<? extends T>> supplier)
value非空,返回对应的Optional;value为空,返回形参封装的Optional
JDK 9
Stream stream()
value非空,返回仅包含此value的Stream;否则,返回一个空的Stream
JDK 9
T orElseThrow()
value非空,返回value;否则抛异常NoSuchElementException
JDK 10
String存储结构和API变更 这是JDK9的新特性。
产生背景:
Motivation
使用说明:
Description We propose to change the internal representation of the String class from a UTF-16 char array to a byte array plus an encoding-flag field. The new String class will store characters encoded either as ISO-8859-1/Latin-1 (one byte per character), or as UTF-16 (two bytes per character), based upon the contents of the string. The encoding flag will indicate which encoding is used.
结论:String 再也不用 char[] 来存储啦,改成了 byte[] 加上编码标记,节约了一些空间。
1 2 3 4 5 6 public final class String implements java .io.Serializable, Comparable<String>, CharSequence { @Stable private final byte [] value; ... }
拓展:StringBuffer 与 StringBuilder
那StringBuffer 和 StringBuilder 是否仍无动于衷呢?
String-related classes such as AbstractStringBuilder, StringBuilder, and StringBuffer will be updated to use the same representation, as will the HotSpot VM’s intrinsic string operations.
JDK11新特性:新增了一系列字符串处理方法
描述 举例
判断字符串是否为空白
“ “.isBlank(); // true
去除首尾空白
“ Javastack “.strip(); // “Javastack”
去除尾部空格
“ Javastack “.stripTrailing(); // “ Javastack”
去除首部空格
“ Javastack “.stripLeading(); // “Javastack “
复制字符串
“Java”.repeat(3);// “JavaJavaJava”
行数统计
“A\nB\nC”.lines().count(); // 3
JDK12新特性:String 实现了 Constable 接口
String源码:
1 public final class String implements java .io.Serializable, Comparable<String>, CharSequence,Constable, ConstantDesc {
java.lang.constant.Constable接口定义了抽象方法:
1 2 3 public interface Constable { Optional<? extends ConstantDesc > describeConstable(); }
Java 12 String 的实现源码:
1 2 3 4 5 6 7 8 9 10 11 @Override public Optional<String> describeConstable () { return Optional.of(this ); }
很简单,其实就是调用 Optional.of 方法返回一个 Optional 类型。
举例:
1 2 3 4 5 private static void testDescribeConstable () { String name = "尚硅谷Java高级工程师" ; Optional<String> optional = name.describeConstable(); System.out.println(optional.get()); }
结果输出:
JDK12新特性:String新增方法
String的transform(Function)
1 2 var result = "foo" .transform(input -> input + " bar" );System.out.println(result);
或者
1 2 var result = "foo" .transform(input -> input + " bar" ).transform(String::toUpperCase)System.out.println(result);
对应的源码:
1 2 3 4 5 6 7 8 9 public <R> R transform (Function<? super String, ? extends R> f) { return f.apply(this ); }
在某种情况下,该方法应该被称为map()。
举例:
1 2 3 4 5 6 7 8 9 10 private static void testTransform () { System.out.println("======test java 12 transform======" ); List<String> list1 = List.of("Java" , " Python" , " C++ " ); List<String> list2 = new ArrayList <>(); list1.forEach(element -> list2.add(element.transform(String::strip) .transform(String::toUpperCase) .transform((e) -> "Hi," + e)) ); list2.forEach(System.out::println); }
结果输出:
1 2 3 4 ======test java 12 transform====== Hi,JAVA Hi,PYTHON Hi,C++
如果使用Java 8的Stream特性,可以如下实现:
1 2 3 4 5 6 7 8 private static void testTransform1 () { System.out.println("======test before java 12 ======" ); List<String> list1 = List.of("Java " , " Python" , " C++ " ); Stream<String> stringStream = list1.stream().map(element -> element.strip()).map(String::toUpperCase).map(element -> "Hello," + element); List<String> list2 = stringStream.collect(Collectors.toList()); list2.forEach(System.out::println); }
JDK17:标记删除Applet API Applet API 提供了一种将 Java AWT/Swing 控件嵌入到浏览器网页中的方法。不过,目前 Applet 已经被淘汰。大部分人可能压根就没有用过 Applet。
Applet API 实际上是无用的,因为所有 Web 浏览器供应商都已删除或透露计划放弃对 Java 浏览器插件的支持。Java 9 的时候,Applet API 已经被标记为过时,Java 17 的时候终于标记为删除了。
具体如下:
1 2 3 4 5 6 java.applet.Applet java.applet.AppletStub java.applet.AppletContext java.applet.AudioClip javax.swing.JApplet java.beans.AppletInitializer
其它结构变化 JDK9:UnderScore(下划线)使用的限制 在java 8 中,标识符可以独立使用“_”来命名:
1 2 String _ = "hello" ;System.out.println(_);
但是,在java 9 中规定“_”不再可以单独命名标识符了,如果使用,会报错
JDK11:更简化的编译运行程序 看下面的代码。
1 2 3 4 5 javac JavaStack.java java JavaStack
我们的认知里,要运行一个 Java 源代码必须先编译,再运行。而在 Java 11 版本中,通过一个 java 命令就直接搞定了,如下所示:
注意点:
GC方面新特性 GC是Java主要优势之一。 然而,当GC停顿太长,就会开始影响应用的响应时间。随着现代系统中内存不断增长,用户和程序员希望JVM能够以高效的方式充分利用这些内存, 并且无需长时间的GC暂停时间。
G1 GC JDK9以后默认的垃圾回收器是G1GC。
JDK10 : 为G1提供并行的Full GC
G1最大的亮点就是可以尽量的避免full gc。但毕竟是“尽量”,在有些情况下,G1就要进行full gc了,比如如果它无法足够快的回收内存的时候,它就会强制停止所有的应用线程然后清理。
在Java10之前,一个单线程版的标记-清除-压缩算法被用于full gc。为了尽量减少full gc带来的影响,在Java10中,就把之前的那个单线程版的标记-清除-压缩的full gc算法改成了支持多个线程同时full gc。这样也算是减少了full gc所带来的停顿,从而提高性能。
你可以通过-XX:ParallelGCThreads参数来指定用于并行GC的线程数。
JDK12:可中断的 G1 Mixed GC
JDK12:增强G1,自动返回未用堆内存给操作系统
Shenandoah GC JDK12:Shenandoah GC:低停顿时间的GC
Shenandoah 垃圾回收器是 Red Hat 在 2014 年宣布进行的一项垃圾收集器研究项目 Pauseless GC 的实现,旨在针对 JVM 上的内存收回实现低停顿的需求 。
据 Red Hat 研发 Shenandoah 团队对外宣称,Shenandoah 垃圾回收器的暂停时间与堆大小无关,这意味着无论将堆设置为 200 MB 还是 200 GB,都将拥有一致的系统暂停时间,不过实际使用性能将取决于实际工作堆的大小和工作负载。
Shenandoah GC 主要目标是 99.9% 的暂停小于 10ms,暂停与堆大小无关等。
这是一个实验性功能,不包含在默认(Oracle)的OpenJDK版本中。
Shenandoah开发团队在实际应用中的测试数据:
JDK15:Shenandoah垃圾回收算法转正
Shenandoah垃圾回收算法终于从实验特性转变为产品特性,这是一个从 JDK 12 引入的回收算法,该算法通过与正在运行的 Java 线程同时进行疏散工作来减少 GC 暂停时间。Shenandoah 的暂停时间与堆大小无关,无论堆栈是 200 MB 还是 200 GB,都具有相同的一致暂停时间。
Shenandoah在JDK12被作为experimental引入,在JDK15变为Production;之前需要通过-XX:+UnlockExperimentalVMOptions -XX:+UseShenandoahGC来启用,现在只需要-XX:+UseShenandoahGC即可启用
革命性的 ZGC JDK11:引入革命性的 ZGC
ZGC,这应该是JDK11最为瞩目的特性,没有之一。
ZGC是一个并发、基于region、压缩型的垃圾收集器。
ZGC的设计目标是:支持TB级内存容量,暂停时间低(<10ms),对整个程序吞吐量的影响小于15%。 将来还可以扩展实现机制,以支持不少令人兴奋的功能,例如多层堆(即热对象置于DRAM和冷对象置于NVMe闪存),或压缩堆。
JDK13:ZGC:将未使用的堆内存归还给操作系统
JDK14:ZGC on macOS和windows
JDK15:ZGC 功能转正
ZGC是Java 11引入的新的垃圾收集器,经过了多个实验阶段,自此终于成为正式特性。
但是这并不是替换默认的GC,默认的GC仍然还是G1;之前需要通过-XX:+UnlockExperimentalVMOptions、 -XX:+UseZGC来启用ZGC,现在只需要-XX:+UseZGC就可以。相信不久的将来它必将成为默认的垃圾回收器。
ZGC的性能已经相当亮眼,用“令人震惊、革命性”来形容,不为过。未来将成为服务端、大内存、低延迟应用的首选垃圾收集器。
怎么形容Shenandoah和ZGC的关系呢?异同点大概如下:
相同点:性能几乎可认为是相同的
不同点:ZGC是Oracle JDK的,根正苗红。而Shenandoah只存在于OpenJDK中,因此使用时需注意你的JDK版本
JDK16:ZGC 并发线程处理
在线程的堆栈处理过程中,总有一个制约因素就是safepoints。在safepoints这个点,Java的线程是要暂停执行的,从而限制了GC的效率。
回顾:
我们都知道,在之前,需要 GC 的时候,为了进行垃圾回收,需要所有的线程都暂停下来,这个暂停的时间我们称为 Stop The World 。
而为了实现 STW 这个操作, JVM 需要为每个线程选择一个点停止运行,这个点就叫做安全点(Safepoints) 。
而ZGC的并发线程堆栈处理可以保证Java线程可以在GC safepoints的同时可以并发执行。它有助于提高所开发的Java软件应用程序的性能和效率。
企业真题(十八) 1. JDK新特性的概述
几个重要的版本
jdk 5.0 / jdk 8.0 :里程碑式的版本
jdk9.0 开始每6个月发布一个新的版本
LTS : jdk8 、 jdk 11 、 jdk 17
如何学习新特性
1 2 3 4 5 6 7 > 角度1:新的语法规则 (多关注) 自动装箱、自动拆箱、注解、enum、Lambda表达式、方法引用、switch表达式、try-catch变化、record等 > 角度2:增加、过时、删除API StringBuilder、ArrayList、新的日期时间的API、Optional等 > 角度3:底层的优化、JVM参数的调整、GC的变化、内存结构(永久代--->元空间)
2. JDK8:lambda表达式 2.1 什么情况下可以使用lambda表达式
在给函数式接口提供实例时,都可以考虑使用lambda表达式。
基本语法的使用(重要)
2.2 函数式接口
2.3 方法引用、构造器引用、数组引用
3. JDK8:Stream API的使用
Stream关注于内存中的多个数据的运算。
使用步骤:① Stream 的实例化 ② 一系列的中间操作 ③ 终止操作
4. JDK8之后的新特性:语法层面
jShell工具
try-catch结构的变化。try(…){ }
局部变量的类型推断:var
instanceof的模式匹配
switch表达式、switch的模式匹配
文本块的使用:”””文本块”””
新的引用数据类型:record (记录)
密封类:sealed class
5. JDK8之后的新特性:其它
二、企业真题 JDK8新特性 1. 谈谈java8新特性(京*旗下、时代*宇,信必*、招*信诺,中*外包,金*软件、阿**巴) 1 2 3 类似问题 > JDK1.8相较于JDK1.7有什么不一样?(惠*) > JDK1.8的新特性有哪些?Stream API + Lambda表达式,还有吗?(久*国际物流)
lambda表达式、Stream API
jdk7的对比:元空间、HashMap、新的日期时间API、接口变化等。
2. JDK1.8在数据结构上发生了哪些变化 ?(银*数据)
使用元空间替代永久代。 (方法区:jvm规范中提到的结构。
HotSpot来讲,jdk7:方法区的落地体现:永久代。 jdk8:方法区的落地体现:元空间。
HashMap底层结构
3. 你说的了解 Java的新特性 ,你说说JDK8改进的地方?(银*科技) 略
4. JDK1.8用的是哪个垃圾回收器?(O**O) Parallel GC –> jdk9:默认使用G1GC –> ZGC (低延迟)
Lambda表达式 1. Lambda表达式有了解吗,说说如何使用的(O**O) 略
2. 什么是函数式接口?有几种函数式接口(阿**巴) 略。
java.util.function包下定义了丰富的好函数式接口。有4类基础的函数式接口:
消费型接口:Consumer void accept(T t) T get() boolean test(T t)
Stream API 1. 创建Stream的方式(阿**巴) 三种。
2. 你讲讲stream表达式是咋用的,干啥的?(中*国际,上海**网络) 1 2 3 > Stream API 关注的是多个数据的计算(排序、查找、过滤、映射、遍历等),面向CPU的。 集合关注的数据的存储,面向内存的。 > Stream API 之于集合,类似于SQL之于数据表的查询。
3. 集合用Stream流怎么实现过滤?(润*软件) filter(Predicate predicate)
4. 用Stream怎么选出List里想要的数据?(惠*) 略
其它版本新特性 1. 说说JDK15、JDK16、JDK17中的新特性都有什么?(银*数据) 略
IDEA的日常快捷键和Debug 第1组:通用型
说明
快捷键
复制代码-copy
ctrl + c
粘贴-paste
ctrl + v
剪切-cut
ctrl + x
撤销-undo
ctrl + z
反撤销-redo
ctrl + shift + z
保存-save all
ctrl + s
全选-select all
ctrl + a
第2组:提高编写速度(上)
说明
快捷键
智能提示-edit
alt + enter
提示代码模板-insert live template
ctrl+j
使用xx块环绕-surround with …
ctrl+alt+t
调出生成getter/setter/构造器等结构-generate …
alt+insert
自动生成返回值变量-introduce variable …
ctrl+alt+v
复制指定行的代码-duplicate line or selection
ctrl+d
删除指定行的代码-delete line
ctrl+y
切换到下一行代码空位-start new line
shift + enter
切换到上一行代码空位-start new line before current
ctrl +alt+ enter
向上移动代码-move statement up
ctrl+shift+↑
向下移动代码-move statement down
ctrl+shift+↓
向上移动一行-move line up
alt+shift+↑
向下移动一行-move line down
alt+shift+↓
方法的形参列表提醒-parameter info
ctrl+p
第3组:提高编写速度(下)
说明
快捷键
批量修改指定的变量名、方法名、类名等-rename
shift+f6
抽取代码重构方法-extract method …
ctrl+alt+m
重写父类的方法-override methods …
ctrl+o
实现接口的方法-implements methods …
ctrl+i
选中的结构的大小写的切换-toggle case
ctrl+shift+u
批量导包-optimize imports
ctrl+alt+o
第4组:类结构、查找和查看源码
说明
快捷键
如何查看源码-go to class…
ctrl + 选中指定的结构 或 ctrl+n
显示当前类结构,支持搜索指定的方法、属性等-file structure
ctrl+f12
退回到前一个编辑的页面-back
ctrl+alt+←
进入到下一个编辑的页面-forward
ctrl+alt+→
打开的类文件之间切换-select previous/next tab
alt+←/→
光标选中指定的类,查看继承树结构-Type Hierarchy
ctrl+h
查看方法文档-quick documentation
ctrl+q
类的UML关系图-show uml popup
ctrl+alt+u
定位某行-go to line/column
ctrl+g
回溯变量或方法的来源-go to implementation(s)
ctrl+alt+b
折叠方法实现-collapse all
ctrl+shift+ -
展开方法实现-expand all
ctrl+shift+ +
第5组:查找、替换与关闭
说明
快捷键
查找指定的结构
ctlr+f
快速查找:选中的Word快速定位到下一个-find next
ctrl+l
查找与替换-replace
ctrl+r
直接定位到当前行的首位-move caret to line start
home
直接定位到当前行的末位 -move caret to line end
end
查询当前元素在当前文件中的引用,然后按 F3 可以选择
ctrl+f7
全项目搜索文本-find in path …
ctrl+shift+f
关闭当前窗口-close
ctrl+f4
第6组:调整格式
说明
快捷键
格式化代码-reformat code
ctrl+alt+l
使用单行注释-comment with line comment
ctrl + /
使用/取消多行注释-comment with block comment
ctrl + shift + /
选中数行,整体往后移动-tab
tab
选中数行,整体往前移动-prev tab
shift + tab
Debug快捷键
说明
快捷键
单步调试(不进入函数内部)- step over
F8
单步调试(进入函数内部)- step into
F7
强制单步调试(进入函数内部) - force step into
alt+shift+f7
选择要进入的函数 - smart step into
shift + F7
跳出函数 - step out
shift + F8
运行到断点 - run to cursor
alt + F9
继续执行,进入下一个断点或执行完程序 - resume program
F9
停止 - stop
Ctrl+F2
查看断点 - view breakpoints
Ctrl+Shift+F8
关闭 - close
Ctrl+F4
面试题整理
Original link: http://example.com/page/2/index.html
Copyright Notice: 转载请注明出处.